Appearance
提前准备
遇到了哪些比较棘手的问题,怎么解决的
!! 提前准备
需要提前准备,重要度偏高,一般情况下问起项目的时候会问你有没有什么印象深刻的地方,你需要说一下:
- 1、当时的业务背景,遇到了什么问题(技术问题);
- 2、过程,在遇到这个问题你的解决思路和解决方案说一下(解决问题的过程);
- 3、最终落地方案。(形成一个完整链路,并清晰表达出来)
建议准备的一些点:
- 1、设计模式
- 一般是工厂、策略、责任链... 等
- 阐述回答建议:先说一下改动和改动之后的一个比对,在没有使用到设计模式之前,会出现什么问题(比如需求经常变更,代码冗余程度较高,维护程度困难等);通过实际调研,对代码进行了优化,后续的一个效果。
- 2、线上 Bug
- 在线上出现了:CPU 飙高、内存泄漏、线程死锁... 等
- 可能情况是:
- 测试环境没问题,生产上线后出的问题,且问题不好在测试环境复现
- 生产上线初期没问题,上线一两个月后出现这种问题
- 这种情况需要线上调试和排查(通过这种问题反馈你的实际处理经验和复盘,当时是如何操作的)
- 3、调优
- 慢接口、慢SQL、缓冲方案 ... 等
- 可以将你的实际操作,包括如何排查出这个接口的处理速度慢,从多少秒调优到了多少 ms 这种程度。
- 4、组件封装(不建议,一般是高级工程师操作)
系统登录
分布式认证授权
参考: https://www.bilibili.com/video/BV1nG4y1d7mf
讲一下单点登陆的实现
