Appearance
基础
Java 语言的特性有哪些?
- Java 生态丰富
- 平台无关性
- 面向对象:继承、封装、多态
面向对象与面向过程
- 面向对象
- 将具体的事务抽象,封装其中的行为方法,进行实现的一种方式
- 面向过程
- 顺序执行,按照步骤处理
Java 的基本数据类型
- 基本数据类型 默认占用空间 默认值 包装类型 取值范围
- byte 1字节 0 Byte -128-127
- char 2字节 '\u0000' Character
- short 2字节 0 Short
- int 4字节 0 Integer
- long 8字节 0L Long
- float 4字节 0.0f Float
- double 8 字节 0.0d Double
- boolean 1字节 false Boolean
什么下会使用包装类,自动拆装箱了解吗,常量池技术是否清楚。
值传递和引用传递
- 值传递
- 是对基本数据类型⽽⾔,只进⾏值的拷⻉,不会影响原变量
- 引用传递
- 对对象⽽⾔,不是传递对象的值,⽽是传递对象的地址, 如果副本改变会影响到原对象
String 为什么是不可变的
final、finally、finalize 的区别
String、StringBuffer、StringBuilder 的区别
包装类型的常量池技术了解吗。
- 常量池技术是包装类型的一种缓存技术,能够减少对象的创建和内存使用,当数据的值在一个范围中,比如 Integer 对应的创建值在 -128 - 127;那么这个时候 Java 会从常量池中返回已存在的对象而不是创建一个新的对象。
包装类型和基础数据类型的区别
- 为什么要有包装类型
- 包装类型是对象类型,能够在Java 使用一些对象特性,比如参与到集合类、泛型、序列化等
- 另外包装类型是允许空值的,他在一些场景下用于区分“无数据”和“零值”时 是非常有用的;
- 区别
- 内存分配不同:基础数据类型 → 栈;包装类型 → 堆;
- 默认值不同:比如 int → 0; Integer → null
- 内存占用、使用场景、性能会有一些差别。
自动拆装箱的原理
- 自动拆装箱
- 自动拆箱:将 包装类 自动转换为基本数据类型
- 自动装箱:将 基本数据类型 转换为 包装类
- 原理
- 装箱:通过调用包装类的 valueOf 方法
- 拆箱:通过调用包装类的 xxxValue 方法
遇到过自动拆箱引发的 NPE 问题吗
- 什么情况下遇到:当 包装类型的引用为
null,自动拆箱会触发 NPE - 解决:尽量使用空值或者默认值的方式避免
switch case 支持哪几种数据类型
- 整数类型、枚举类型、字符串
什么是值传递和引⽤传递
- 值传递是对基本数据类型⽽⾔,只进⾏值的拷⻉,不会影响原变量
- 引⽤传递是对对象⽽⾔,不是传递对象的值,⽽是传递对象的地址, 如果副本改变会影响到原对象
final、finally、finalize的区别
- final修饰的类不能被继承、属性是常量⽽且必须初始化、修饰的⽅法 不能被重写
- finally⽤于异常处理,finally代码块中的内容⼀定会执⾏
- finalize是Object类的⼀个⽅法,当我们调⽤system.gc()时会调⽤,也 可以使⽤它在GC时⾃救⼀次
- 重写finalize⽅法的对象会被加⼊到⼀个 unfinalized 链表中,⾸次 GC时不会回收该对象,调⽤完finalize后,然后从unfinalized链表 剔除,此时对象可以进⾏⾃救,将⾃⼰重新加⼊到引⽤链上,下 ⼀次GC时会进⾏回收
关于对 finialize 的解释:
Java中finalize()方法的工作原理以及 finalize 方法 与垃圾回收(GC)过程的关系
finalize()方法是java.lang.Object类的一个方法,Java允许子类重写这个方法,以实现资源的清理工作,比如关闭文件句柄或者释放网络资源等。- 不过,需要注意的是,从Java 9开始,
finalize()方法已被标记为废弃(deprecated),因为它的使用是不推荐的,主要因为它的不确定性、低效率和可能导致的内存泄露问题。
以下是finalize()方法工作机制的详细解释:
- 重写
finalize()方法的对象被加入到一个unfinalized链表中:当一个对象重写了finalize()方法,且该对象变成了垃圾(即没有任何强引用指向它),JVM就会将这个对象加入到一个专门的列表(称为unfinalized链表)中。这意味着,尽管这个对象已经没有被任何强引用指向,但因为重写了finalize()方法,它在第一次垃圾回收时不会立即被清理。 - 首次GC时不会回收该对象:当垃圾回收器运行时,它会检测到
unfinalized链表中的对象。对于这些对象,垃圾回收器不会直接回收它们,而是先调用它们的finalize()方法,目的是给这些对象一个清理资源的机会。 - 调用完
