Appearance
基础
优化/索引
在 MySQL 中,如何定位慢查询?
- 聚合查询
- 多表查询
- 表数据量过大查询
- 深度分页查询
表象:页面加载过慢、接口压测响应时间过长(超过 1s )
方案一、开源工具
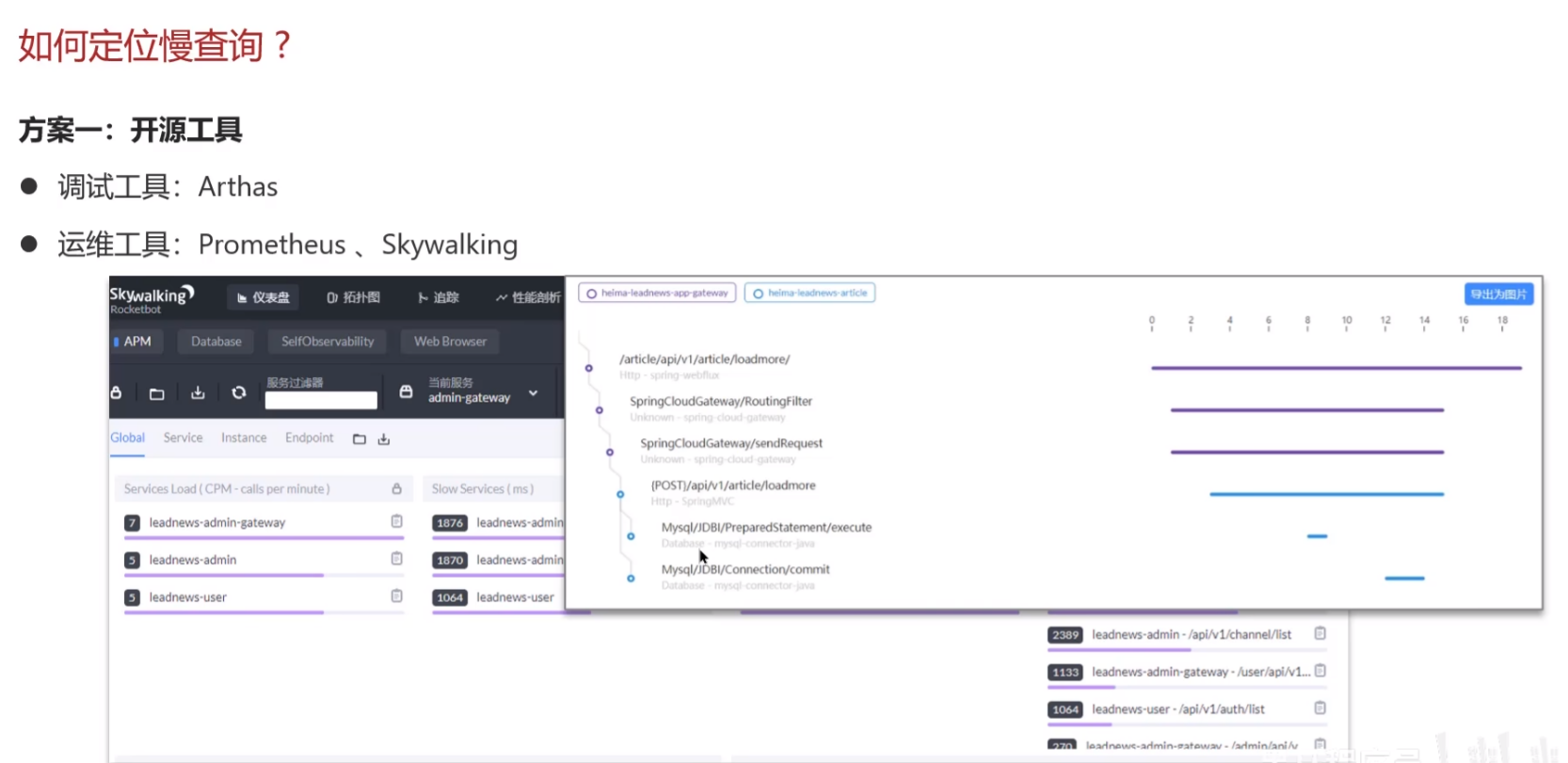
方案二: MySQL 自带慢日志

总结:

(生产阶段一般不开启慢日志查询)
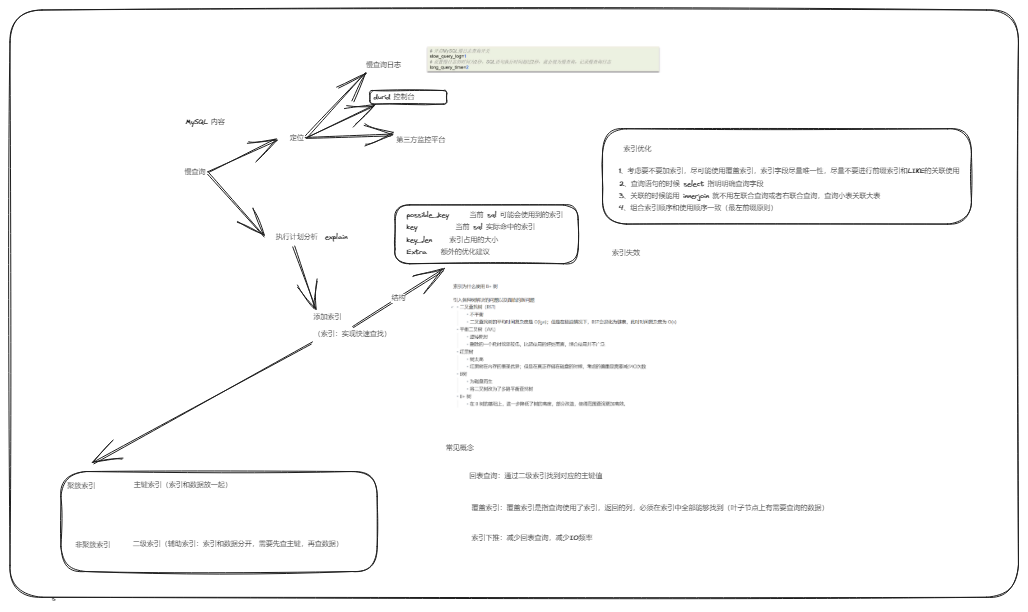
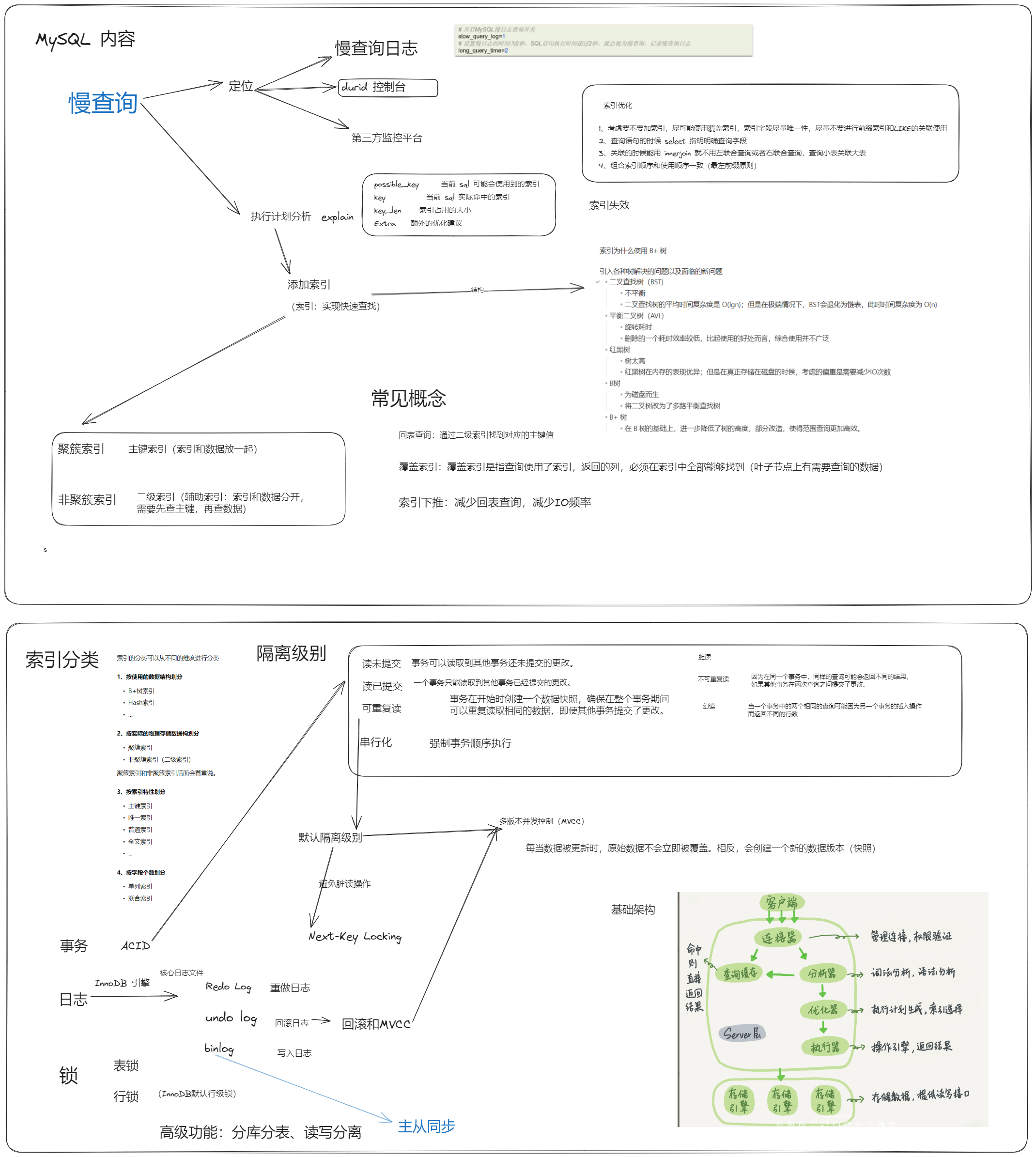
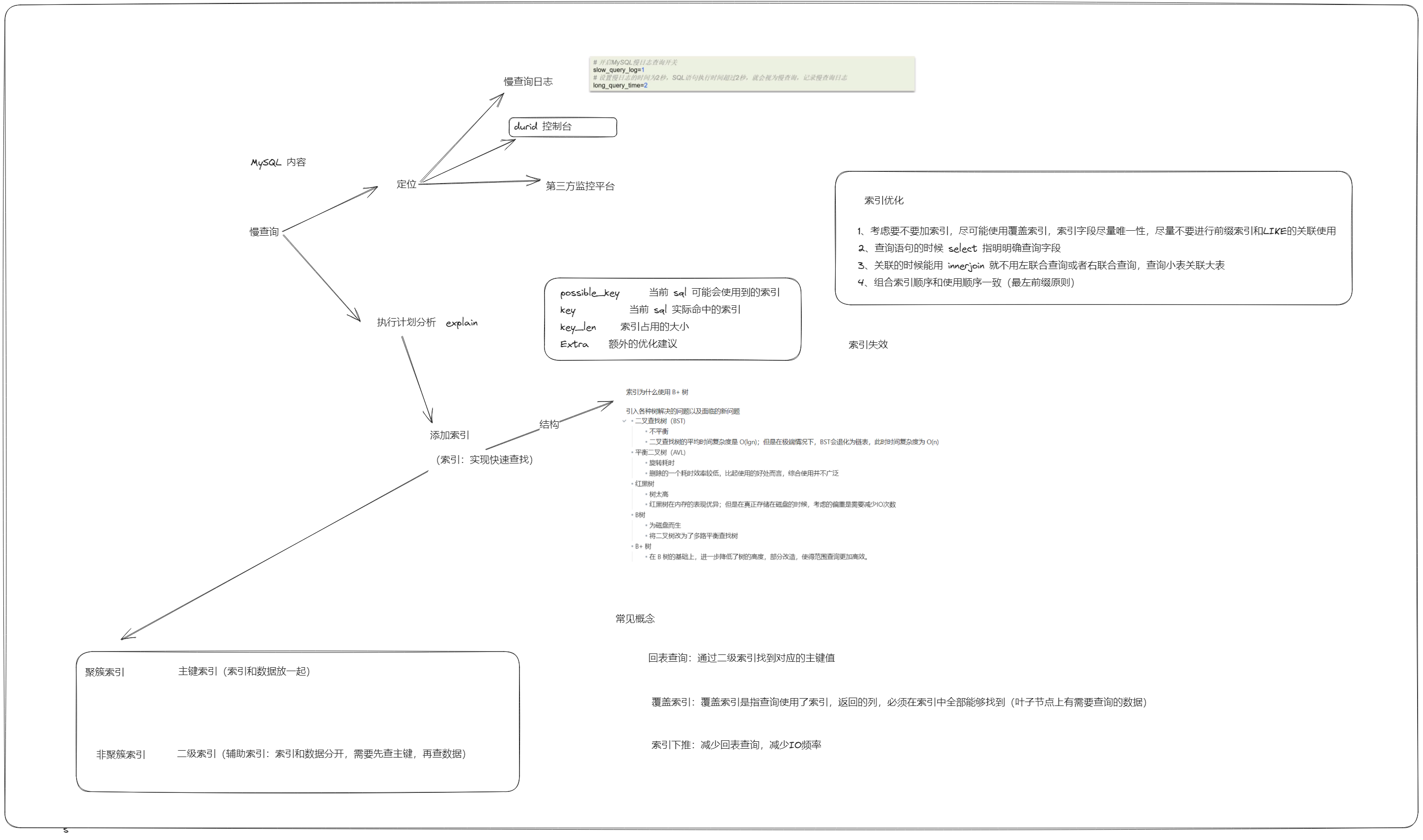
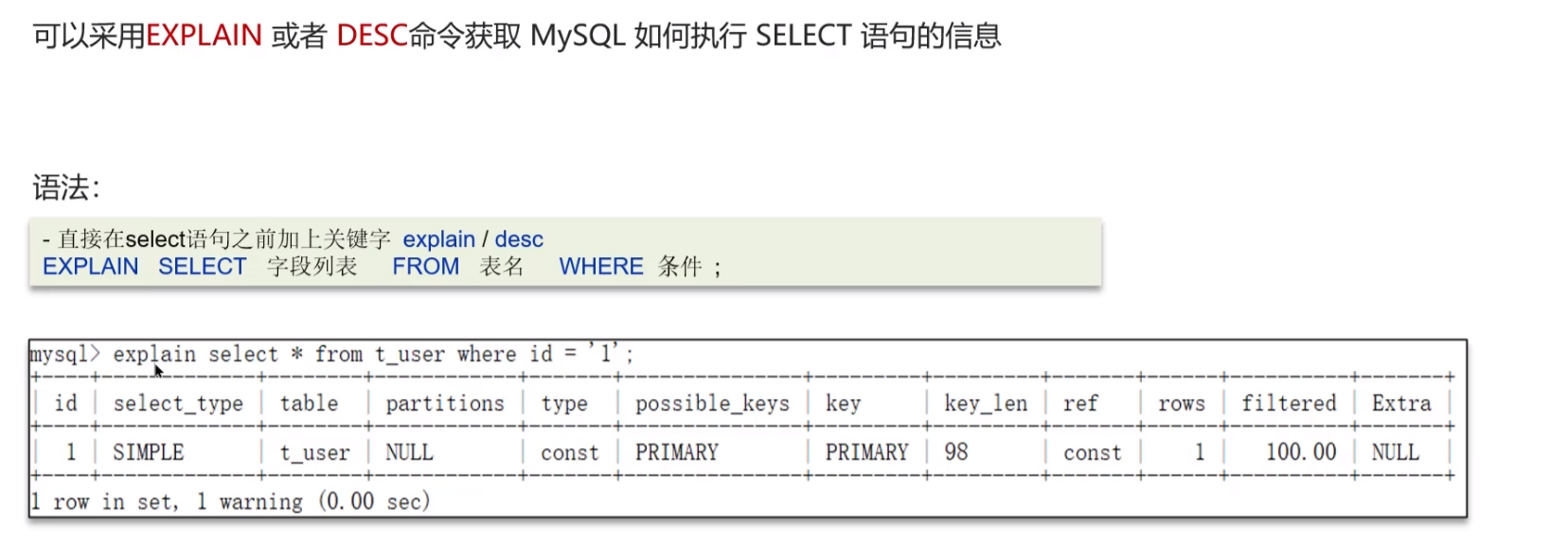
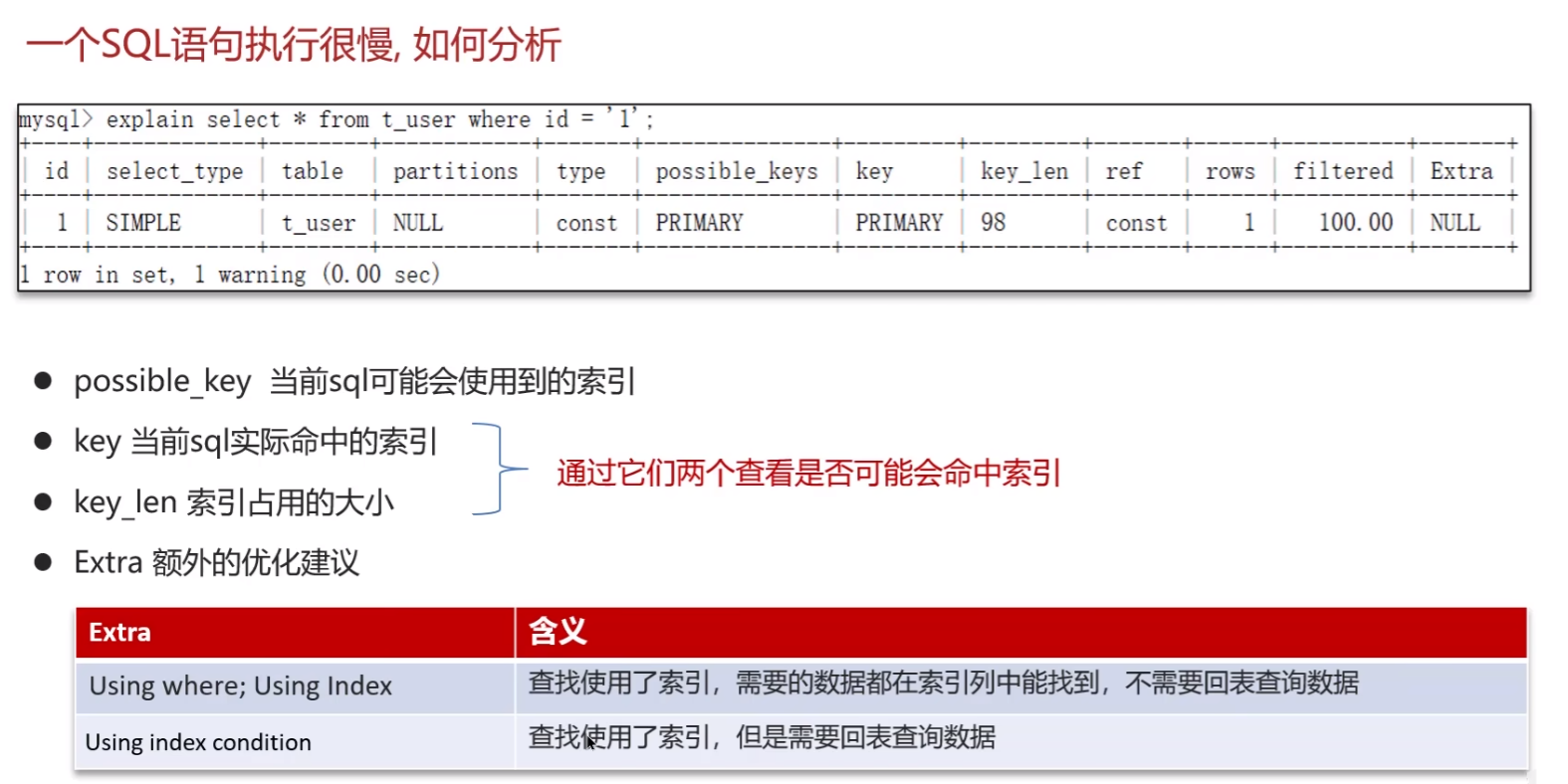
开源采用 EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息
参数使用
- possible_key 当前 sql 可能会使用到的索引
- key 当前 sql 实际命中的索引
- key_len 索引占用的大小
- Extra 额外的优化建议
- type