单点登录的英文名叫做:Single Sign On(简称SSO),只需要登录一次,就可以访问所有信任的应用系统
在单个 tomcat 中,session 是共享的,但是在多个 tomcat 服务中,session 是不共享的;
在这种情况下,常用的解决方案有:JWT (常见)、OAuth2、CAS (框架)
一般使用的是 JWT 的方式:
登陆流程分析:
- 用户登陆
- 用户向认证服务器发送登录请求,通常包括用户名和密码。
- 认证服务器验证用户的身份。如果认证成功,服务器会使用一个密钥生成一个包含用户信息(如用户ID、角色等)和其他声明的JWT。然后,将这个JWT返回给用户。
- 访问资源
- 用户带着JWT访问应用中的受保护资源。JWT通常在HTTP请求的 Authorization 头中以Bearer token的形式发送。
- 应用服务器接收到请求后,会提取JWT并验证它的有效性。验证包括检查签名是否有效、令牌是否过期等。
- 如果JWT验证成功,服务器就会根据令牌中的声明处理请求,比如返回用户请求的数据。
- 使用JWT进行单点登录
- 在单点登录系统中,一旦用户在一个应用中登录并获取了JWT,他们就可以使用同一个令牌访问系统中的其他应用,而无需重新登录。(一般是网关进行验证,通过后访问具体服务)
- 当用户尝试访问另一个应用时,他们的浏览器会发送包含同一个JWT的请求。
- 第二个应用也会验证JWT的有效性。如果验证通过,用户就可以访问第二个应用的受保护资源,实现了单点登录。
- JWT 的刷新
