Appearance
复习版本
- 分布式事务:两个微服务以上的接口调用
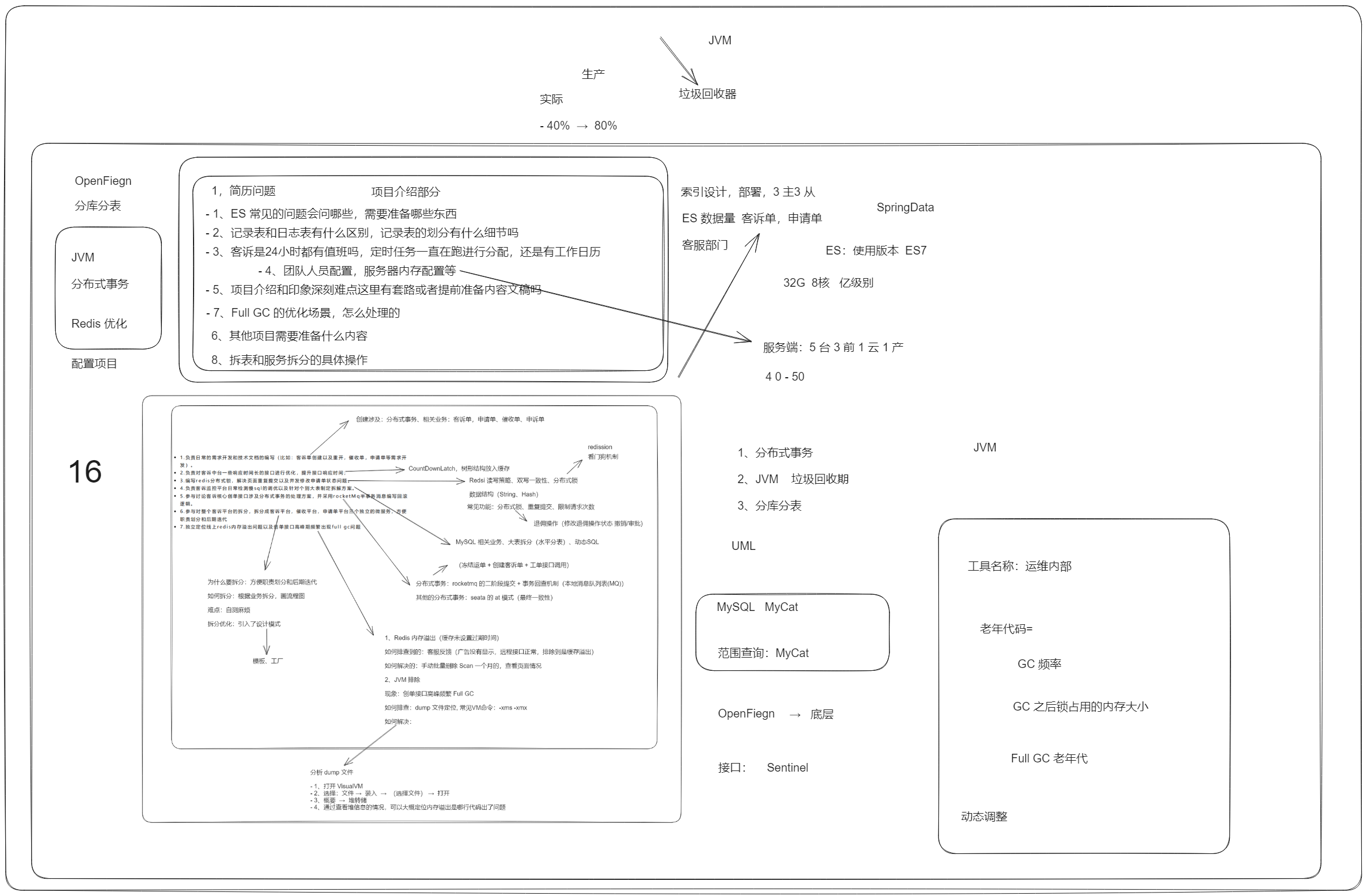
问题
- 1、ES 常见的问题会问哪些,需要准备哪些东西
- 2、记录表和日志表有什么区别,记录表的划分有什么细节吗
- 3、客诉是24小时都有值班吗,定时任务一直在跑进行分配,还是有工作日历
- 4、团队人员配置,服务器内存配置等
- 5、项目介绍和印象深刻难点这里有套路或者提前准备内容文稿吗
- 6、ES 相关问题需要准备哪些内容
- 7、Full GC 的优化场景,怎么处理的
问题:
- 1、记录表和日志表有什么区别,记录表的划分有什么细节吗
- 2、这个记录表是只是客诉服务在用吗
- 3、技术文档你们一般怎么写的,有什么规范吗(包括文档规范、代码规范、数据库规范)
- 4、客诉是24小时都有值班吗,定时任务一直在跑进行分配,还是有工作日历
- 5、Full GC 的优化场景,怎么处理的,相关八股
- 6、团队人员配置,服务器内存配置等
- 7、项目介绍和印象深刻难点这里有套路或者提前准备内容文稿吗
- 8、为什么要重开
自我介绍
- 面试官你好,我叫xxx,学历专业介绍
- 工作经历介绍
简历内容
工作内容
- 1、日常需求迭代
- 2、后期微服务的拆分(客诉平台的拆分:客诉平台,催收平台,申请单平台)
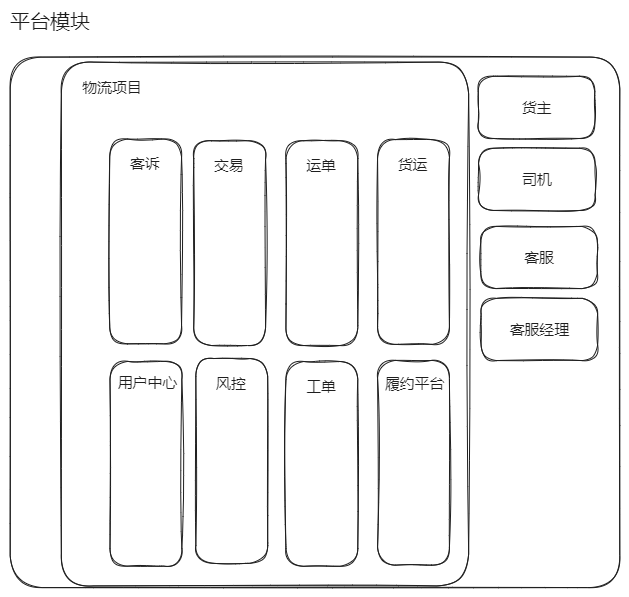
项目名称:物流客诉中台(2022.7-2023.10)
技术栈:Springcloud,MySql,Redis,Mybatis,RocketMQ,ElasticSearch
微服务模块:运单部门、交易部门、工单部门、客诉部门、货源部门、用户中心,外呼部门、中间件团 队,风控部门
项目描述:本平台主要是对司机和货主在交易中产生的投诉进行处理。货主发货,司机接货,中途如果 产生纠纷会创建客诉单,该客诉单会流向公司的客服部门,客服进行客诉单的审核,如果涉及退钱的客 诉类型还需要客服领导审核。整个模块业务和其他部门交互采用mq消息形式,也有采用 rpc同步远 程调用对方接口的方式。如果有公司垫付费用的情况还会涉及催收单和申诉单的业务产生。客诉系统包 括催收单、申请单、客诉单、申诉单。我们部门主要负责整个客诉平台的迭代和优化,提升客服的办事 效率。
责任描述:
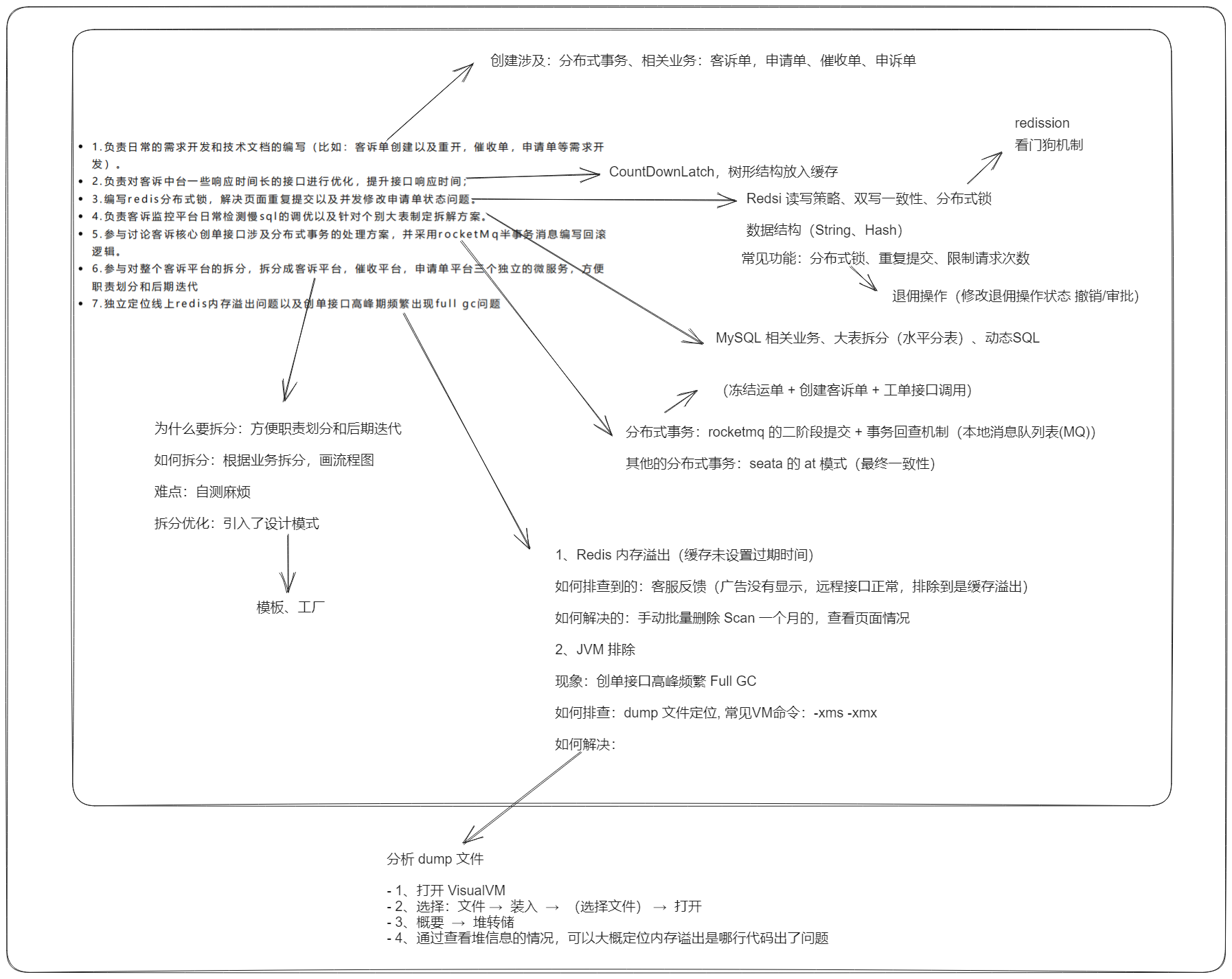
- 1、负责日常的需求开发和技术文档的编写(比如:客诉单创建以及重开,催收单,申请单等需求开发)
- 2、负责对客诉中台一些响应时间长的接口进行优化,提升接口响应时间
- 3、编写 redis 分布式锁,解决页面重复提交、分单定时任务重复执行以及并发修改申请单状态问题
- 4、负责客诉监控平台日常检测 慢SQL 的调优以及针对个别大表制定拆解方案,
- 5、组织其他部门讨论客诉核心创单接口涉及分布式事务的处理方案,并采用rocketMq半事务消息编写回滚逻辑。
- 6、参与对整个客诉平台的拆分,拆分成客诉平台,催收平台,申请单平台三个独立的微服务,方便职责划分和后期迭代
- 7、独立定位线上redis内存溢出问题以及创单接口高峰期频繁出现full gc问题和VM内存oom问题并解决。