总结

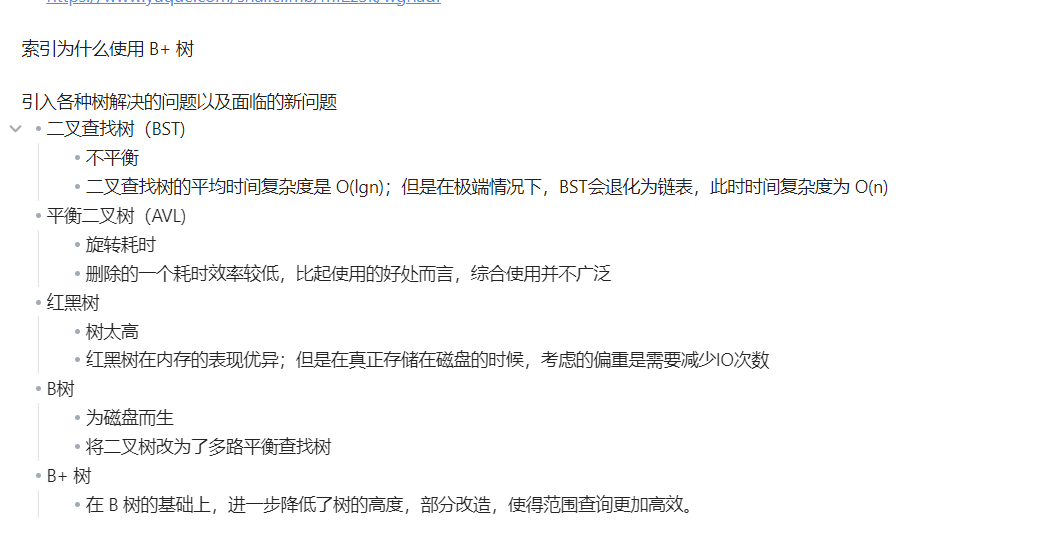
什么是索引 🚩
这里先讲一下 MySQL 的的基础结构,讲一下优化器的选择,再讲一下选择索引选择(主键索引和从表索引)
提高访问效率,索引是某种数据结构组成
索引(index)是帮助 MySQL 高效获取数据的数据结构 (有序) 。
在数据之外,数据库系统还维护着满足特定查找算法的数据结构(B+树),这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法,这种数据结构就是索引。
讲一下索引的底层结构
- 目前索引采用的底层结构是 B+ 树
什么是聚簇索引,什么是非聚簇索引