- 为了安全起见,JWT通常会设置较短的过期时间。认证服务器可能会提供一个刷新令牌(Refresh Token)机制,允许用户在JWT过期后,无需重新登录就能获取一个新的JWT。
- 一般访问令牌和刷新令牌都会存放在客户端的内存中(一种常见的做法是将刷新令牌存储在HttpOnly的Cookie中。HttpOnly Cookie由于无法通过JavaScript访问)
- 在发送请求到服务器时,客户端会从存储中获取访问令牌,并将其放入HTTP请求的Authorization头中,通常采用
Bearer <token>的格式。
讲一下 Jwt 的组成,使用 jwt 的优势有哪些
登陆注销是怎么使用的,为什么不适用 sesson 而使用 jwt
使用账号密码访问流程(JWT 方式)
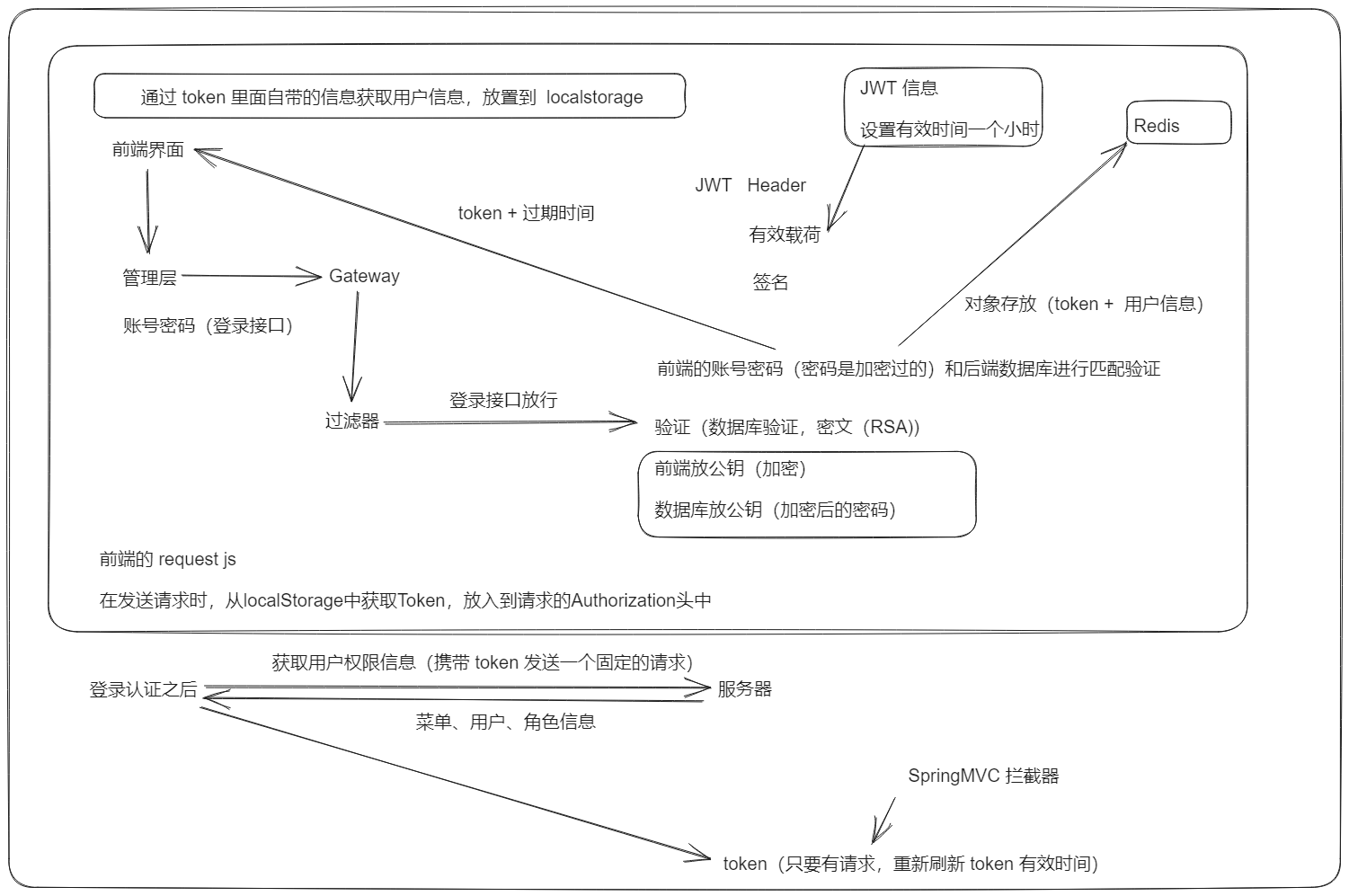
权限控制,数据安全
你们项目中权限认证是如何实现的
最常见的就是 RBAC 模型来指导实现权限
RBAC(Role-Based Access Control):基于角色的访问控制,一般是有3个基础部分组成:用户、角色、权限。
具体实现
- 5张表(用户表、角色表、权限表、用户角色中间表、角色权限中间表)
- 7张表(用户表、角色表、权限表、菜单表、用户角色中间表、角色权限中间表、权限菜单中间表)
常用的权限控制框架:Spring security
上传数据的安全你们是如何控制的
使用非对称加密(或对称加密),给前端一个公钥让他把数据加密后传到后台,后台负责解密后处理数据
- 文件很大建议使用对称加密,不过不能保存敏感信息