01 整体业务
负责日常的需求开发和技术文档的编写(比如:客诉单创建以及重开,催收单,申请单等需求开发)
客诉单创建业务
- 1、司机或者货主通过平台界面进行选择进入到申诉界面,填写申诉信息进行提交(包括图片截图信息)
- 2、司机或者货主联系客服,客服进行人工后台进行创建,图片相关信息通过联系司机/货主进行二次提交操作。
重开业务
- 针对同一个运单,可能会出现申诉单结束后,进行二次申诉的场景,此时会在原申诉单ID 的基础上进行重开操作(申诉单记录只有一条,记录表多条数据)
催收单业务
- 出现类似货主不退还押金的情况,司机申诉的操作(涉及押金)
- 此时客服会进行垫付操作,先将押金退还给司机,生成 平台 → 货主 的一个催收单
- 货主催收也不还 → 打标 → 拉黑
申请单
- 客诉单进行创建的时候,会将 客诉类型 ID + 客诉单 ID 传给工单部门,工单后台根据规则引擎生成 申请单模板
- 点击客诉单详情的时候,详情界面会有多个按钮数据,一个客诉单对应多个申请单,点击不同的按钮,对应不同的操作,并会对应不同的申请单给工单部门那边进行审核操作。
关于客诉单的部分业务内容
- 客诉单状态
- 待领取,已领取,审核中,审核完成,已办结
- 当该客诉单处于【待领取】状态,司机/货主可以进行撤销操作
- 分配到客服手中,状态会被修改为【已领取】
- 创建客诉对应的后台业务操作
- 1、远程调用运单服务,冻结运单【MQ 方式交互】
- 2、客诉单入库(数据库是1主2从)
- 3、图片入库(OSS 地址关联客诉单 ID)
- 4、客诉单ID → 详情信息 → 组装 ES 关键数据 → 存入ES
- 5、调用生成申请单接口(客诉单ID + 投诉单 ID 发送) → 工单部门 → 规则引擎生成模板
- 6、记录表记录事件内容
- 7、生成外呼表记录
- 8、定时任务:分配客诉单到客服手上
- 客诉单状态
互联网业务交互流程
- 会议
- 天数
- 技术文档
- 技术点 + 改动点 + 风险点
- 技术评审
- 风险评估
- 开发前前后对接
- 开发阶段
02 接口优化
负责对客诉中台一些响应时间长的接口进行优化,提升接口响应时间
这里主要是针对客诉单详情页进行优化操作,使用异步编码 + 三级结构存入 Redis 中
细讲业务,每一步从哪里操作的
多线程 + 三级分类
多线程某个任务失败了怎么办,如何感知(异常如何感知)
2 秒怎么得出来的(前端界面的响应时间)
Redis 缓存一致性
多线程的问题
开启子线程,去查询数据【看一下他视频怎么做的】
- 主线程 + 子线程
怎么保持
Comn
CountDownLatch +
数据表设计
- id parents
CountDownLatch

03 Redis 使用
编写 redis 分布式锁,解决页面重复提交、分单定时任务重复执行以及并发修改申请单状态问题
Redis 分布式锁的底层方式可以讲一下
Redis 集群模式 3 主 3 从
持久化策略 AOF + RDB 混合模式
MQ 3 主 3 从
ES 3 主 3 从 3 个副片
线程池
- 配置文件:动态可变
常见面试题
- 1、redission lock
- 2、lock 的实现原理 看门狗机制
- 3、数据结构