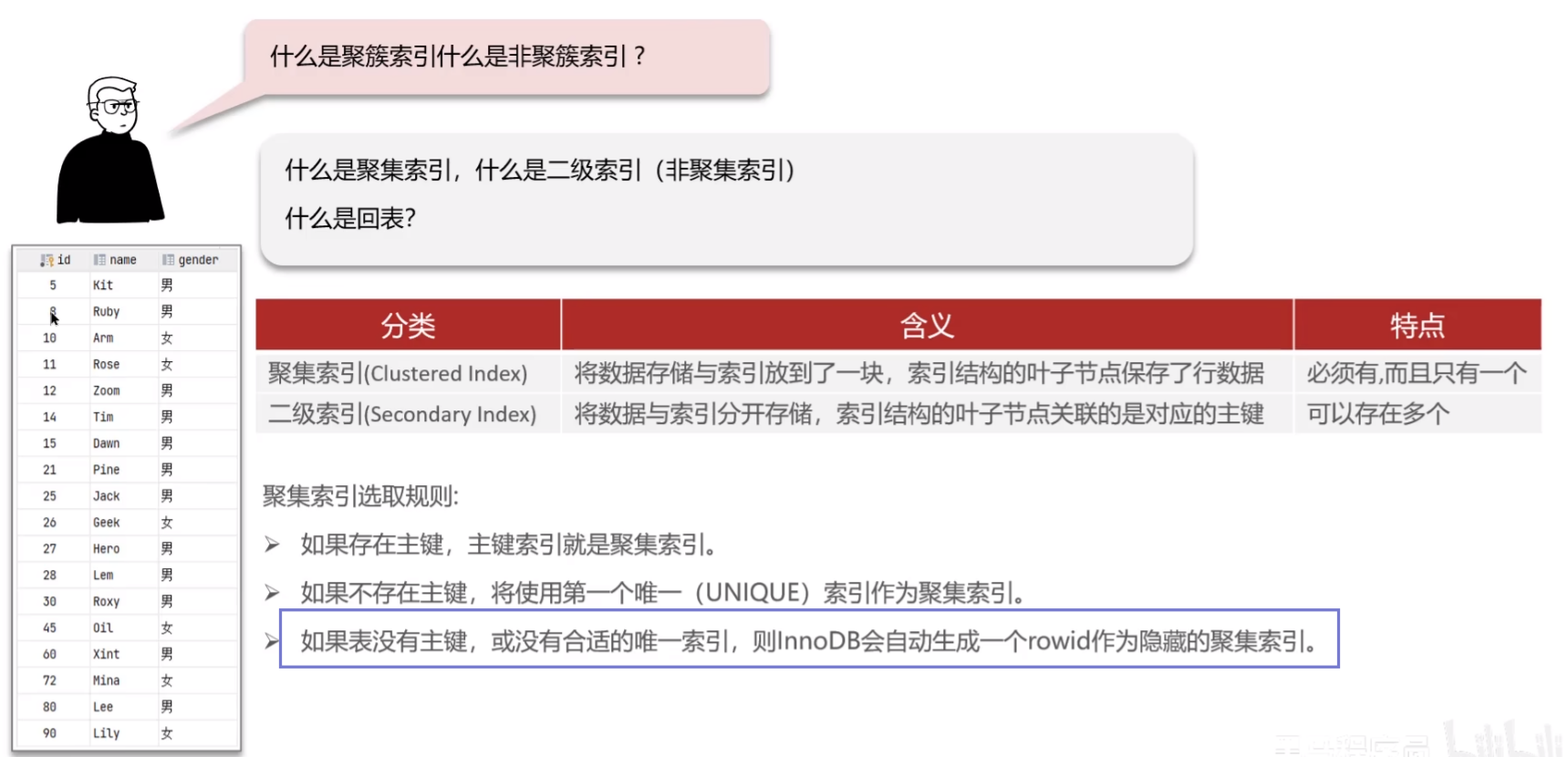
讲一下回表查询
回表查询:通过二级索引找到对应的主键值

知道什么是覆盖索引吗
对查询列有要求,一般是查询的字段和索引字段相同,不同走主键查询那步,直接从索引树上查询出了数据

你看一下这个例子,主键索引中查询条件是主键的话,直接查询所有数据是话算是覆盖索引,然后如果是二级索引,查询 主键+ 索引 是算覆盖索引查询(索引树上直接查询)
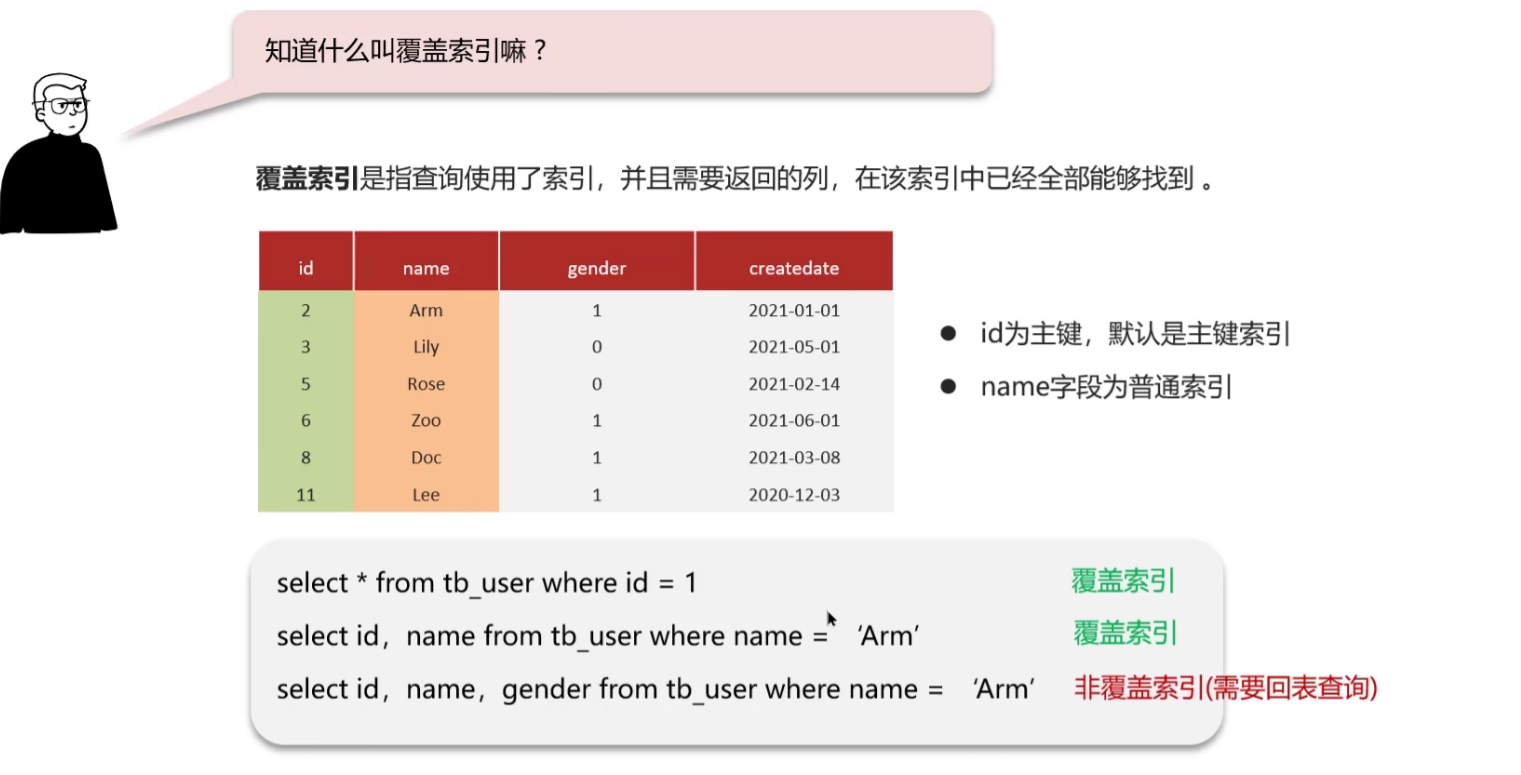
覆盖索引的基本介绍

