Appearance
MQ
为什么使用消息队列
MQ 使用的场景有很多,核心的场景是:解耦、异步、削峰;
技术选型?
- Kafka:直接说不太了解
- RocketMQ:高性能,低延迟,主要还是围绕可靠性和持久性,说当时考虑到消息保证不丢失,选用了 RocketMQ
- RabbitMQ:并发量也不低,社区很活跃
如何设计一个消息队列
- 1、MQ:存储怎么设计。
- 使用高可用--磁盘存储:顺序读写、零拷贝技术
- 2、可伸缩:分布式
- 参考:Kafka Broker\topic\partition
- 3、消息丢失:搭建多主多从(节点的主从架构)、多副本、Raft 协议 一台主服务器宕机,选举机制
- 4、消息重复设计
- 5、网络框架:Netty (推荐,高效的NIO框架)
RabbitMQ
- 1、RabbitMQ如何保证消息可靠性传输
- 2、RabbitMQ如何保证消息不丢失
- 3、RabbitMQ如何处理消息堆积
- 4、RabbitMQ如何保证消息有序
- 5、RabbitMQ如何避免消息重复消费
- 6、RabbitMQ的死信队列和延迟队列
- 7、RabbitMQ的⼯作队列模式
- 8、RabbitMQ的高可用
讲一下RabbitMQ的组成部分
核心概念
- Broker:消息队列服务进程。此进程包括两个部分:Exchange和Queue。