- 文件较小,要求安全性高,建议采用非对称加密
考虑数据传输的话,可以从很多方面考虑,主要是你当初考虑的点,当时遇到了什么问题,然后通过什么方式去解决的。
- 1、考虑权限认证
- 2、考虑文件类型限制,考虑大小限制
- 3、内容检查(不建议说,不太了解)
- 4、使用安全连接 HTTPS
- 5、上面说的数据加密,可以谈一下关于对称加密和非对称加密的一些用法,当时技术选型是怎么做的,为什么选择了使用这一种加密算法(提前准备一下)
日志
你们项目中日志是怎么采集的
为什么要采集日志:日志是定位系统问题的重要手段,可以根据日志信息快速定位系统中的问题
一般日志的采集方案有:
- ELK:即Elasticsearch、Logstash 和 Kibana三个软件的首字母(不建议回答这种,看你项目实际使用情况)
- 常规采集:按天保存到一个日志文件
常见日志的命令
一般我们会在日志配置文件中,比如 logback 配置中定义每天产生日志存放到一个文件中
在 Linux 系统中,我们查看日志文件的一些常用命令:
- 实时监控日志的变化
- 实时监控某一个日志文件的变化:
tail -f xx.log - 实时监控日志最后100行日志:
tail -n 100 -f xx.log-n 100:首先显示xx.log文件的最后100行内容。
-f:之后,随着xx.log文件的增长,新添加的内容会被实时显示。
- 实时监控某一个日志文件的变化:
- 按照行号套询
- 查询日志尾部最后100行日志:
tail -n 100 xx.log - 查询日志头部开始100行日志:
head -n 100 xx.log - 查询某一个日志行号区间:
- 查询100行至200行的日志
cat -n xx.log|tail -n +100|head -n 100
- 查询100行至200行的日志
- 查询日志尾部最后100行日志:
- 按照关键字找日志的信息
- 查询日志文件中包含debug的日志行号:
cat -n xx.log|grep "debug"
- 查询日志文件中包含debug的日志行号:
- 按照日期查询
sed -n '/2023-05-18 14:22:31.070/,/2023-05-18 14:27:14.158/p' xx.log
- 日志太多,处理方式
- 分页查询日志信息:
cat -n xx.log|grep "debug" |more - 筛选过滤以后,输出到一个文件:
cat -n xx.log|grep "debug" > debg.txt
- 分页查询日志信息:
正常微服务接口报错写入日志是怎么操作的
系统设计
接口幂等
建议不要使用分布式事务组件
参考: https://www.bilibili.com/video/BV1g84y1s7DH
数据库 🚩
一张已经百万级别数据量的表,需要改一下字段结构或者索引,有什么合适的方式
分表
参考: https://www.bilibili.com/video/BV1rg411x7zK
讲一下你当时水平分表遇到的问题,以及怎么解决的
生产问题
生产问题怎么排查
已经上线的bug排查的思路:
- 1,先分析日志,通常在业务中都会有日志的记录,或者查看系统日志,或者查看日志文件,然后定位问题