finalize()后,从unfinalized链表剔除:一旦对象的finalize()方法被调用,不论这个方法内部做了什么(即使是空操作),该对象会被从unfinalized链表中移除。此时,如果对象没有在其finalize()方法中重新被引用(即所谓的“自救”),它就会在下一次垃圾回收时被清理。 - 对象可以进行自救:在
finalize()方法执行期间,对象有机会将自己“自救”,即在方法内部使自己重新被引用(比如,将自己赋值给某个类变量或者对象的静态变量)。这样做可以阻止对象被垃圾回收器在当前回收周期内清理。 - 下一次GC时会进行回收:如果对象在执行
finalize()方法后没有进行自救,或者已经是第二次触发垃圾回收(即已经调用过finalize()方法),则在下一次垃圾回收时,这个对象将被彻底回收。
需要强调的是,虽然finalize()方法提供了一种机制让对象在被回收前有机会清理资源,但由于它的不确定性和执行成本,以及可能导致的问题(如对象自救导致的内存泄露),在实际编程中应避免使用。
Java提供了其他资源管理机制,如try-with-resources语句和AutoCloseable接口,这些机制应该被优先考虑用于资源的清理。
一个简单的自救示例:
public class SelfRescueDemo {
// 用于保存对象的引用,以实现"自救"
public static SelfRescueDemo rescueInstance = null;
@Override
protected void finalize() throws Throwable {
super.finalize();
System.out.println("finalize method executed!");
// 自救操作:将this赋值给rescueInstance
SelfRescueDemo.rescueInstance = this;
}
public static void main(String[] args) throws InterruptedException {
rescueInstance = new SelfRescueDemo();
// 第一次尝试自救
rescueInstance = null; // 取消引用
System.gc(); // 提示JVM进行垃圾回收
Thread.sleep(500); // 留出时间给垃圾回收器执行
if (rescueInstance != null) {
System.out.println("First rescue successful!");
} else {
System.out.println("First rescue failed.");
}
// 第二次尝试自救
rescueInstance = null; // 再次取消引用
System.gc(); // 再次提示JVM进行垃圾回收
Thread.sleep(500); // 再次留出时间给垃圾回收器执行
if (rescueInstance != null) {
System.out.println("Second rescue successful!");
} else {
System.out.println("Second rescue failed. Object has been collected.");
}
}
}在这个示例中,SelfRescueDemo类重写了finalize()方法,并在其中实现了自救逻辑。当rescueInstance对象第一次变为垃圾时,垃圾回收器会调用它的finalize()方法,在这个方法中,对象把自己的引用赋给了静态变量rescueInstance,从而达到了自救的目的。在第一轮垃圾回收后,我们可以看到打印出了"finalize method executed!"和"First rescue successful!",说明对象成功自救。
然而,值得注意的是,任何对象的finalize()方法只会被系统自动调用一次。如果对象在完成首次自救后再次变成无引用状态,垃圾回收器在下一次回收时不会再次调用它的finalize()方法,这次对象将被直接回收。因此,在第二次设置rescueInstance为null并触发垃圾回收后,会打印出"Second rescue failed. Object has been collected.",表示对象没有被再次自救,已经被回收。
这个示例展示了对象自救的概念和局限性。然而,在实际开发中,依赖finalize()方法进行资源清理或自救是不推荐的做法,因为它的执行时间是不确定的,而且可能导致资源释放不及时或者其他问题。使用Java提供的其他资源管理机制,如try-with-resources语句,是一种更好的做法。