- Exchange:消息队列交换机。按一定的规则将消息路由转发到某个队列。
- Queue:消息队列,存储消息的队列。
- Producer:消息生产者。生产方客户端将消息同交换机路由发送到队列中。
- Consumer:消息消费者。消费队列中存储的消息。
说一下 RabbitMQ 的工作流程
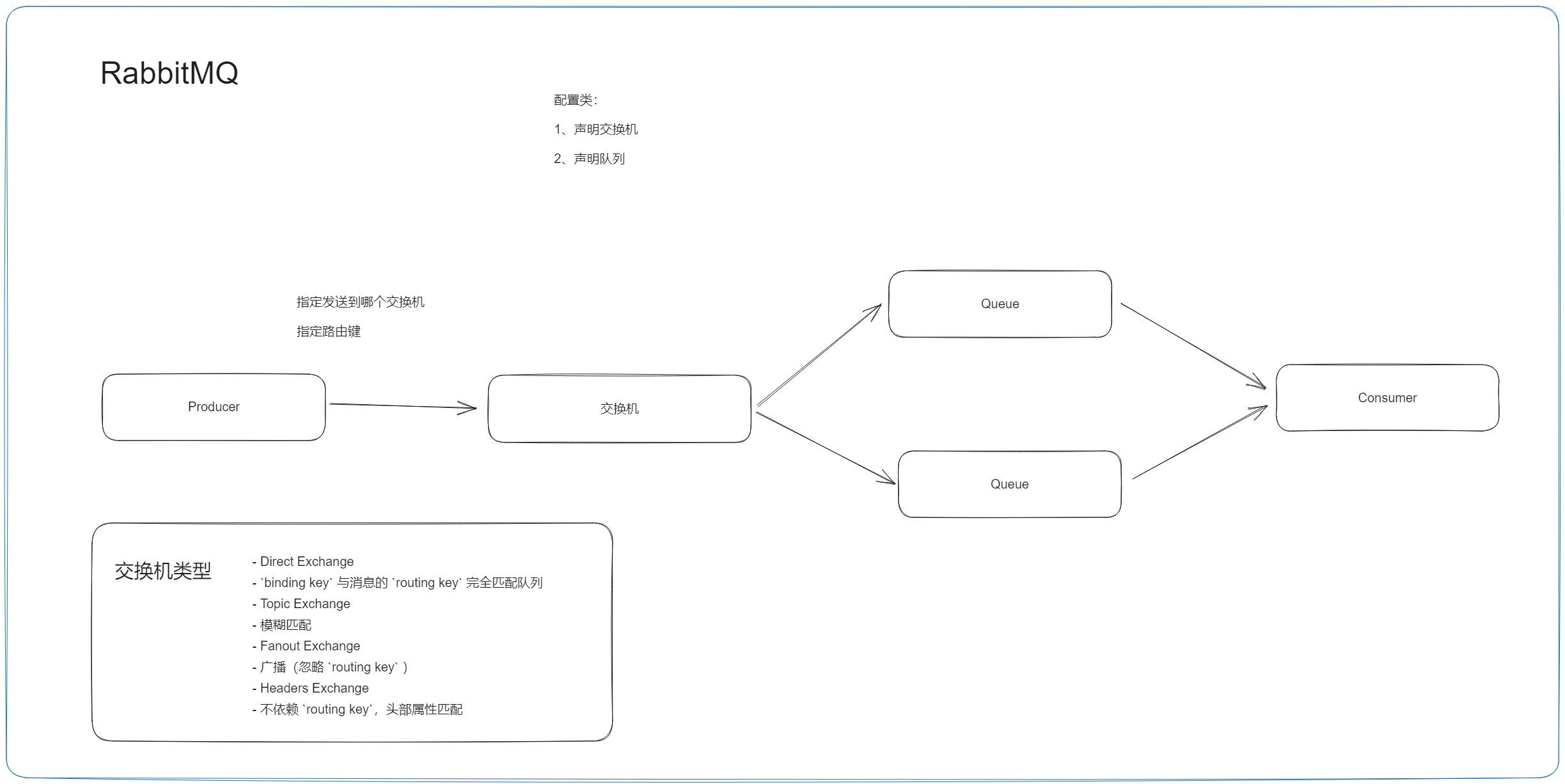
- 建立连接
- 生产者
- 声明交换机类型、名称、是否持久化等
- 发送消息
- 交换机
- 交换机接收消息,进行消息路由
- 消费者
- 订阅消息(监听队列)
- 接收消息,业务处理
讲一下 RabbitMQ 中常用的交换机类型
(交换机 → 队列)
- Direct Exchange
binding key与消息的routing key完全匹配队列
- Topic Exchange
- 模糊匹配
- Fanout Exchange
- 广播(忽略
routing key)
- 广播(忽略
- Headers Exchange
- 不依赖
routing key,头部属性匹配
- 不依赖
RabbitMQ的死信队列和延迟队列
- 死信交换机
- 死信交换机(Dead-Letter Exchange, DLX)是RabbitMQ中用于处理无法正常投递的消息的一种机制。
- 当消息在队列中变成死信(Dead Letter)后,可以被自动重新路由到另一个交换机,这个交换机就是所谓的死信交换机。