- 2, 远程debug(通常公司的正式环境(生产环境)是不允许远程debugl的。一般远程debug都是公司的测试环境,方便调试代码)
使用 IDEA 远程 Debug 服务器的 Jar 包方法可以看一下相关教程(需要本地代码和服务器打包Jar代码保持一致)
可以大概说一下先日志排查,然后再进行测试环境远程 Debug 调试看出现的问题。
怎么快速定位系统的瓶颈
- 压测(性能测试),项目上线之前测评系统的压力
- 压测目的:给出系统当前的性能状况;定位系统性能瓶颈或潜在性能瓶颈
- 指标:响应时间、QPS、并发数、吞吐量、CPU利用率、内存使用率、磁盘 IO、错误率
- 压测工具:LoadRunner、Apache Jmeter…
- 后端工程师:根据压测的结果进行解决或调优(接口慢、代码报错、并发达不到要求)
- 监控工具、链路追踪工具,项目上线之后监控
- 监控工具:Prometheus+Grafana
- 链路追踪工具:skywalking、Zipkin
- 线上诊断工具Arthas (阿尔萨斯),项目上线之后监控、排查
- 官网:https://arthas.aliyun.com/
- 不建议说,不太了解的话。
一般还是建议从如何监控线上,排查出对应的问题,然后如何解决的去回答。
CPU 飘升如何定位到代码
参考: https://www.bilibili.com/video/BV1sP4y1F76s
项目上线之后,CpU飙升,居高不下。触发报警。我们该如何排查问题所在?