- 4、为什么不适用原生的 setnx ,节点宕机锁失效 redlock、zookeeper 去解决
- 5、除了 redis 还有哪些可以做分布式锁
- 6、超时时间设置(使用 redission 的默认时间 30秒)
- 7、分布式锁的 key 怎么设计的
- 8、防重复提交代码具体怎么实现的
04 SQL,大表拆分
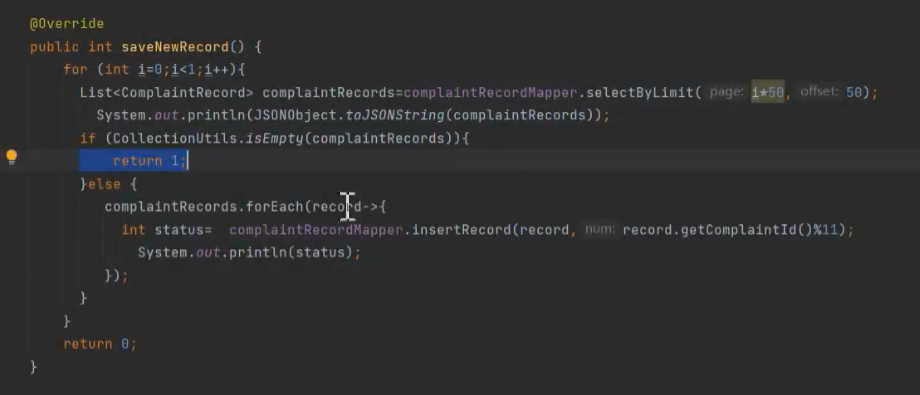
负责客诉监控平台日常检测 慢SQL 的调优以及针对个别大表制定拆解方案,
- 针对记录表,进行大表拆分:使用动态 SQL,进行批量插入迁移和新数据插入接口功能改造(拆分多表操作)
- 记录表(三千万数据量左右)
- 历史表(2年之前) + 物理删除 + 分表拆分(保证数据量在 2 -300万)
- SQL优化
- 1、隐式转换
- 2、分组
常见面试题
- 1、索引结构:索引的区别,hash 索引和 B+ 索引的区别,其他索引结构。
- 2、大表拆分是如何做的
- 1、通过记录表的关联业务ID(客诉单ID)进行取模操作,将旧数据迁移以及新数据插入功能改造 + 历史表
- 2、拆分为了 11 张表(保持一个平均的数据量)
- 3、为什么不分库分表:业务操作上已经满足需求了
- 4、为什么不使用 ES:记录表没必要放,ES占用内存,已经有很多数据了
- 5、慢SQL调优
- 6、Mysql 可重复读的情况下怎么解决部分幻读:+ 间隙锁
- 7、索引下推
05 分布式事务
组织其他部门讨论客诉核心创单接口涉及分布式事务的处理方案,并采用 rocketMq 半事务消息编写回滚逻辑。
客诉单生成 + 运单冻结 没有分布式事务问题
运单冻结 + 客诉单生成 分布式事务问题,这里不能保证 运单冻结这一步是成功的
运单冻结 + 客诉单生成 + 工单模板生成 → 分布式事务问题,所以当时考虑到成本问题,seata 组件引入依赖成本
- 但是当时考虑到引入这个组件的成本较高(其他部门也需要引入)
- seata rocketmq 弱一致性 → 技术选型(成本,组件引用)
- seat at 强一致性
工单模板生成 返回 true 或者 false ;根据返回值来进行事务回滚
针对分布式事务问题
- 场景一:运单冻结 + 客诉单生成 + 工单模板生成
- 使用 RocketMQ 的具体使用方式可以讲一下(多个接口时会产生分布式事务问题)
- 分布式事务:运单冻结 + 客诉单生成
- 工单模板生成:本地事务回滚
- 场景一:运单冻结 + 客诉单生成 + 工单模板生成
常见面试题
- 1、分布式事务场景
- 2、具体如何使用的(结合业务讲一下)
06 服务的拆分
参与对整个客诉平台的拆分,拆分成客诉平台,催收平台,申请单平台三个独立的微服务,方便职责划分和后期迭代
常见面试题
- 1、为什么要拆分
- 2、拆分遇到什么难点
- 遇到拆分不全的问题,后续是通过画整个流程图,然后根据业务去进行拆分操作
- 自测麻烦
- 拆分有没有引入什么设计模式
- 拆分之后怎么部署的
记录表没有拆分,远程调用,记录日志
其他拆分,进行了分库操作
- 上线问题
- 梳理逻辑(代码逻辑),本地调用改为远程调用
- 新老业务逻辑
- 设计模式(职责划分)
- 记录表