- 消息变成死信的情况通常包括:
- 消息被拒绝(Basic.Reject/Basic.Nack)并且设置了requeue参数为false,不重新入队。
- 消息TTL过期(消息设置了生存时间,超过这个时间还未被消费),超时无人消费
- 队列达到最大长度(队列满了,无法再添加更多消息到队列中),最早的消息可能成为死信
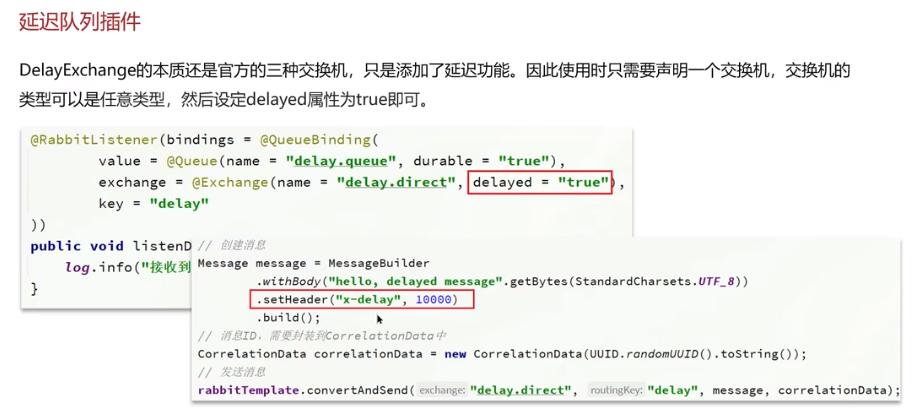
- 延迟队列
- RabbitMQ本身并不直接支持延迟队列,但可以通过以下几种方式间接实现:
- 一种方式是:RabbitMQ 的延迟队列通过死信交换机 + TTL (生存时间)来实现的;
- 还有一种方式是使用 RabbitMQ 的延迟队列相关的一个插件,叫做:DelayExchange,通过这种方式的话只需要在声明交互机的时候,指定这个就是死信交换机,然后在发送消息的时候直接指定超时时间就行。
- RabbitMQ本身并不直接支持延迟队列,但可以通过以下几种方式间接实现:
延迟队列插件使用
怎么保证高可用 🍎
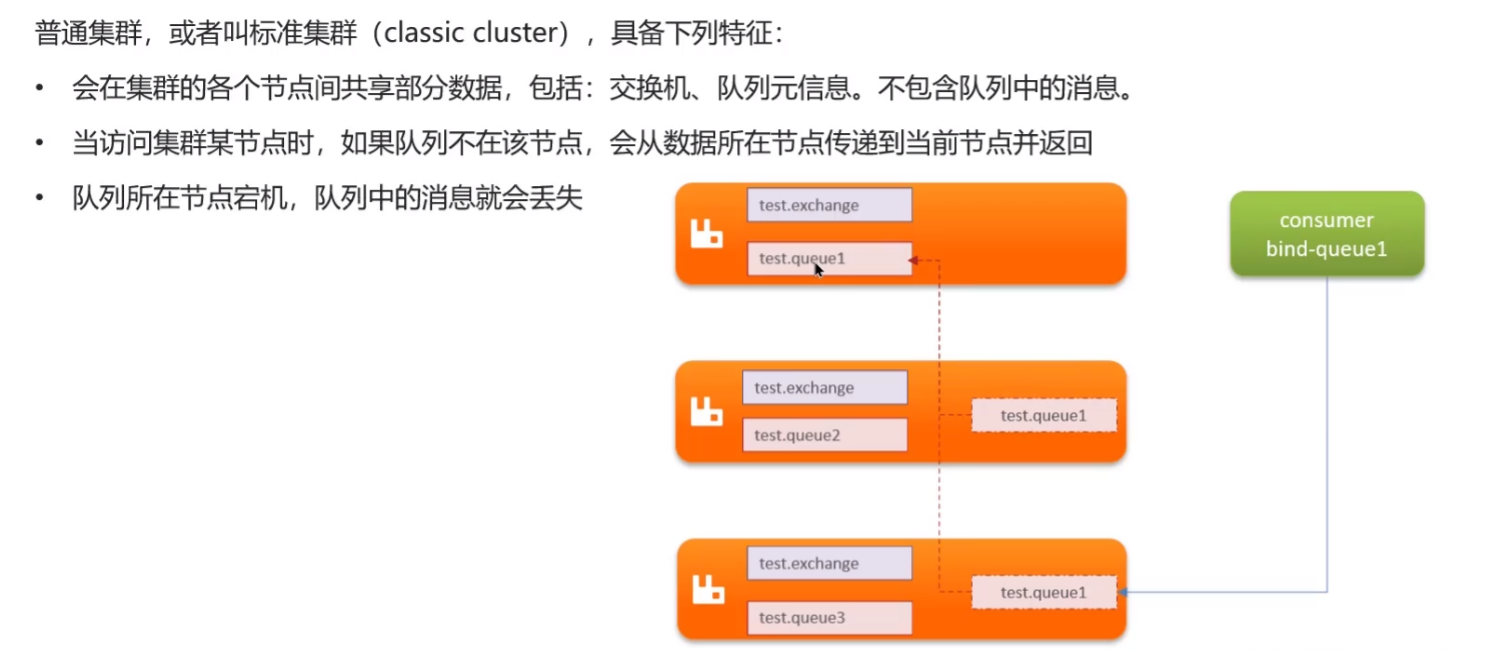
一般会使用集群模式,在 RabbitMQ 中,分为了普通集群模式、镜像集群模式、仲裁队列模式
普通集群模式(标准集群)
- 1、在集群的各个节点共享部分数据