传统的查看日志的方式
- 1、top
- 2、ps -mp
- 3、tid转换
- 4、jstack打印
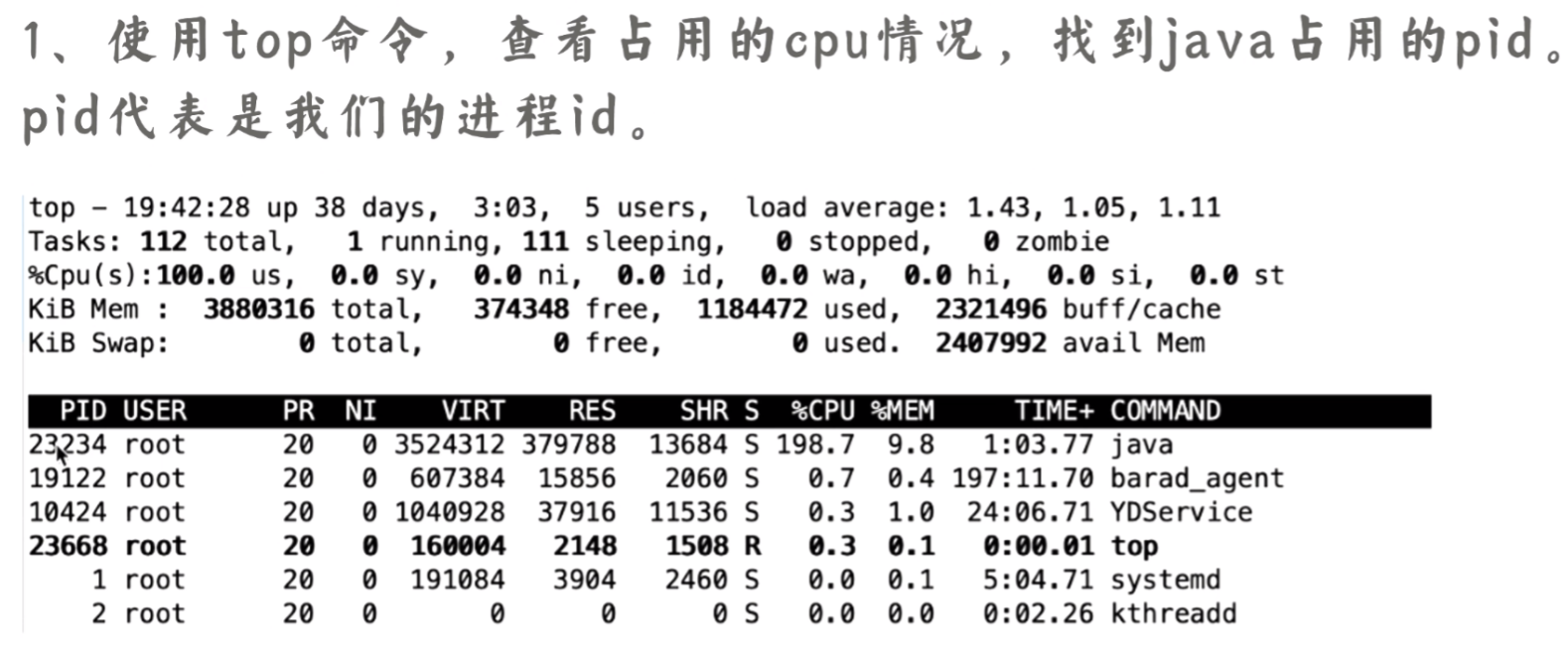
查看线程下进程占用 CPU 情况,TID 需要转换为 16 进制信息
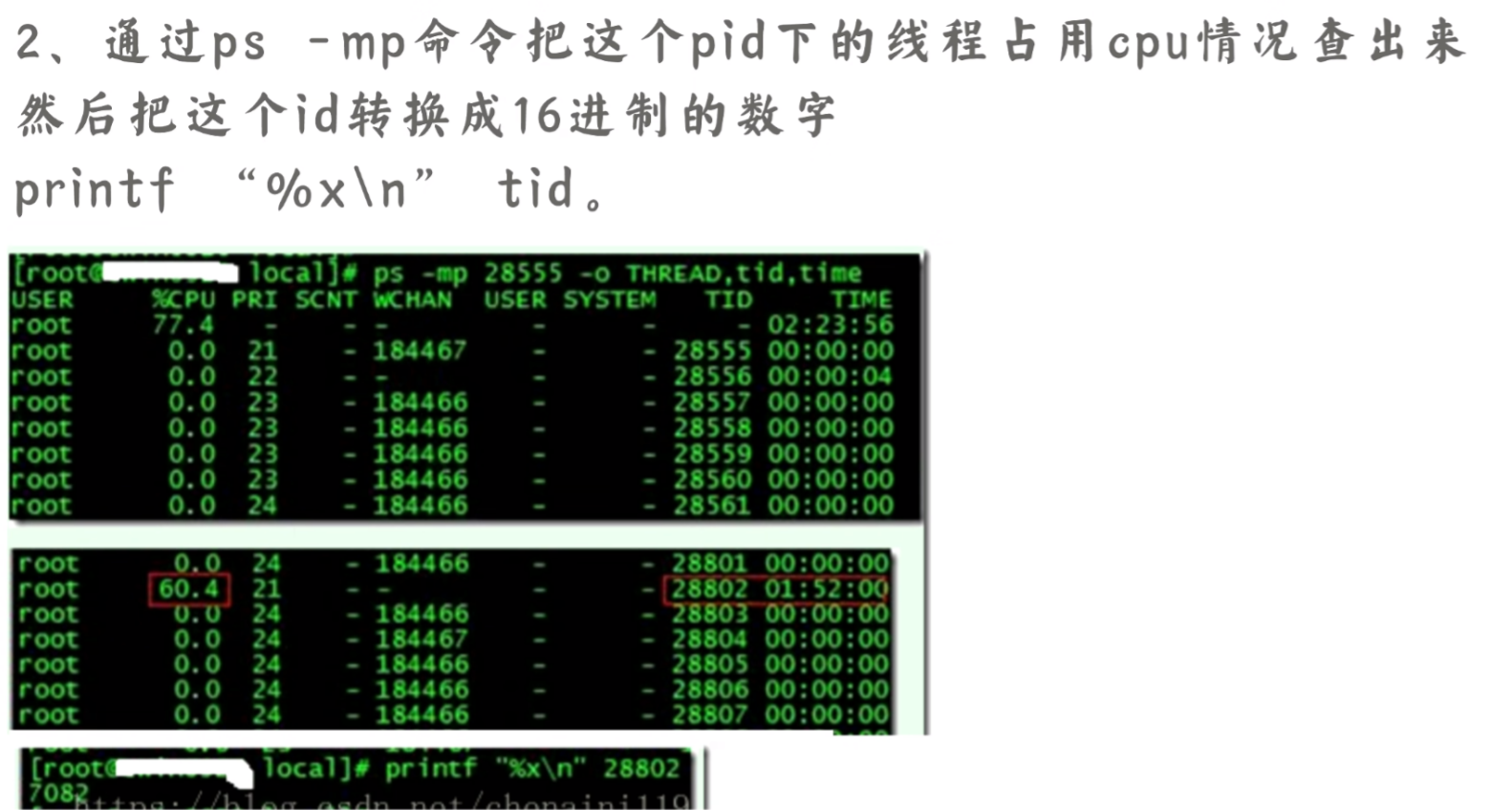
根据 线程 PID 和进程 TID 查看到进程的运行状态日志
或者火焰图的方式
线上服务内存溢出如何排查定位
- jmap (Memory Map for Java)命令用于生成堆转储快照。就是我们常说的dump文件,我们可以手动执行命令来生成dump文件。还可以使用JVM参数来配置自动生成
- 自动生成
- XX:+HeapDumpOnOutofMemoryError, 可以让虚拟机在OOM异常出现之后自动生成dump文件
- -XX:HeapDumpPath=path设置dump文件路径
- 手动生成
- jmap -dump:format= b.file = heap.hprof.pid
- jmap 除了生成dump也可以看到 jvm堆的数据占用情况。

根据 进程 PID 生成对应的 dump 文件
生成的时候,需要将流量关掉,生成 dump 的过程中服务会停止,不会向外提供服务

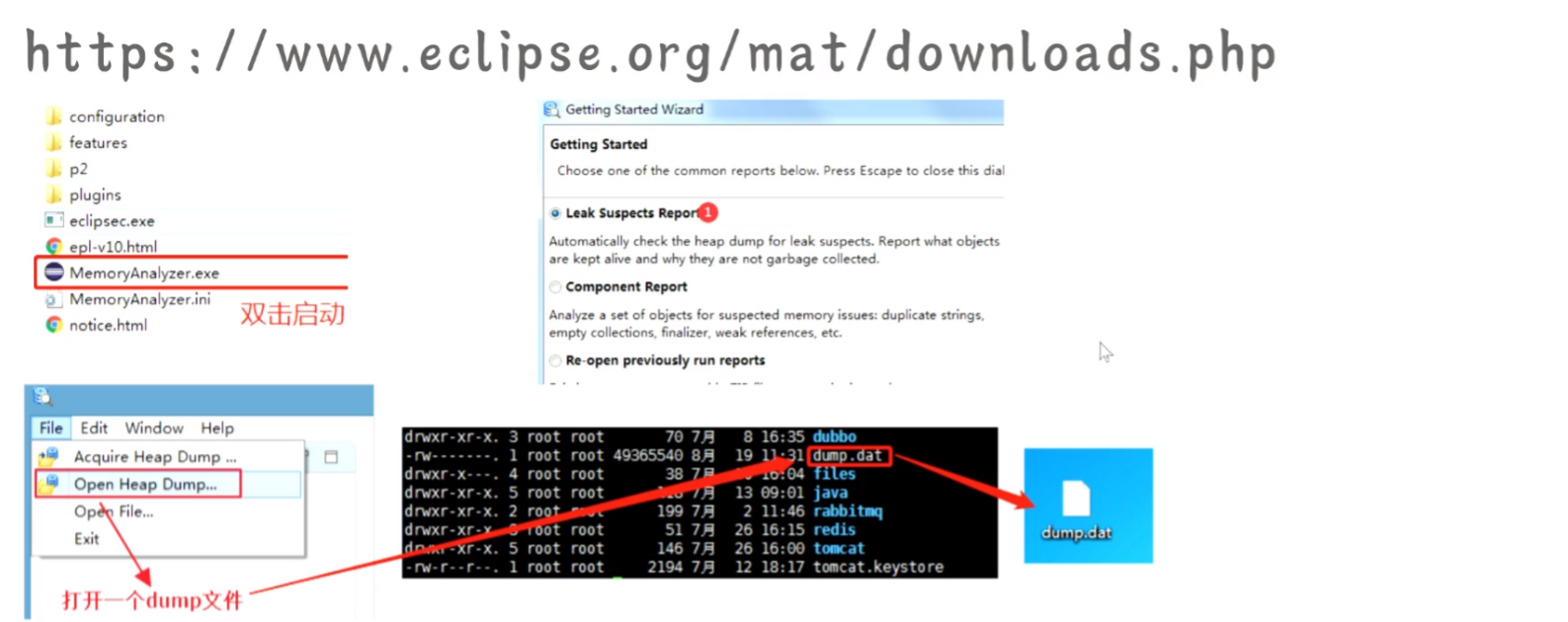
通过 MAT 工具进行分析处理