- 大表数据量大:多个线程:死锁
- 索引层数搞
07 线上问题
- 场景问题:广告问题,没有显示,排查到是Redis 的问题,然后发现是内存爆了、
- 创单接口高峰期频繁出现full gc问题(涉及八股)
独立定位线上redis内存溢出问题 以及创单接口高峰期频繁出现full gc问题和VM内存oom问题并解决。
- JVM 内存 OOM 问题定位

- Full GC 问题排查

触发条件

自适应调节策略




对于 JVM 相关的一些内容


待看一下 : fullgc话术.pdf
常见面试题
- 1、你有没有独立参与过 JVM 调优
- JVM 内存 40% 以下
广告弹窗
用户 ID
后台自动定时拉取:广告 ID + 位置信息 + json 信息
现象:运营发现客诉单界面上没有广告推送
排查:
- 1、先查看广告接口调用是否正常(这里是正常情况)
- 2、排查
- 原因:key 设置不过期,导致大量缓存数据堆积
- 解决方案:
- 临时方案:先通过模糊删除一个月的,先看是否能正常
- 解决方案:设置过期时间,更改内存溢出策略
Redis 内存溢出

客诉项目
运费收费:佣金
押金:司机给货主的保证金
用户类型:卡车,大型货物等
客诉是该中台下的一个服务
- 物流客诉中台
- 微服务模块:运单部门、交易部门、工单部门、客诉部门、货源部门、用户中江外呼部门,中间件团队,风控部门
类型
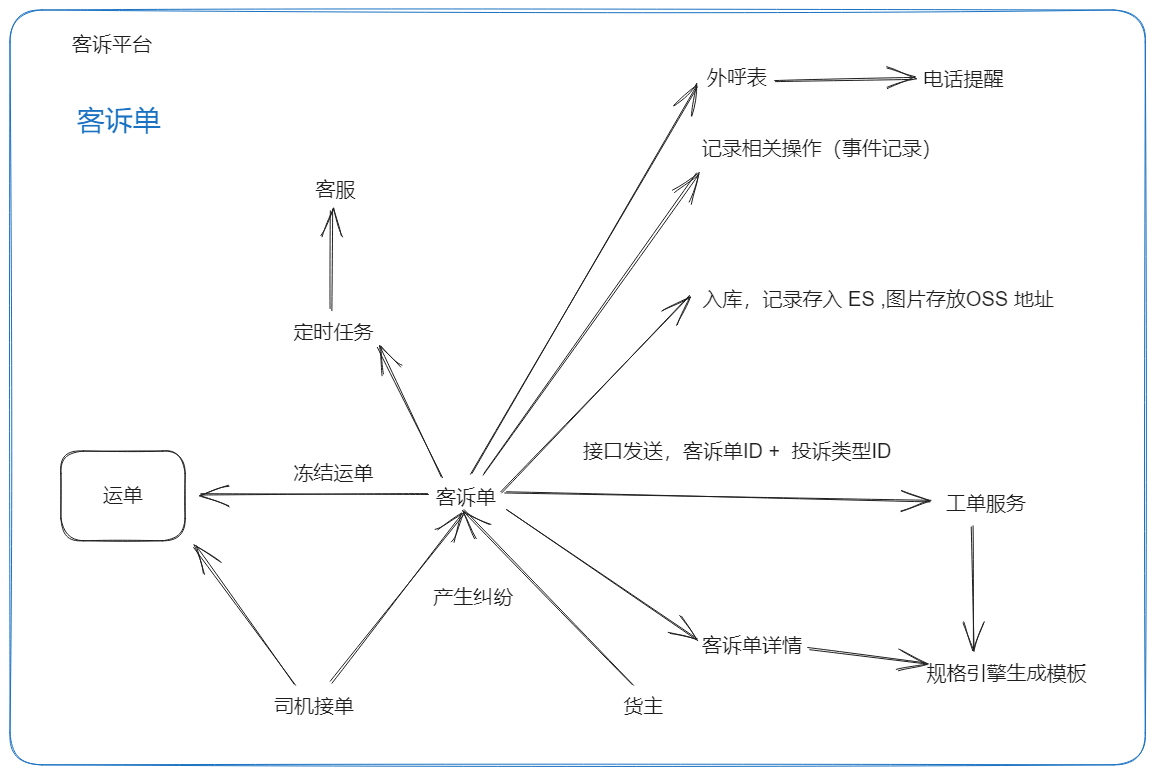
客诉单
当该客诉单处于【未处理】状态,司机/货主可以进行撤销操作
分配到客服手中,状态会被修改为【处理中】
对应的后台操作
- 1、远程调用运单服务,冻结运单
- 2、客诉单入库(数据库是1主2从)
- 3、图片入库(OSS 地址关联客诉单 ID)
- 4、客诉单ID → 详情信息 → 组装 ES 关键数据 → 存入ES
- 5、调用生成申请单接口(客诉单ID + 投诉单 ID 发送) → 工单部门 → 规则引擎生成模板
- 6、记录表记录事件内容
- 7、生成外呼表记录
- 8、定时任务:分配客诉单到客服手上
催收单
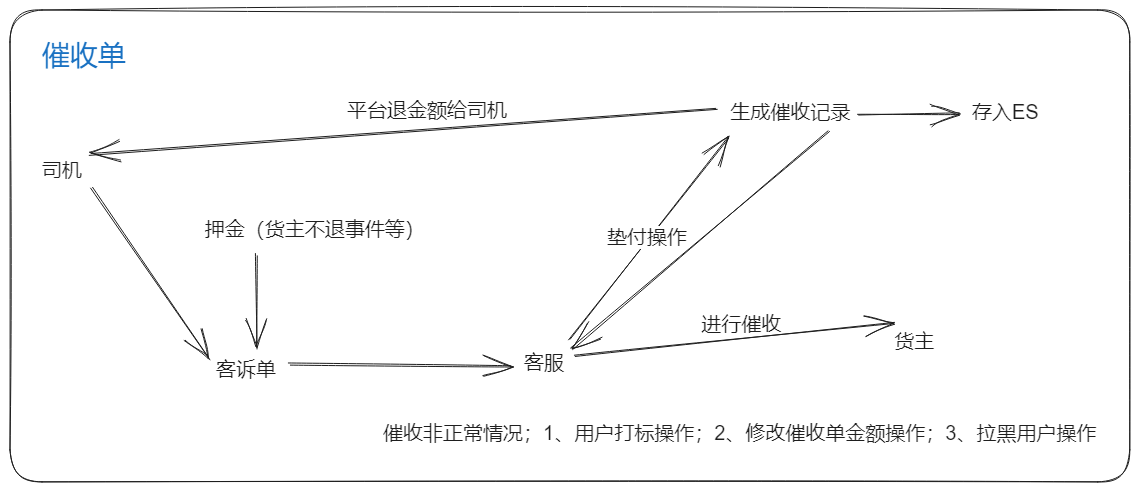
- 催收单(了解):相关表设计,业务功能,该业务代码怎么实现
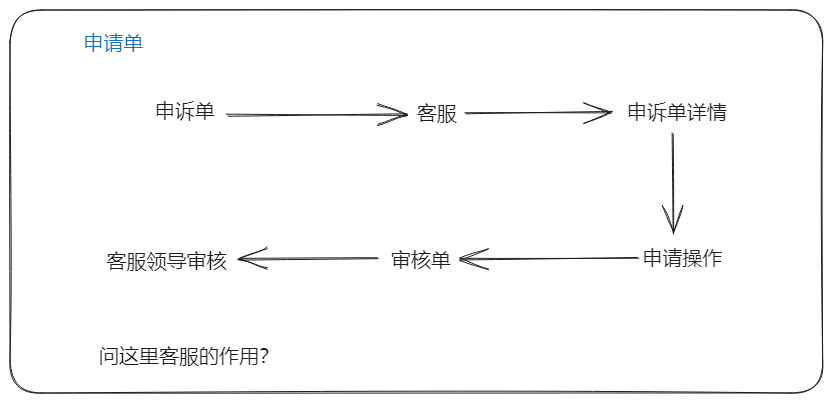
风控(高危单)
- 业务场景:非正常运单,司机和货主协商进行客诉,客服进行垫付正常金额1000;但催收的时候货主只愿意给500(中间贪墨公司 500)
- 在生成客诉单的时候,会调用风控接口监控用户风险等级,如果是高级,会直接发延时队列,30分钟后自动关单(保证交易开始进行)
申诉单
- 只有一次申诉机会
申请单
界面
创建客诉单
客服界面
该界面会从 ES 中查询出,详情是从数据库中查询(客诉单ID_主键ID)【VIP 用户会先优先处理】
首先司机或者货主或者客服创建客诉单,调用客诉部门客诉单接口创建客诉单,
创建后,数据库,ES 中有一条客诉单记录,然后后台定时任务,10分钟一次分配给客服,客服选出客诉单,点击详情进行审批判断是否要进行申请单操作
客服点击申请单,客诉申请单表保存一条记录,状态是审核中,然后将详情信息传到工单部门.