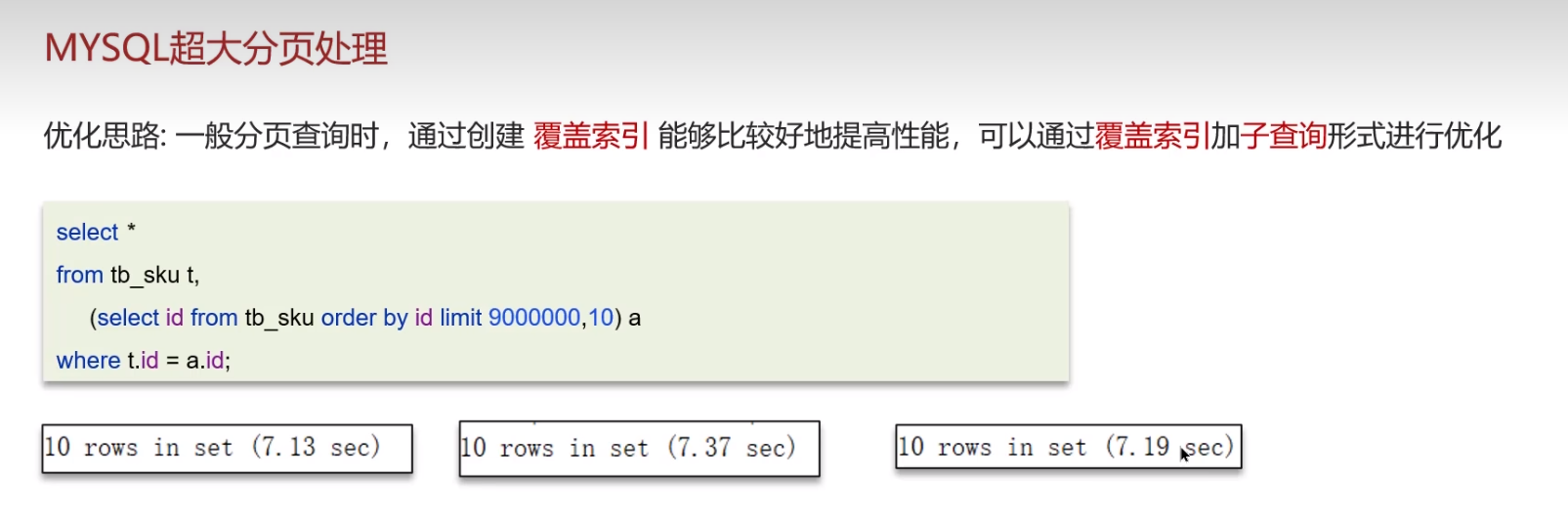
MySQL 超大分页怎么处理

提供一种解决思路:通过覆盖索引 + 子查询 形式进行优化 、
- 先通过覆盖索引查询出对应的ID,然后通过关联查询,查询出分页数据
总结

索引创建原则
回答思路:

主要的一些原则:

索引创建原则有哪些?
- 数据量较大,且查询比较频繁的表 重要
- 2).常作为查询条件、排序、分组的字段 重要
- 3).字段内容区分度高
- 4).内容较长,使用前缀索引
- 5).尽量联合索引 重要
- 6).要控制索引的数量 重要
- 7).如果索引列不能存储NULL 值,请在创建表时使用NOT NULL 约束它
索引失效
如何判断索引是否失效:通过 执行计划 explain
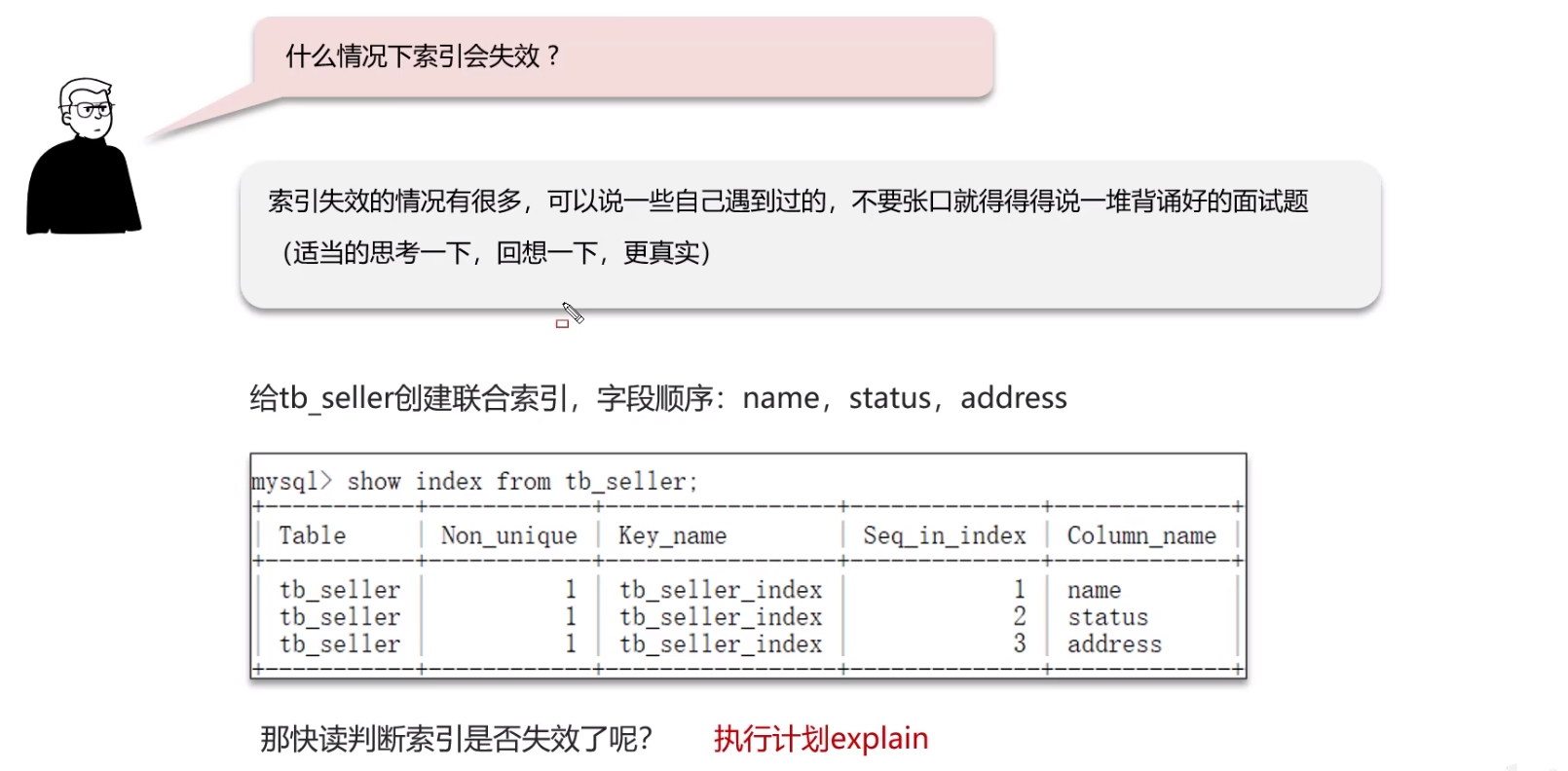
索引失效的一些情况:

理解去记忆一下
谈谈你对 SQL 优化的经验

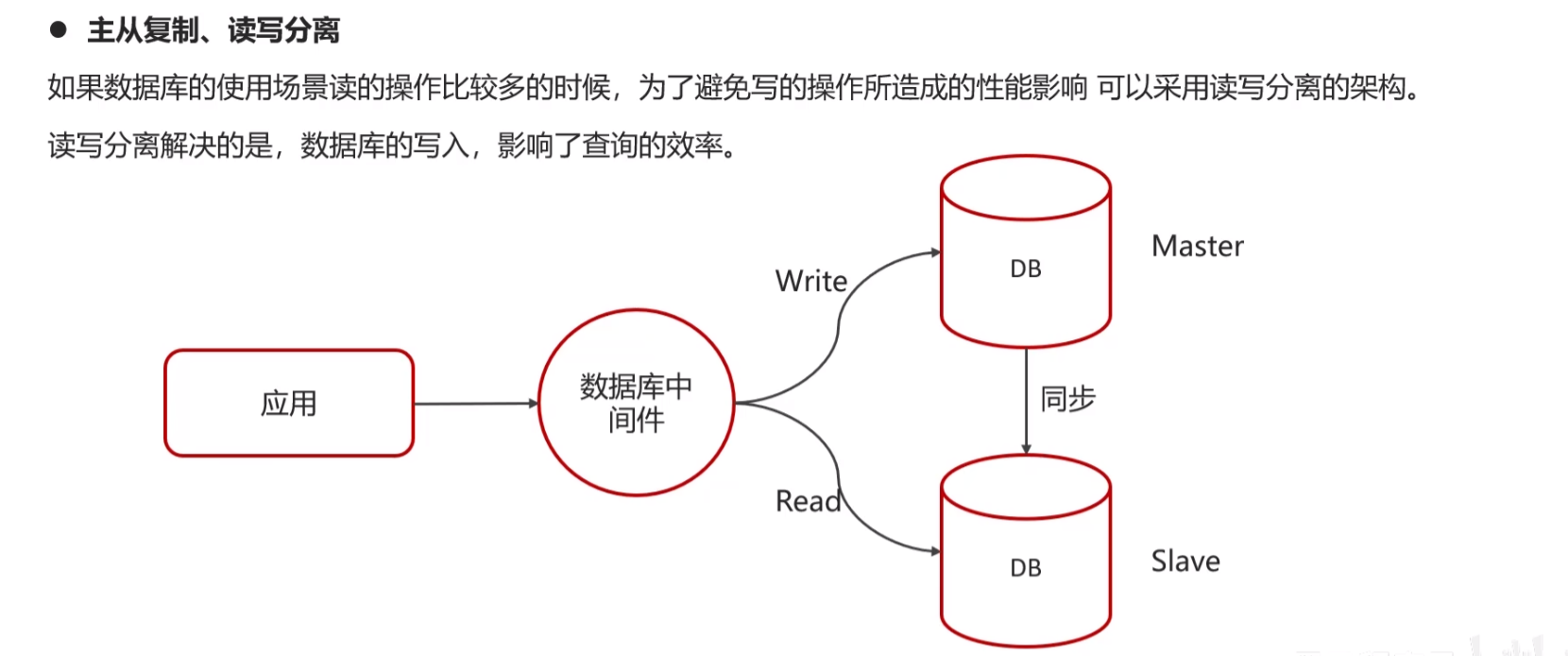
- 主从复制、读写分离
总结:
- 1、表的设计优化,数据类型的选择
- 2、索引优化,索引创建原则、
- 3、sql语句优化,避免索引失效,避免使用select * ....
- 4、主从复制、读写分离,不让数据的写入,影响读操作
- 5、分库分表
最左匹配原则

索引下推
锁
- 悲观锁
- 乐观锁
- 表锁
- 行锁(Innodb 存储引擎)
悲观锁实现
可以通过SQL语句显式地对选定的行进行锁定,直到当前事务结束。
- SELECT ... FOR UPDATE: 对读取的行加上排他锁(X锁)。其他事务将不能读取或修改这些行。
- SELECT ... LOCK IN SHARE MODE: 对读取的行加上共享锁(S锁)。其他事务可以读取但不能修改这些行。

update 没加索引会锁全表?
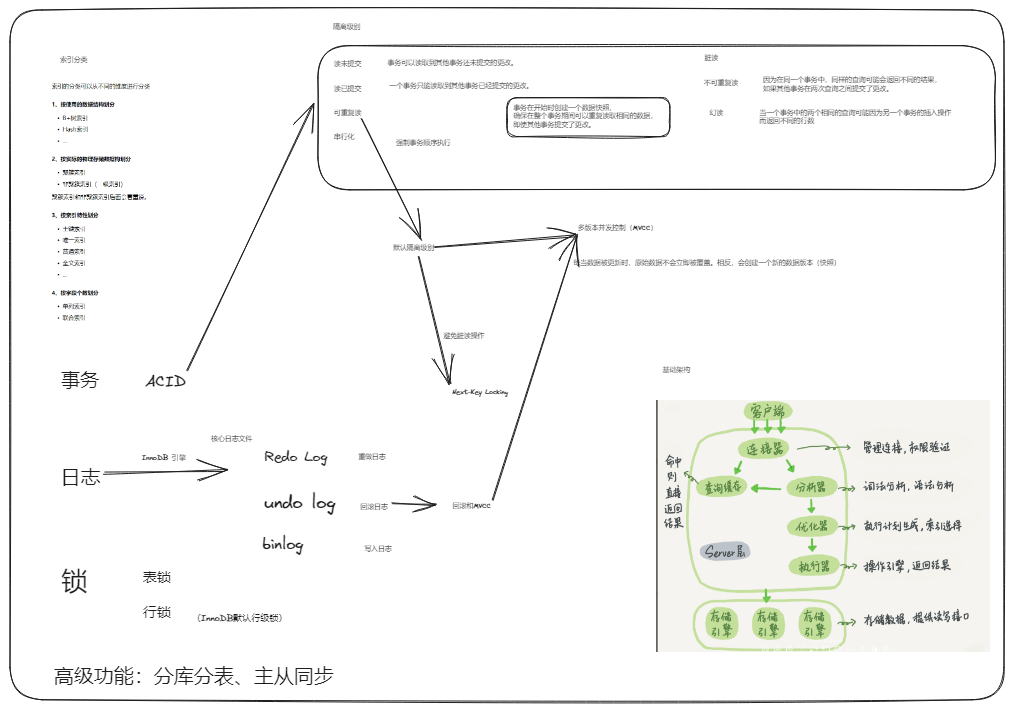
事务
事务的特性
事务:事务是一组操作的集合,它是一个不可分割的工作单位,事务会把所有的操作作为一个整体一起向系 统提交或撤销操作请求,即这些操作要么同时成功,要么同时失败。
ACID是什么?可以详细说一下吗?
- 原子性(Atomicity):事务是不可分割的最小操作单元,要么全部成功,要么全部失败。
- 一致性(Consistency):事务完成时,必须使所有的数据都保持一致状态。
- 隔离性(Isolation):数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行。
- 持久性(Durability):事务一旦提交或回滚,它对数据库中的数据的改变就是永久的。
讲述这种题目的适合最好结合一下实际案例来讲述一下,让面试官觉得你讲的和其他人有所不同
示例:

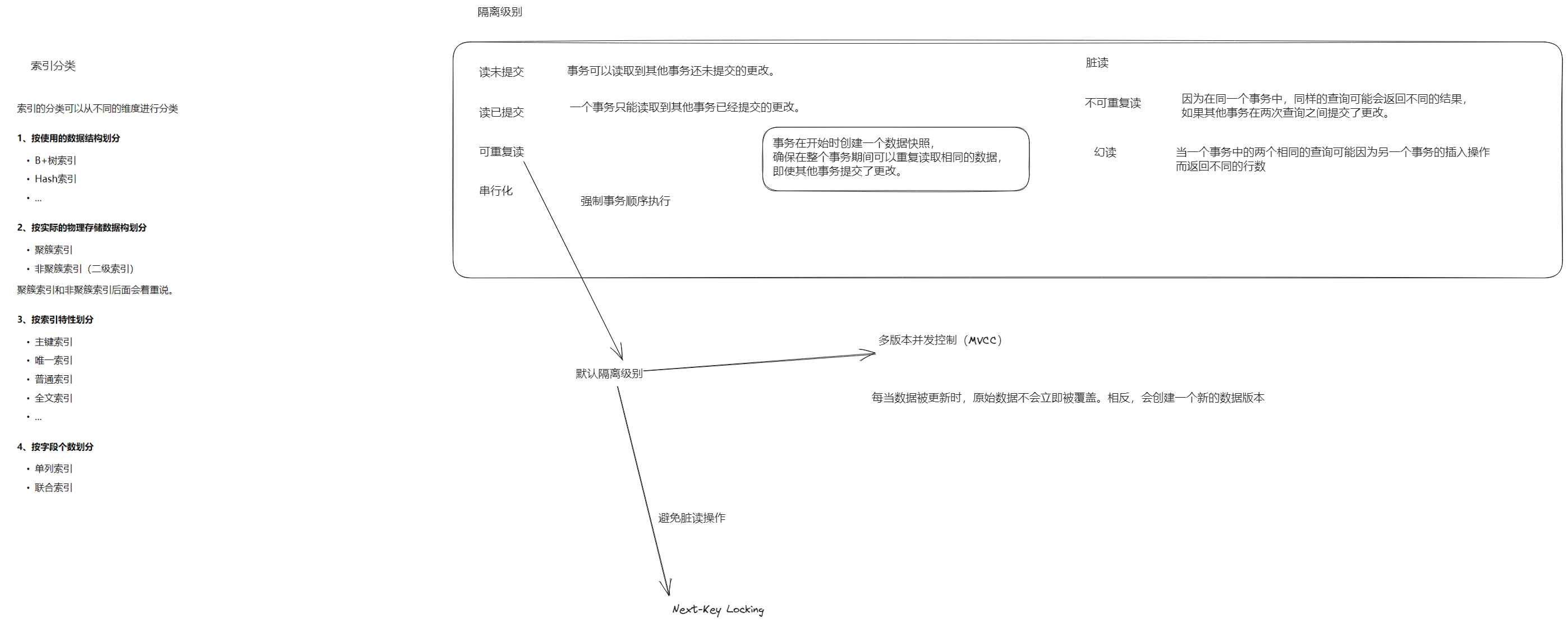
并发事务带来哪些问题?怎么解决这些问题呢?MySQL 的隔离级别是?
- 并发事务问题:脏读、不可重复读、幻读
- 隔离级别:读未提交、读已提交、可重复读、串行化
并发事务问题

怎么解决并发事务的问题?
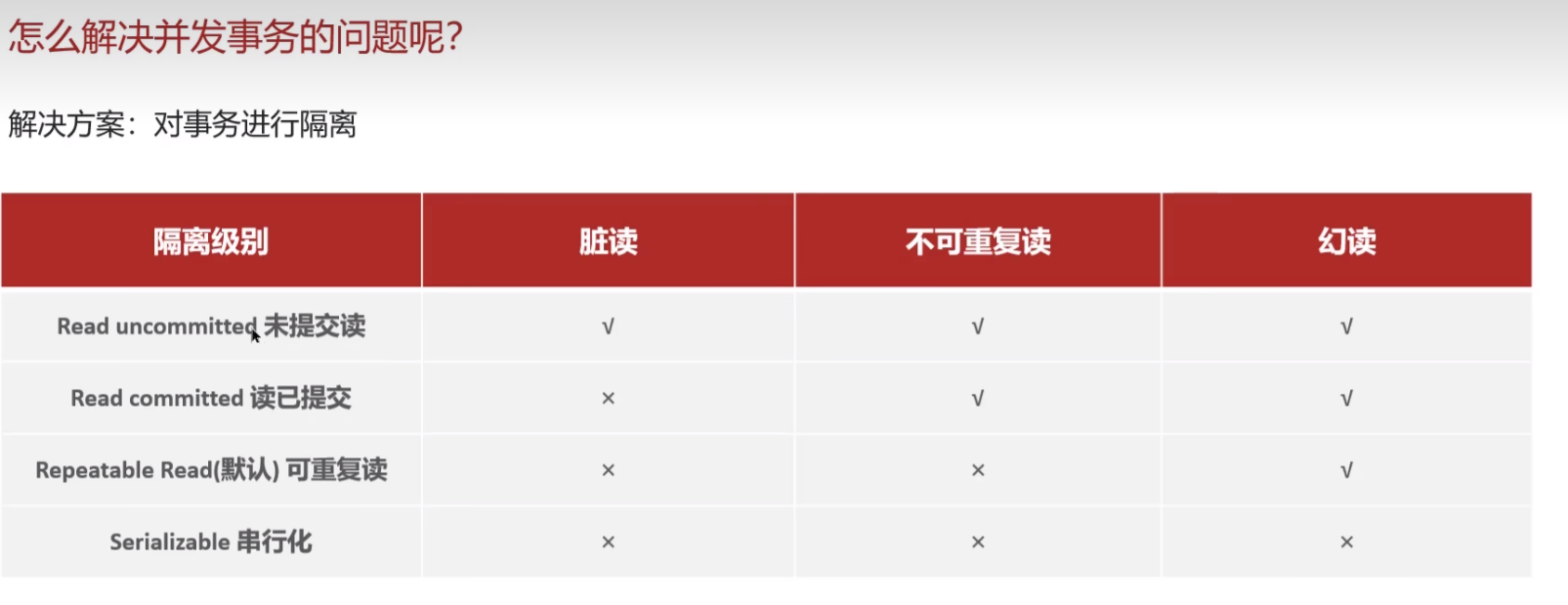
注意:事务隔离级别越高,数据越安全,但是性能越低。
总结:

解释一下 MVCC
日志

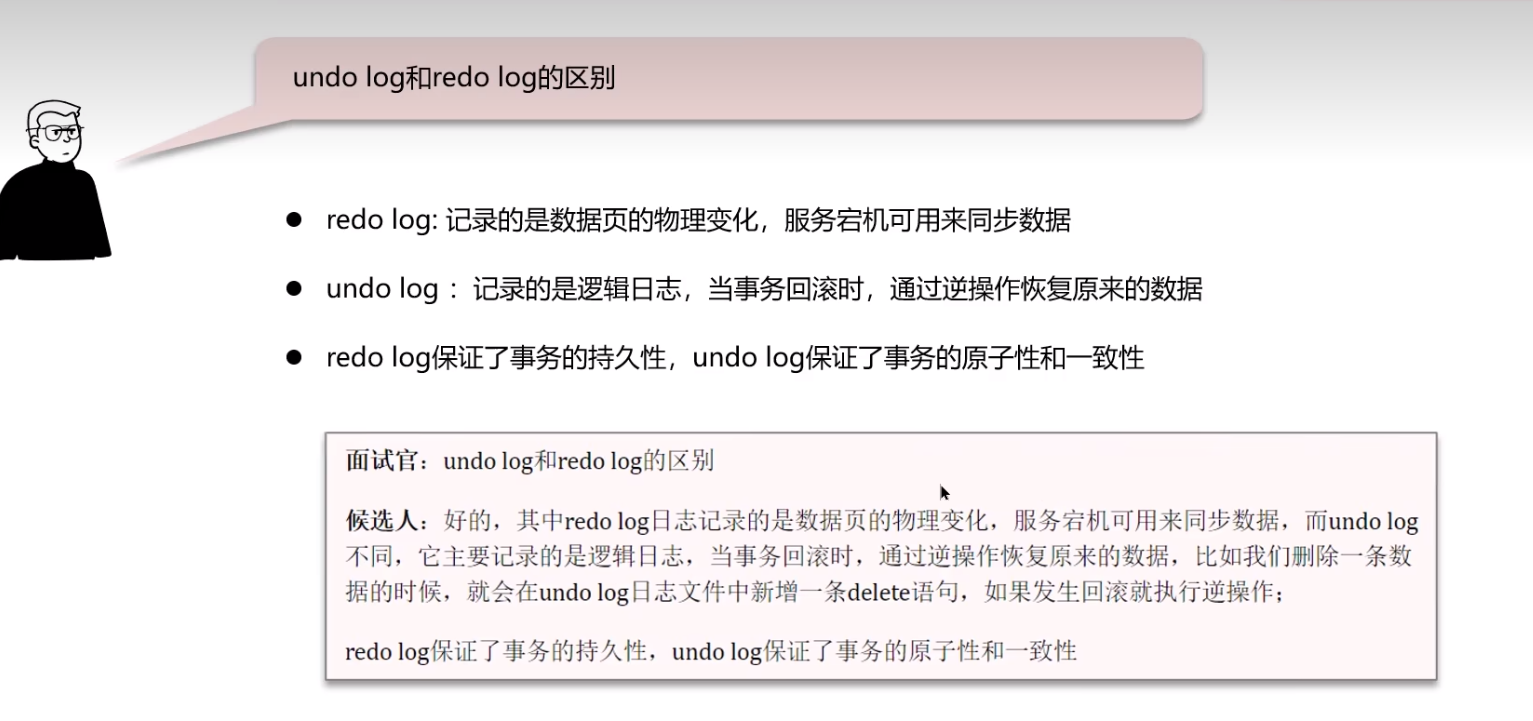
undo log 和 redo log 的区别?
先引入一个概念:即缓存池和数据页,数据页是磁盘中实际存储的数据,但一般数据加载的时候会先从内存中到磁盘,这个内存的区域叫做缓冲池。
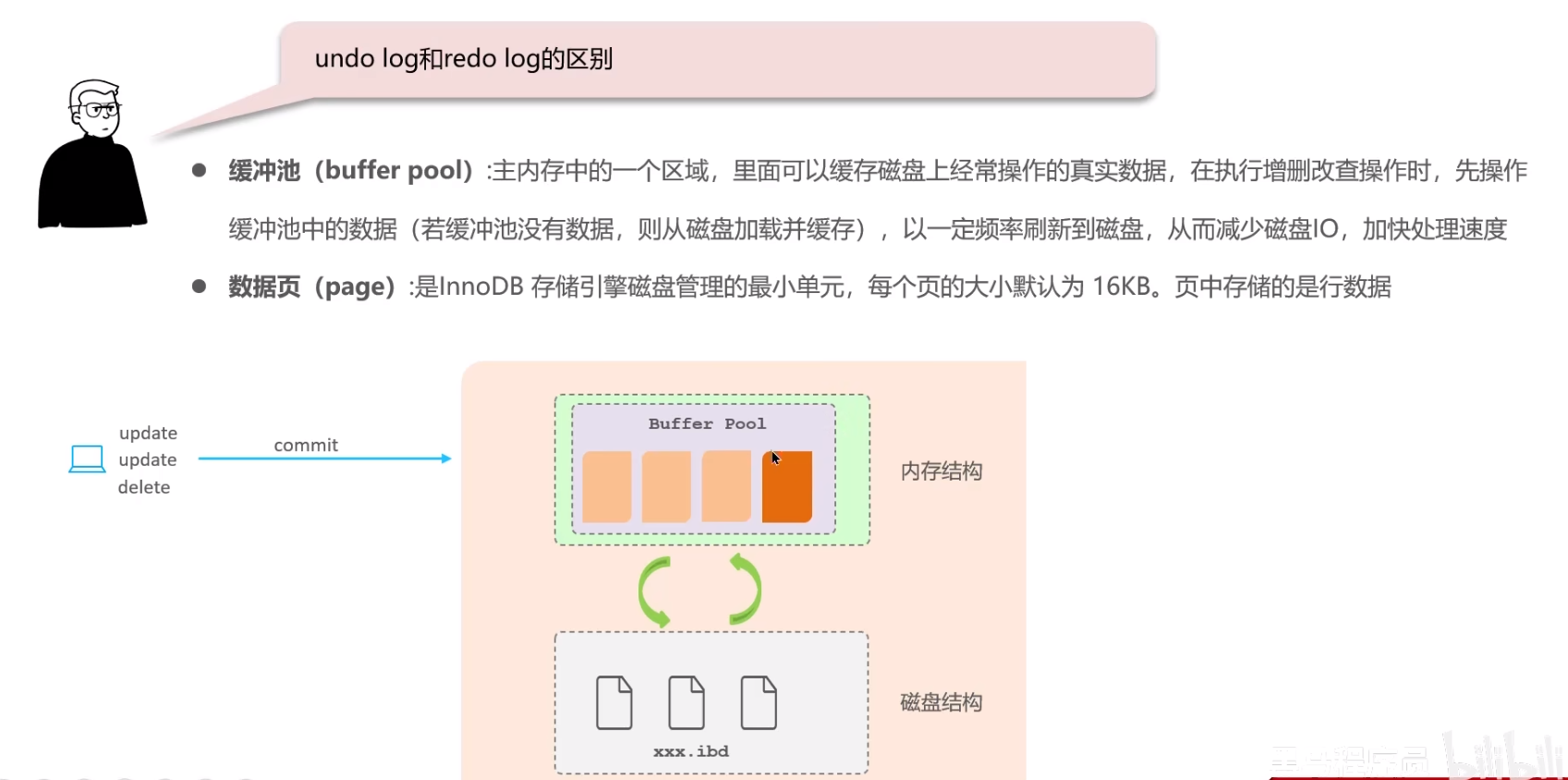
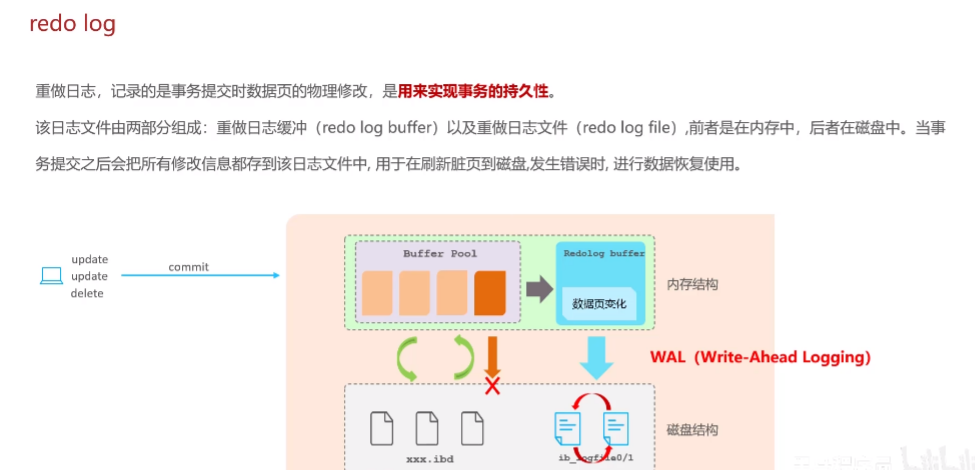
服务宕机的时候,数据如何保证不丢失,是由于日志的存在。
- redo log:
- undo log

总结:
高级功能
讲一下 主从同步原理

讲一下 分库分表
分表是指将一个大表拆分成多个小表的过程。
这些小表可以分布在同一个数据库或多个数据库中。分表通常基于某些关键字段进行,比如时间、用户ID等。
- 垂直分表:将表中不同的列分到不同的表中。例如,一个用户表可以被分成用户基础信息表和用户详细信息表。
- 水平分表:根据行数据将表分成多个表,每个表包含相同的列,但只包含部分行。例如,基于用户ID范围或创建时间进行切分。
分库涉及将数据分布到多个数据库实例上。每个数据库实例可以托管在不同的服务器上,从而分散负载和提高容错能力。
- 分布式数据库:数据被分散存储在多个物理位置,每个数据库实例可以独立处理查询和事务。
- 读写分离:常与分库结合使用,读操作和写操作分别在不同的数据库实例上进行。
读写分离
读写分离涉及将数据库的读取操作(SELECT查询)和写入操作(INSERT、UPDATE、DELETE)分离到不同的服务器上。