- 进入下载后的文件夹,双击 MemoryAnalyer.exe 启动,进行打开 dump 文件,选择对应 dump.dat 文件,选择第一个 Leak Suspect Reports,生成一个报告操作
- 选择 Dominator Tree
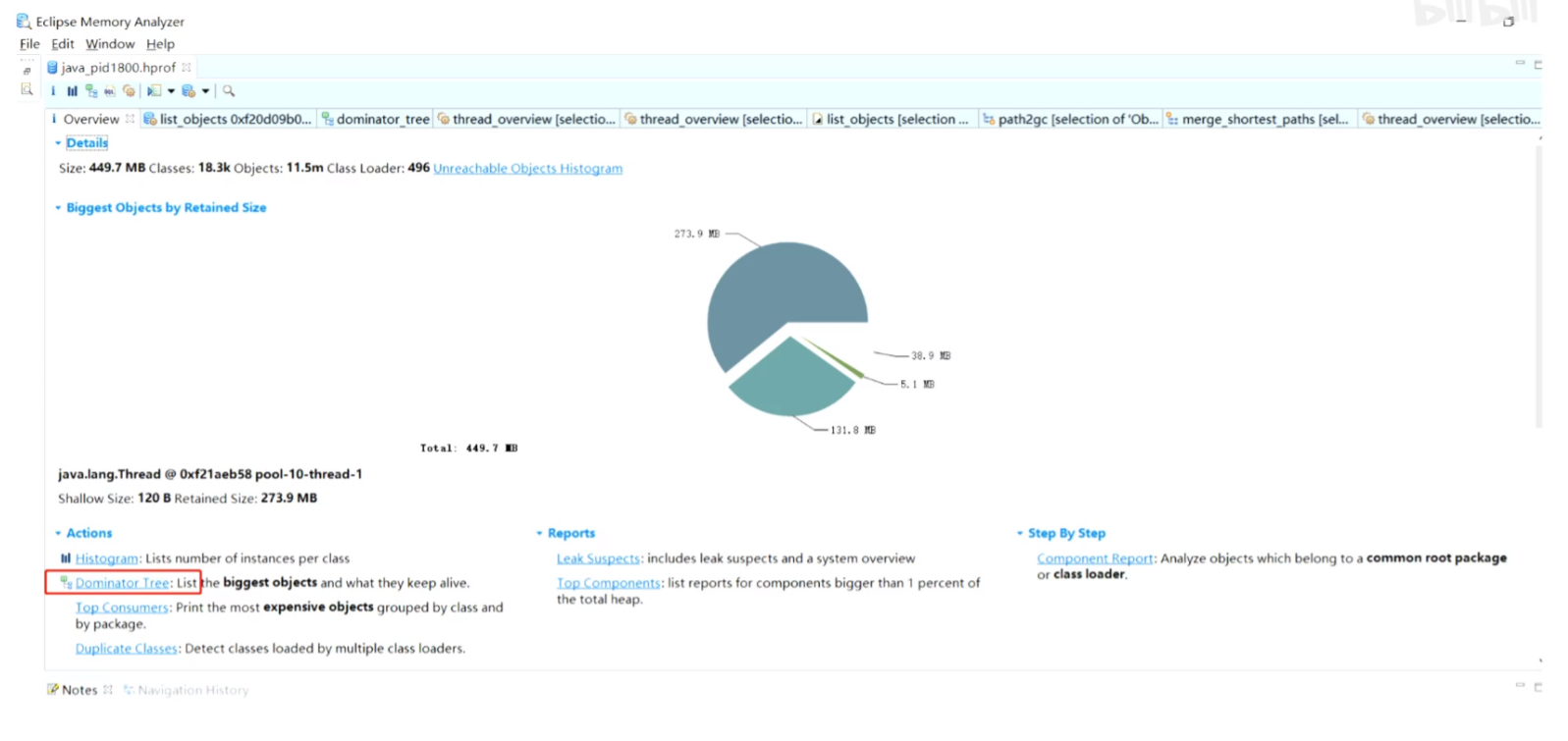
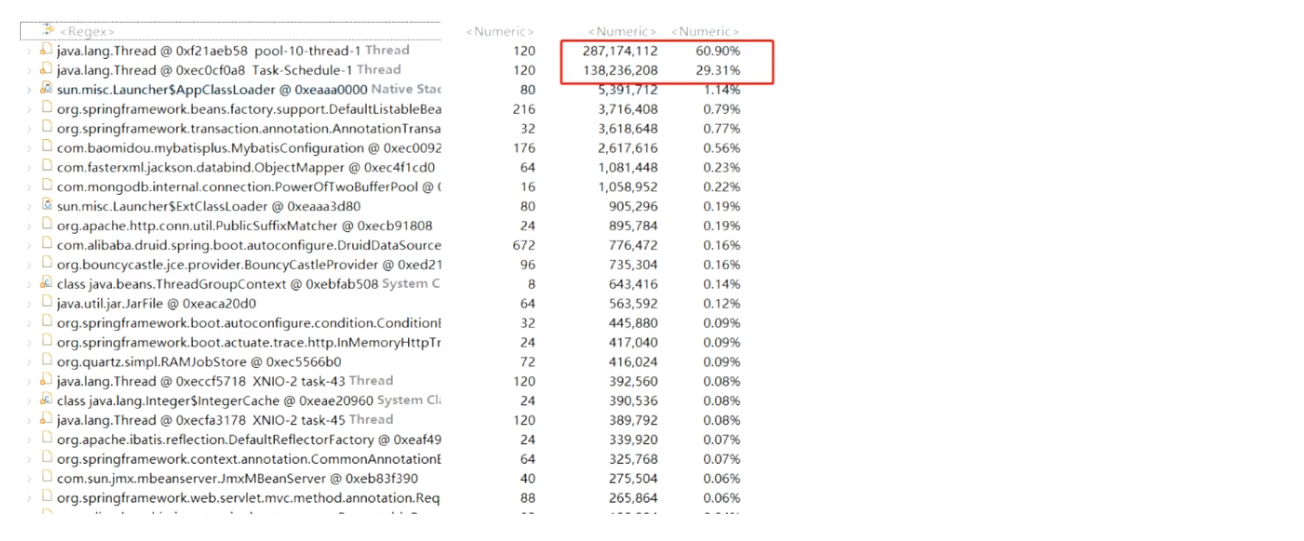
进入,查看占用内存情况
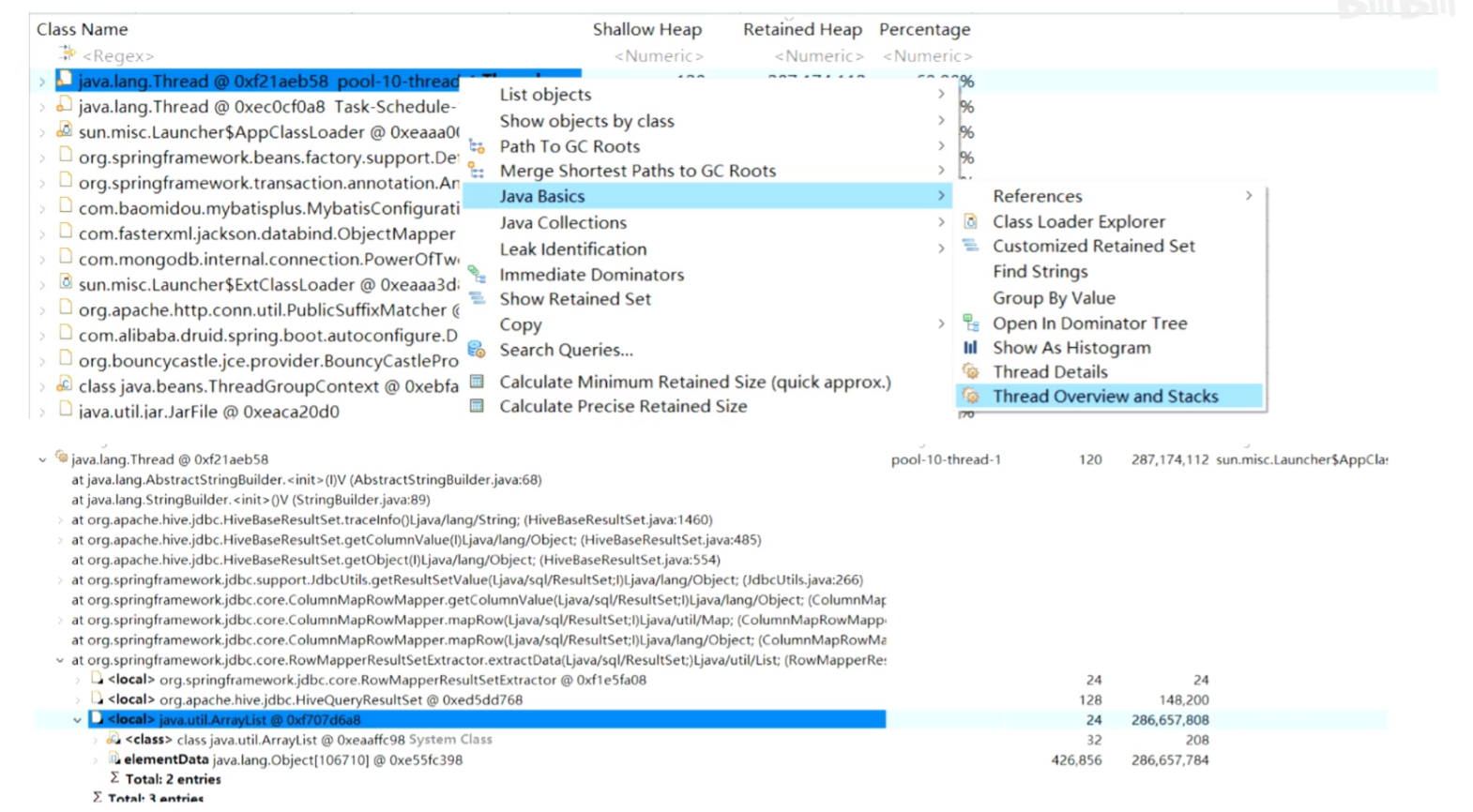
右键查看 → Java Basics → Thread Overview and Stacks 查看线程以内的情况
VisualVM 工具
生成 dump 文件:
- 一般是设置 JVM 参数,有时候程序是直接闪退挂了,不太可能让你运行的时候使用 jmap 命令(使用 vm 参数获取 dump 文件)

分析 dump 文件
- 1、打开 VisualVM
- 2、选择:文件 → 装入 → (选择文件) → 打开
- 3、概要 → 堆转储
- 4、通过查看堆信息的情况,可以大概定位内存谥出是哪行代码出了问题
业务问题
库存扣减问题

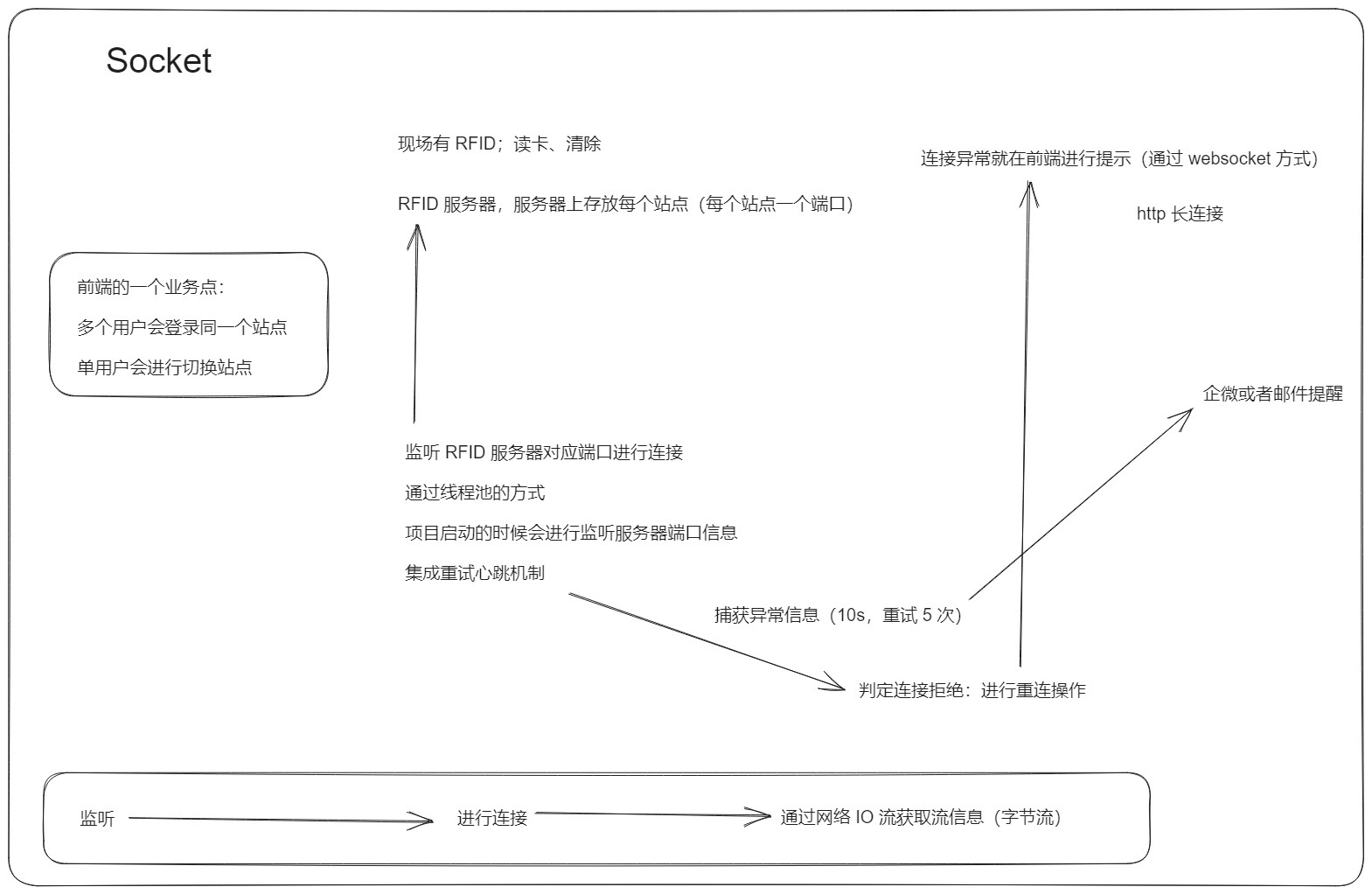
使用 websocket 进行前后端 http 长连接操作
socket 监听,实时推送站点车辆信息到前端界面
性能优化
多线程
参考看一下: https://blog.csdn.net/qq_40851232/article/details/134402593?spm=1001.2014.3001.5502
项目亮点