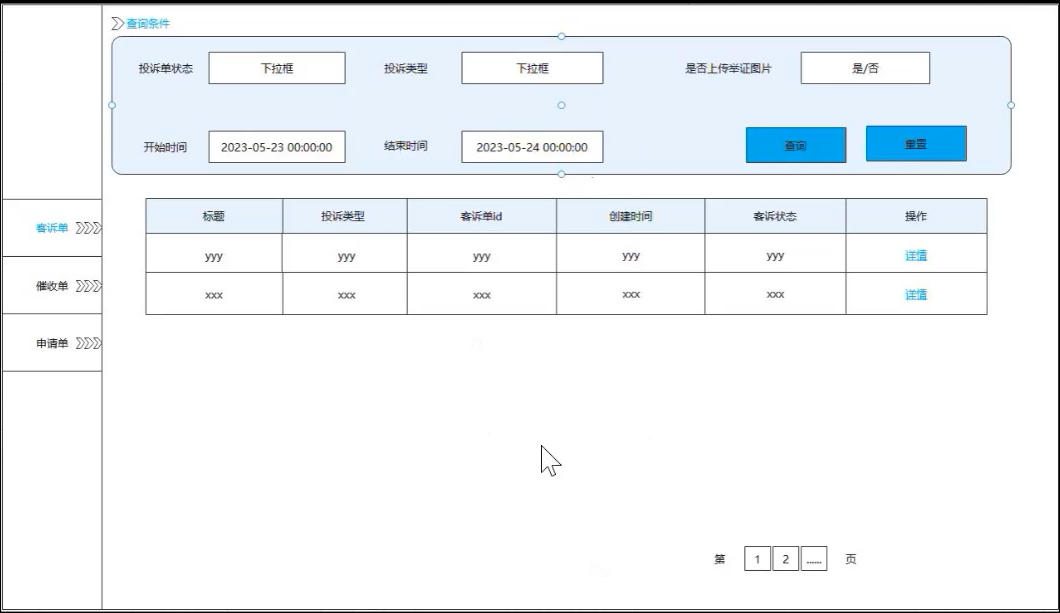
- 大数据根据客服状态和处理单量自动分配到客服
- 后台操作:定时将客诉进行分配
客诉单详情
- 提交的申请单,客服在这个界面也可以进行撤销操作

重开操作
- 重开操作指的是同一个运单,发生申请单完结后,司机/货主又重新发起一次客诉操作
- 从而进行申请单重开操作(同时有重开次数限制)
申请单
退佣操作
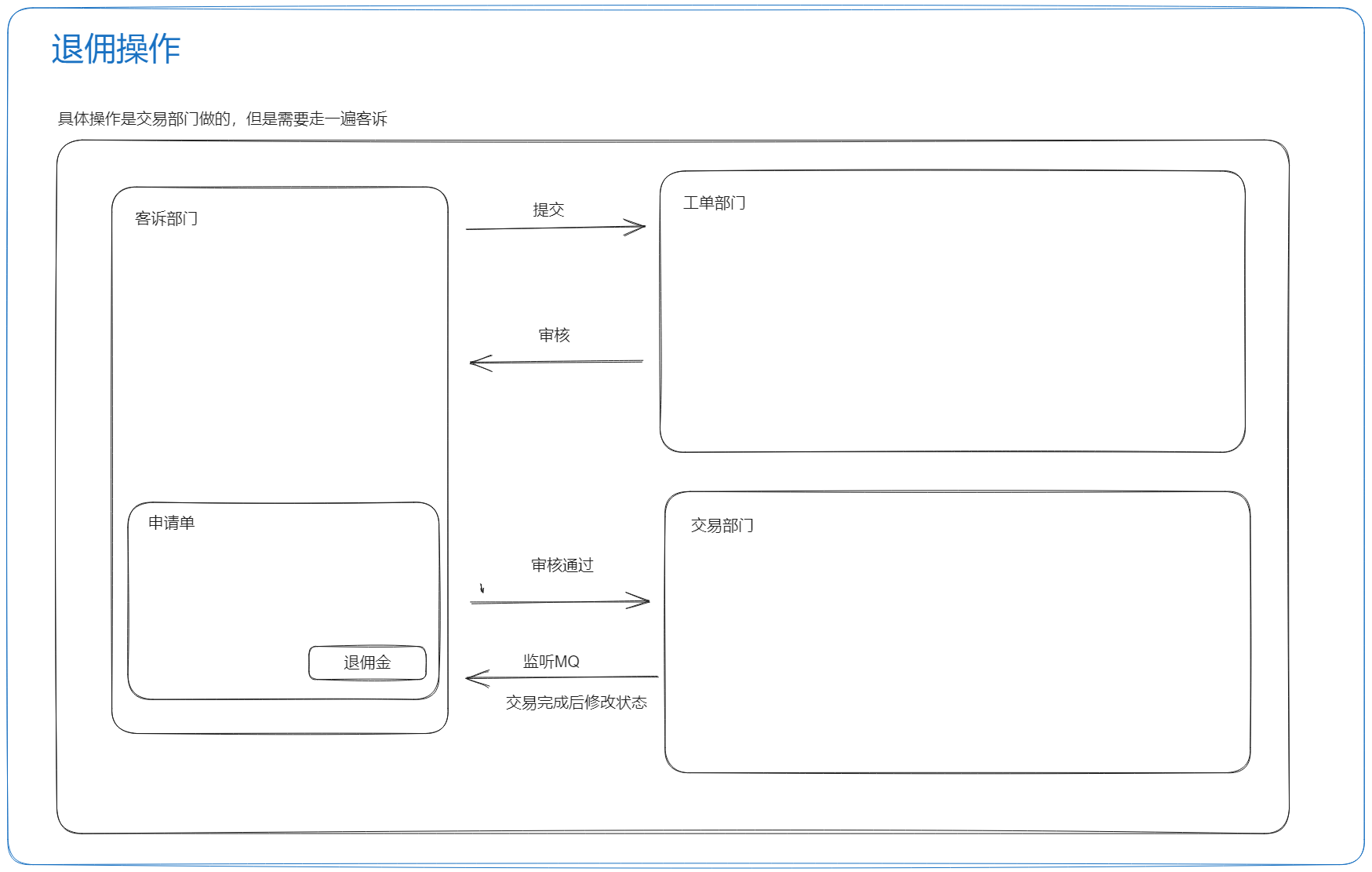
- 提供一个调用工单部门的接口
- 提供一个回传审核状态的接口
- 更新 ES + 更新申请单状态
- 退佣
- 审核通过
- 会发送一级或者两级领导审核的内容(根据佣金金额区分,大于 1000 需要 两级审核)
- 回传审核状态接口(如果是需要两级审核的时候,一级也会进行回传,进行一条记录,二级的话再进行后续操作)
- 监听MQ
- 插入记录表
- 自动关单
- 审核通过
业务操作
分布式锁场景
可能会问的一些问题
3、编写reds分布式锁,解决页面重复提交和分单定时任务重复执行问题,申请单并发修改状态问题。
- 描述一下为什么要使用分布式锁,或者不使用会怎么样,还有没有其他方式解决
- 其他方式:zookeeper,.数据库,数据库乐观锁
- 分布式锁
- 加锁原理(Redisson:看门狗机制原理)
- 为什么不使用原生的 redis 分布式锁
- 分布式数据结构
- 解决页面重复提交:代码怎么实现,不同的接口参数不一样怎么处理,项目中每个接口都有固定的参数和可变的参数,怎么获取方法参数值。
- 节点宕机导致锁丢失。Redlock加锁原理,
- 分布式锁的key怎么设计的。
- APPLICATION_申请单_id。
- Redisson 是不是可重入锁
退佣操作
进行退佣操作的时候,客服是可以进行撤销的操作,撤销和工单部门的审核两个操作(两个操作都是会对退佣操作的表状态【客诉单状态】进行修改的),这里是需要加一个分布式锁,保证同一时刻只能进行一个操作(保证原子锁)。
- 这种情况下使用数据库的乐观锁也可以考虑使用
撤销的时候,查询数据库状态,如果是审核中状态,则可以操作(保证查询和修改是原子性)
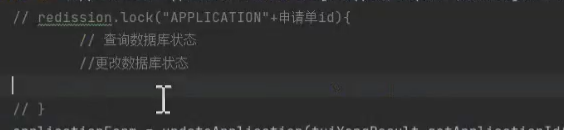
- 这里的 lock 实际使用的数据结构是 hash 结构 key uuid + 线程名称 次数
- 分布式锁场景