- 2、当访问集群某个节点,如果队列不在该节点,会从数据所在节点传递到当前节点并返回
- 3、队列所在节点宕机,队列中的消息就会丢失
- 这种模式并不能包括高可用
- 实际上还是为了提高吞吐量的
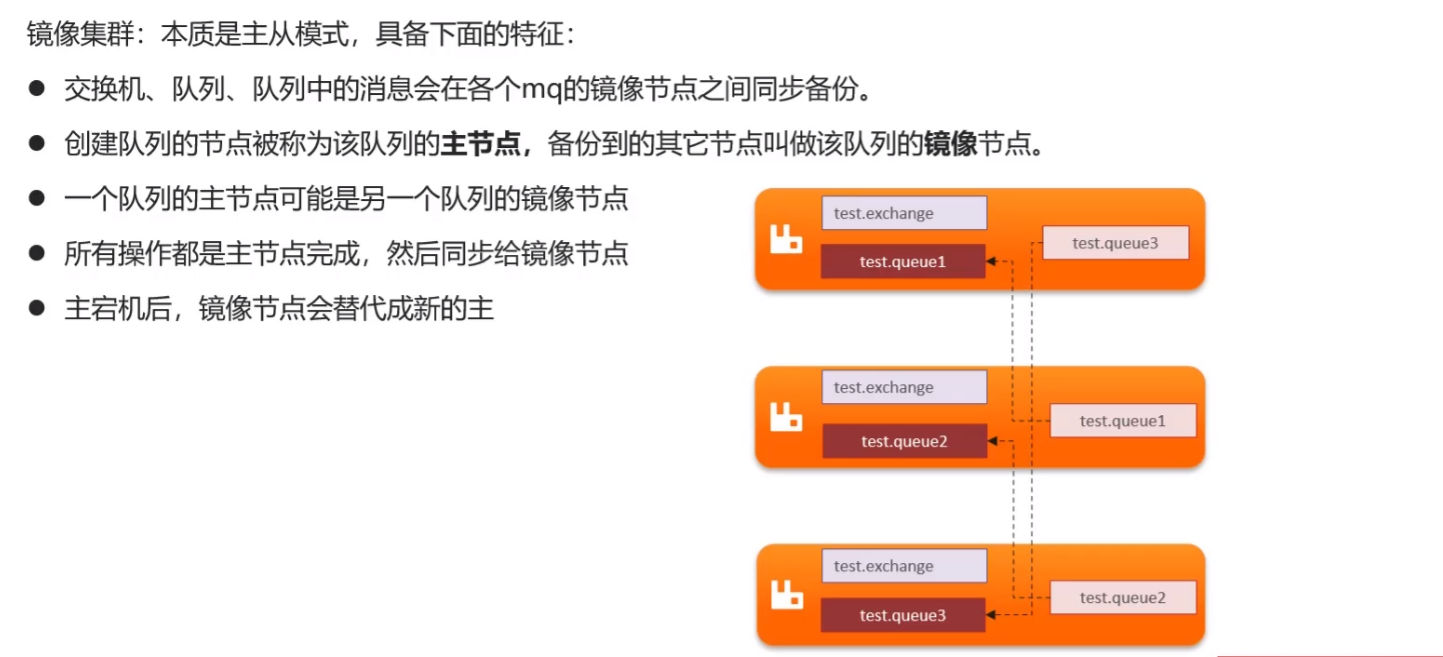
镜像集群:
- 本质上是主从模式
- 交换机、队列、队列中的消息会在各个 mq 的镜像节点之间同步备份。
- 创建队列的节点被称为该队列的主节点,备份到的其它节点叫做该队列的镜像节点。
- 一个队列的主节点可能是另一个队列的镜像节点
- 所有操作都是主节点完成,然后同步给镜像节点
- 主宕机后,镜像节点会替代成新的主
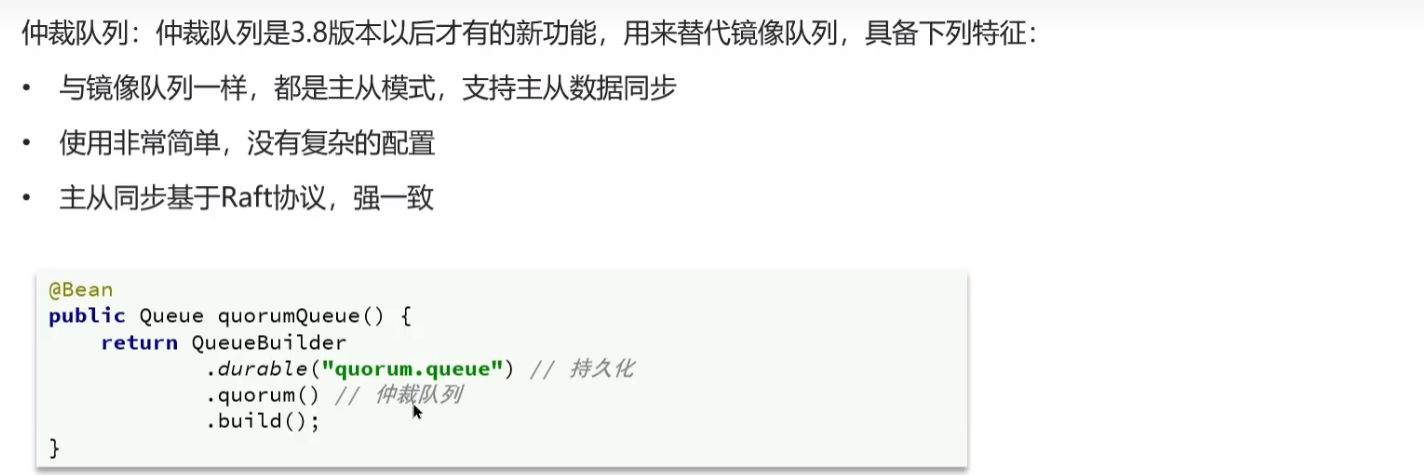
仲裁队列
- 和镜像模式不同的是,他添加了一个主从基于 Raft 协议的方式,使得消息同步变为了强一致性。
参考模拟问答:
面试官:RabbitMQ的高可用机制有了解过嘛
候选人:嗯,熟悉的;我们当时项目在生产环境下,使用的集群,当时搭建是镜像模式集群,使用了3台机器。 镜像队列结构是一主多从,所有操作是主节点完成,然后同步给镜像节点,如果主节点宕机后,镜像节点会替代成新的主节点,不过在主从同步完成前,主节点就己经宕机,可能出现数据丢失。
面试官:那出现丢数据怎么解决呢?