String
String为什么是不可变的
- String内部维护的是private final char/byte数组,不可变线程安全
- 好处
- 防⽌被恶意篡改
- 作为HashMap的key可以保证不可变性
- 可以实现字符串常量池,在Java中,创建字符串对象的⽅式
- 通过字符串常量进⾏创建
- 在字符串常量池判断是否存在,如果存在就返回,不存 在就在字符串常量池创建后返回
- 通过new字符串对象进⾏创建
- 在字符串常量池中判断是否存在,如果不存在就创建, 再判断堆中是否存在,如果不存在就创建,然后返回该 对象,总之要保证字符串常量池和堆中都有该对象
- 通过字符串常量进⾏创建
可以讲一下为什么是不可变的,然后讲一下这样做有什么好处。
String、StringBuffer、StringBuilder 的区别
- String: 不可变,线程安全
- 内部维护的是private final char/byte数组(不可变)
- StringBuilder:可变字符串,线程不安全;可以使⽤append进⾏拼接字符串
- StringBuffer:可变字符串,线程安全;通过synchronized来保证线程安全,操作和 StringBuilder⼀样
- synchronized对于出现在循环中会进⾏锁粗化,会将锁的范围扩 展到整个操作,从⽽避免频繁进⾏锁操作造成性能开销
String → StringBuffer → Synchronized → 锁粗化
StringBuffer、StringBuilder 默认容量大小。
两个的默认容量大小都是 16 字符。
String 字符串如何实现编码转换。
一般是两个步骤:1. 将字符串转换为 byte 字节数组;2. 然后再将字节数组转换为字符串
面向对象
面向对象和面向过程的区别
- ⾯向过程可以理解为按步骤处理问题
- ⾯向对象可以理解为将具体事务存在的属性、⾏为抽象出来,然后去 进⾏实现
封装、继承和多态
- 封装:隐藏对象的细节和复杂性,同时提供公共的访问方法。封装通过访问控制保护了对象的状态。
- 继承:允许新的类继承现有类的属性和方法。支持代码复用,并建立了类之间的层次关系。
- 多态:允许使用统一的接口来表示不同的基础形态。同一个操作可应用于不同的对象,对象在运行时确定执行哪个方法。
字符串工具类 isEmpty 和 isBlank 的区别
- isEmpty 方法会检查字符串是否为 null 以及长度为 0 ;isEmpty(" ") → false
- isBlank 方法会检查字符串是否为 null 以及是否是空字符串; isBlank(" ") → true
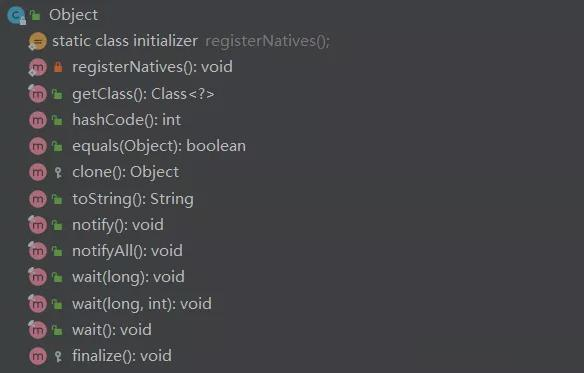
Object 有哪些常用方法
- equals、hashCode、toString、clone、finalize、wait、notify、notifyall
- getClass()
equals方法和== 操作符的区别
- == 操作符:
- 基本数据类型:比较的是值是否相等。
- 对象类型:比较的是引用是否相同,即两个引用是否指向堆内存中的同一个位置。
- equals方法:
- 默认行为是比较对象在堆内存中的地址(与 == 相同)。
- 许多类(如String、Integer)重写了
.equals()方法,使其用于比较对象的内容是否相等。
equals 和 hashCode 的区别和联系。
- equals 一般用于比较两个对象的内容或状态是否相等,他默认的用法和 == 相同,如果是引用类型,会比较对象的引用地址;多数类会重写该方法,从而比较对象的内容而不是内存地址。
- hashCode() 的作用是获取哈希码,即该对象在哈希表中的索引位置。哈希值在一些集合如HashMap、HashSet等非常关键
- 一般是建议重写 equals() 时必须重写 hashCode() 方法,如果没有重写哈希函数的话,两个键获取哈希表位置索引可能会不对,导致数据访问上的问题
两个对象的hashcode相同,equals⼀定相同吗
- ⼀般推荐重写equals⽅法的同时也要重写hashcode⽅法
- 两个对象的hashcode相同,equals可能相同
- 两个对象equals相同,hashcode⼀定相同
Hashcode的作用
java的集合有两类,一类是List,还有一类是Set。
前者有序可重复,后者无序不重复。当我们在set 中插入的时候怎么判断是否已经存在该元素呢,可以通过equals方法。但是如果元素太多,用这样 的方法就会比较慢。 于是有人发明了哈希算法来提高集合中查找元素的效率。 这种方式将集合分成若干个存储区域,每 个对象可以计算出一个哈希码,可以将哈希码分组,每组分别对应某个存储区域,根据一个对象的 哈希码就可以确定该对象应该存储的那个区域。