- 页面重复提交,定时任务重复执行,更改申请单状态
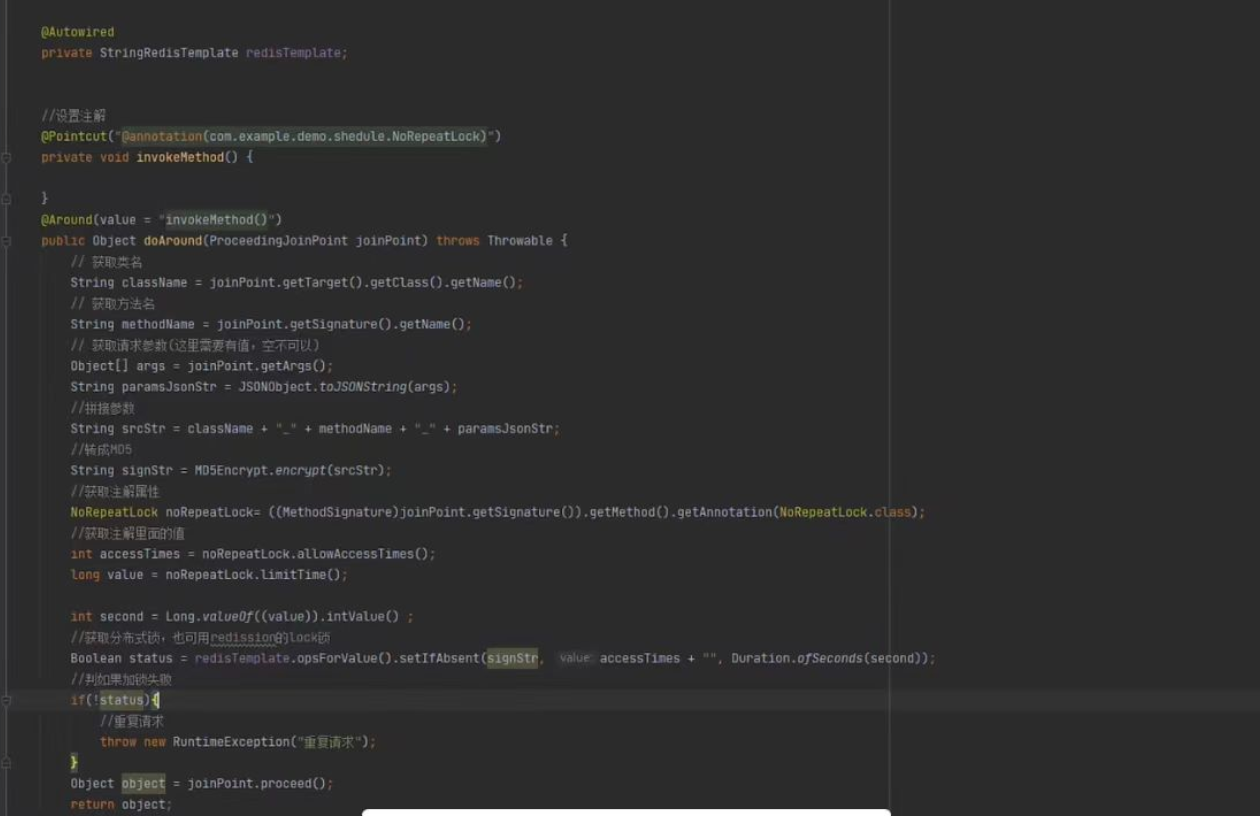
重复提交 AOP 代码
- Around 注解方法
- ProceedingJoinPoint 类
- 类名 + 方法名 + 参数
- 这里可以说我们设置的方法中会给定一些公参,比如客服ID 之类的
拉黑操作
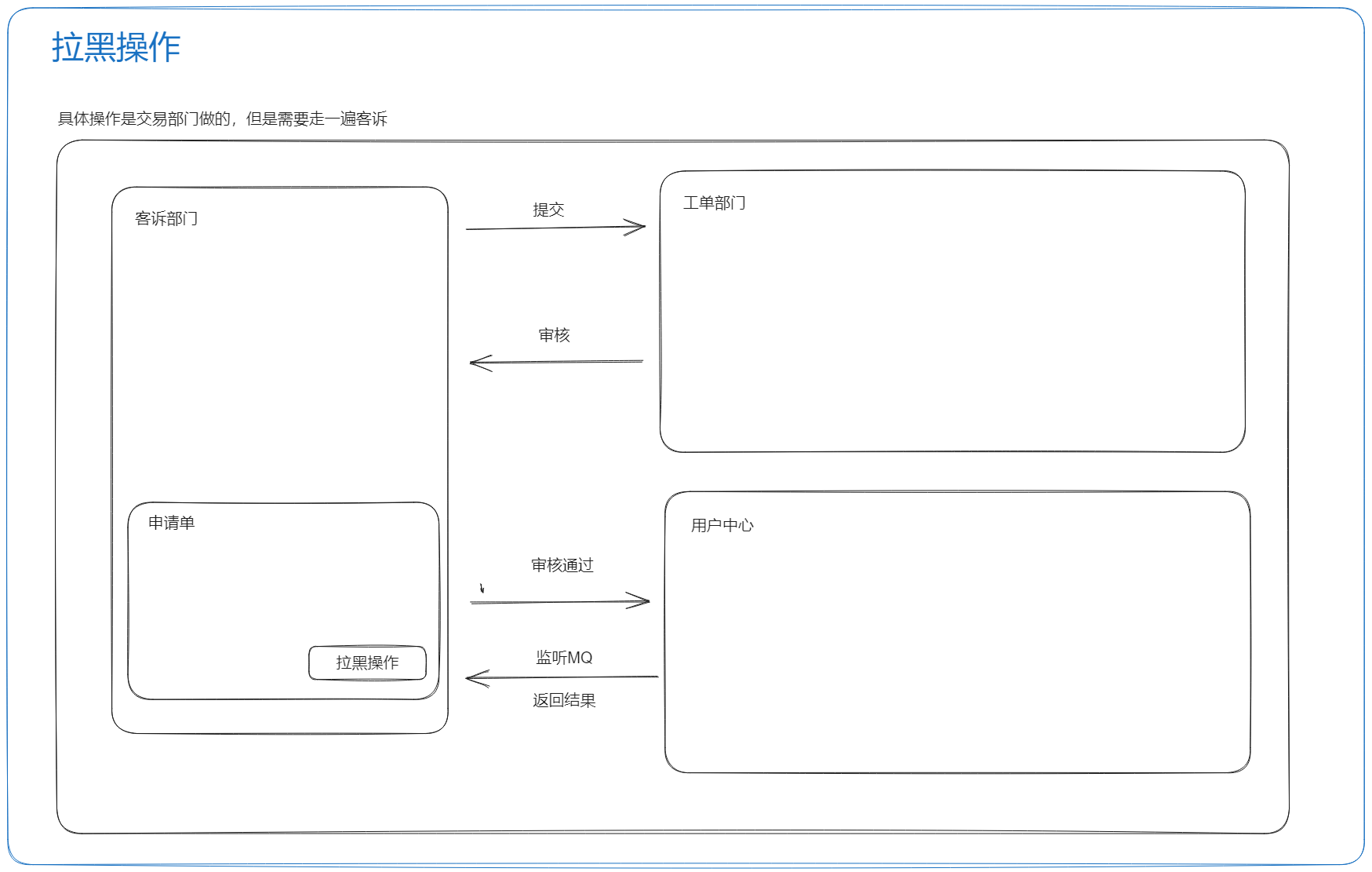
分布式事务场景
创建客诉单 + 冻结运单
1、使用的方式是通过 RocketMQ 的半事务消息二阶段提交方式进行
2、场景
- 2.1 创建客诉单后面的一些操作,如果有异常,进行事务回滚
- 冻结运单这里使用了分布式事务,创建工单这里没加(可以说从业务上考虑,当时主要的问题是:客诉单创建 + 冻结运单 这里使用了分布式事务;创建工单由于是调用接口的方式去进行,接口的并发性小一点,出现的分布式事务问题较少一些;解决方案:可以通过 seata 的方式,但是当时考虑到引入这个组件的成本较高(其他部门也需要引入);而且当时考虑到出现事务问题,工单那里也就是出现一条脏数据,其实影响不大)
- 客诉:高峰期有时候几百左右,客户:几十万左右;注册用户:70左右,活跃用户:十几万。
5、参与讨论客诉核心接口涉及分布式事务的处理方案,并采用 rocketMg 半事务消息编写回滚逻辑。
- 这个分布式事务是怎么出现的 ?
- 之前用户比较少,这种现象不多,一般一星期最多一次,然后都是靠运单和客诉手动修改数据库一些操作处理,后面用户多了,或者高峰期,出现频率较大,一星期好几次用户反馈。
- 通过这个反馈用户的id, 找到 传单失败的接口
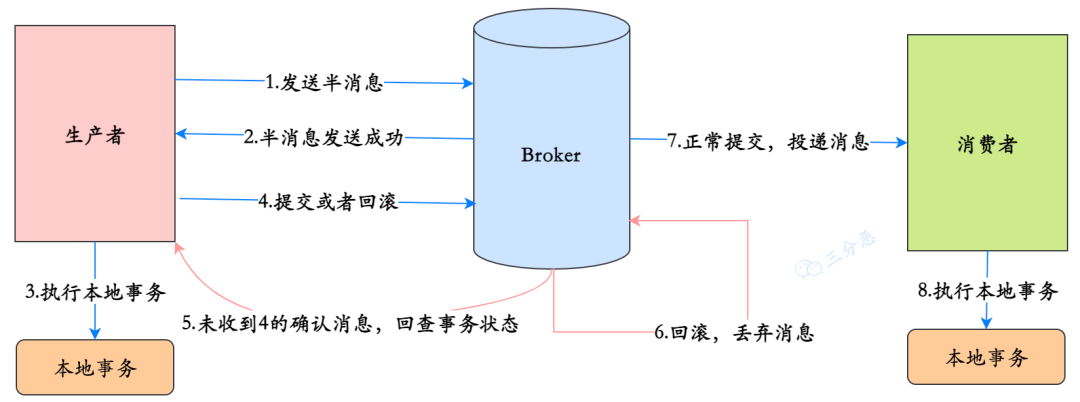
代码实现:看一下
消费者这里的常见操作
- 1、监听有重试机制 3次
- 2、定时重试
客诉单详情
接口优化
- 客服反馈:存在接口慢的现象,然后产品分配这个给你
- 详情优化:先通过链路追踪工具查看,哪个节点耗时多,然后再进行优化操作
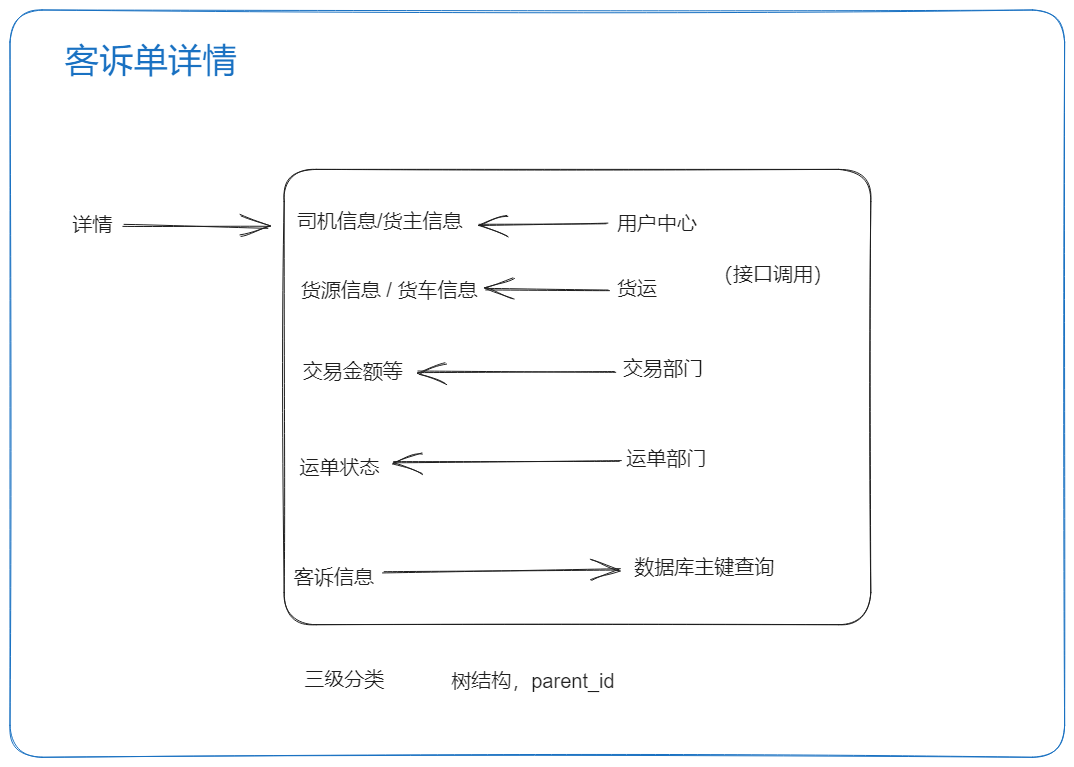
2、对客诉详情整个大的接口进行优化,由之前的4-5秒响应,优化到2秒左右响应
可能会问的一些问题
- 怎么优化的,为什么考虑优化这里,多线程里面子线程出了异常怎么感知,涉及多线程的一些八股文
- 线程池参数怎么设置的
- redis:如何和数据库保持一致性,详情页为什么需要三级分类:string底层数据结构
- 还有哪些地方用到了redis 数据结构,
- set:存 mq 重复消费(场景)
- hash 底层数据结构
- 页面广告拉取(场景)
- Hash:手机安卓和ios pc,用户的年龄段,广告详情配置,最终拉取广告还是请求广告平台
- 一个请求到页面展示经历了哪些流程
- DNS 域名解析 http tcp
SQL 优化
4、负责监控平台检测日常慢 sql 的调优以及大表的拆解。
token 12345 47832 varchar 88万条时间在5-30多秒 type all
- 类型 where a = 123 (索引失效)
其他一些优化,代码中有一些关联查询没有小表驱动大表导致耗时 2s,
原生的 sql 调优怎么实现,开启 慢 sql ,2 种 方式,explain, discribber,执行计划有哪些字段
extra 文件排序 filesort ,id,type
索引失效还有哪些场景,建立索引如何考虑,索引下推
为什么类型不匹配会索引失效,为什么要符合最左匹配原则
- a b c b= 1 and a = 2 and c = 2; b = 1 and c = 2; a = 1 b =2 ; b = 2 and a = 1
代码中有一些关联查询没有小表驱动大表导致耗时
- 为什么需要小表驱动大表
大表的拆解
- 为什么不使用分库分表:
- 风险太大,对整个项目改动比较大
- 以前项目没有分库分表,只做了读写分离,1主 2 从,对整个项目进行分库分表主键需要重新设计
- 很多主键已经被其他部门所依赖。
- 考虑到风险太大,记录表 id 客诉单 id 事件 创建时间 detail
- 为什么需要拆分
- 怎么拆分的
- 11 张表,通过客诉表 Id 取模,用了 mybatis 动态表名 sql ${}
- record_${}
- 为什么是 11 张,
- 客诉单表有 400 万条数据
- 有一张历史表,客诉单会定期把5年前的数据转移到历史表,一个客诉单大概对应8条数据,3200万11每张记录表在300万左右。
- 原记录表数据怎么迁移的(迁移到历史数据)
- limit 50000 一批
- 通过定时任务扫描
- 多线程(分批插入)
- 一次性批量插入 1000 条
- 20000 条一个线程处理,按照 1000 一批
- For(i < 10)