hashCode 方法可以这样理解:它返回的就是根据对象的内存地址换算出的一个值。这样一来,当 集合要添加新的元素时,先调用这个元素的hashCode方法,就一下子能定位到它应该放置的物理 位置上。如果这个位置上没有元素,它就可以直接存储在这个位置上,不用再进行任何比较了;如 果这个位置上已经有元素了,就调用它的equals方法与新元素进行比较,相同的话就不存了,不相 同就散列其它的地址。这样一来实际调用equals方法的次数就大大降低了,几乎只需要一两次
【hashcode() 哈希值 → equal 比较值 (提高索引效率)】
重载和重写的区别
- 重写:子类重写父类的方法,返回类型、参数列表、方法名称相同
- 1.发生在父类与子类之间
- 2.方法名,参数列表,返回类型(除过子类中方法的返回类型 是父类中返回类型的子类)必须相同
- 3.访问修饰符的限制一定要大于被重写方法的访问修饰符 (public>protected>default>private)
- 4.重写方法一定不能抛出新的检查异常或者比被重写方法申 明更加宽泛的检查型异常
- 重载:同一个类下,多个同名方法,参数列表不同; 方法返回值和访问修饰符可以不同
- 1.重载Overload是一个类中多态性的一种表现
- 2.重载要求同名方法的参数列表不同(参 数类型,参数个数甚至是参数顺序)
- 3.重载的时候,返回值类型可以相同也可以不相同。无法以返回 型别作为重载函数的区分标准
类
讲一下内部类,匿名内部类怎么使用的
- 在Java 中,内部类是定义在一个类内部的类,常用的内部类有:局部内部类、匿名内部类、静态内部类、成员内部类
- 匿名内部类的使用:继承一个父类或实现一个接口,实现其方法,然后调用这个方法;一般使用的常见场景有Thread类的匿名内部类实现和Runable 接口的匿名内部类实现。
讲一下深拷贝、浅拷贝和引用拷贝
- 浅拷贝:只复制对象的基本类型字段和引用类型字段的引用,不复制引用对象本身。
- 副本对象和原对象都指向同⼀块内存空间,副本对象的改 变会影响到原对象
- 深拷贝:复制对象的所有字段,包括基本类型和引用类型字段,引用类型的对象也会被复制。
- 副本对象和原对象不指向通⼀块内存空间,会重新开辟⼀ 块内存空间给副本对象进⾏指向
- 引用拷贝:只复制对象的引用,不复制对象本身。
接口和抽象类的区别
- 首先是类和接口的区别,接口可以实现多个接口,类只能继承单个;
- 然后更多的是用法上面的区别:接口是一个协议,强调功能的相似性(相同的行为);抽闲类强调的是类之间的共性(公共类结构)。
异常、反射、注解、泛型
讲一下空指针异常,如何避免
- 当我们在尝试使用 null 引用的时候,会发生 NPE
- 避免空指针异常
- 在使用之前先检查一下是否为 null
- 调用方法的时候进行参数检查
- 在设计方法或者API 的时候,尽量不要返回 null 值,而且返回一个空集合或者默认值;
- 初始化使用字段,保证不为 null
- 使用 Optional
- 使用断言(开发和测试环境)
try-catch-finally 中哪个部分可以省略。
- 可以省略
catch块或finally块中的任何一个,但不能两个都省略
讲一下Java 反射
- 反射:允许程序在运行时检查或修改Java虚拟机中的类
- 比如在框架中就大量使用动态代理获取到类的属性,从而实现一些复杂的功能。
讲一下 Java 泛型
泛型比较大的作用是能够提高代码重用性和灵活性;它允许在类、接口、方法上使用类型参数
Java 泛型中的 T、R、K、V、E 是什么。
T- TypeR- ReturnK- KeyV- ValueE- Element
SPI
什么是 SPI,有什么用。
Java 通过 SPI 机制为服务标准接口找到其实现服务。
Java SPI 实现原理了解吗。
- Java SPI的实现基于
ServiceLoader类。 - 服务提供者在
META-INF/services目录下提供配置文件,其中指定接口的实现类。 ServiceLoader可以加载这些实现。
IO
I/O 流为什么要分为字节流和字符流呢?
- 字节流:处理原始二进制数据
- 字符流:处理字符数据,自动处理字符编码问题
Java IO 中的设计模式有哪些。
- 装适器、适配器
常见的 IO 模型有哪些
- BIO(Blocking IO):同步阻塞IO
- NIO(Non-blocking IO):同步非阻塞IO
- AIO(Asynchronous IO):异步非阻塞IO
API
Java 怎么获取当前的系统时间戳
- 获取当前系统时间戳:
System.currentTimeMillis()
如果需要 统计一段代码的耗时,可以使用上述方法获取执行方法前后的时间差。