- 11 张表,通过客诉表 Id 取模,用了 mybatis 动态表名 sql ${}
- 为什么不使用分库分表:

服务拆分
参与对整个客诉平台的拆分,拆分成落诉平台,催收平台,申请单平台三个独立的微服务,方便职责划分和后期迭代
- 怎么业务拆分
- 拆分不全问题,拆分难点,测试怎么做的
- 怎么实现服务切换
- 开一个开关,写两套逻辑,正式上线后去掉老逻辑(开关控制)
记录表(大表拆分操作)
关键词:动态 SQL,分批插入
数据量超过 1 千万
拆分为 11 张表
- cp_record_1
- cp_record_2
创建数据可以考虑使用存储过程(百万数据)
动态 SQL 分批插入,这里主要的一个技术点是这个动态SQL cp_record_${sum} 的方式(待实践一下)
查询,然后进行批量插入即可(实际拆分的时候)
查询的时候需要考虑到避免索引失效场景
- 业务场景:考虑到记录表的数据量太大,由于业务量的持续增大,当时进行拆分表操作
- 1、将旧数据进行迁移到了新表(cp_record_xx)
- 先批量查,再通过动态 SQL 进行插入(通过取余获取后缀)
- 2、新增数据,方法需要更新(切换新方法)
- 1、将旧数据进行迁移到了新表(cp_record_xx)
疑问:
- 1、关于拆表之后,查询操作的改动?【这里应该还是根据客诉单ID之类的键值去查】
OOM
- 分析工具
- VisualVM:dump 文件
- MAT
- 实践一下分析流程
MQ 重复消费
- 场景:
- 解决方案:通过业务唯一性 ID 保证操作幂等性。
分布式ID
- 业务场景:拆分 ID
- 美图 leaf
- 前缀 + 数字13 位数字代号
- 客诉单
- 业务 ID ,自增ID
- 查询操作一般使用的 业务 ID
设计模式
- 模板
- 申请单创建的步骤 → 使用模板设计模式
- 工厂(简单工厂模式,工厂方法模式,抽家工厂模式)
- 单例(双重检加 volatile )
- oom 问题
- okhttpclient, 通过这个可以实现第三方接口的调用
- https://blog.csdn.net/weixin_45112292/article/details/134726024
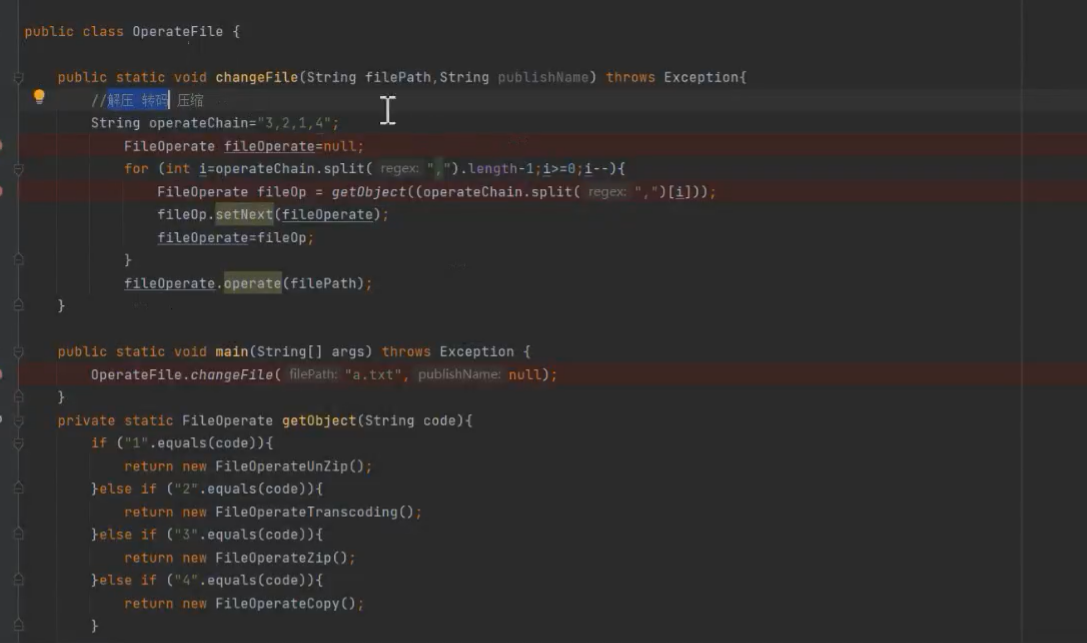
- 责任链
- 动态代理模式
- 生产者消费者模式
工厂 + 模板:视频 5
责任链
文件交换功能(之前的业务功能)