候选人:我们可以采用仲裁队列,与镜像队列一样,都是主从模式,支持主从数据同步,主从同步基于 Raft 协 议,强一致。并且使用起来也非常简单,不需要额外的配置,在声明队列的时候只要指定这个是仲裁队列即可
生产问题
如何保证消息不丢失
- 发送消息过程中不丢失:消息 → 队列;队列本身,队列 → 消费者
- 开启生产者确认机制,确保生产者的消息能到达队列
- 开启持久化功能,确保消息末消费前在队列中不会丢失
- 开启消费者确认机制为auto,由spring确认消息处理成功后完成ack
- 开启消费者失数重试机别(重试次数一般设置为3),多次重试失数后将消息投递到异常交换机,交由人工处理
参考模拟问答:
面试官:RabbitMQ-如何保证消息不丢失
候选人:我们当时 MySQL 和 Redis 的数据双写一致性是采用的 RabbitMQ 实现同步,这里面是要求了消息的高可用性,因此需要保证消息不进行丢失。
当时主要是从三个层面考虑:
- 第一个是开启生产者确认机制,确保生产者的酒息能列达队列,如果报错可以先记录列日志中,再去修复数据
- 第二个是开启持久化功能,确保消息未消费前在队列中不会丢失,其中的交换机、队列、和消息都要做持久化
- 第三个是开启消费者确认机制为auto, 由 spring 确认消息处理成功后完成 ack;当然也需要设置一定的重试次数,我们当时是设置了 3 次,如果重试 3 次还没有收到消息,就将失败后的消息投递到异常交换机,交给人工处理。
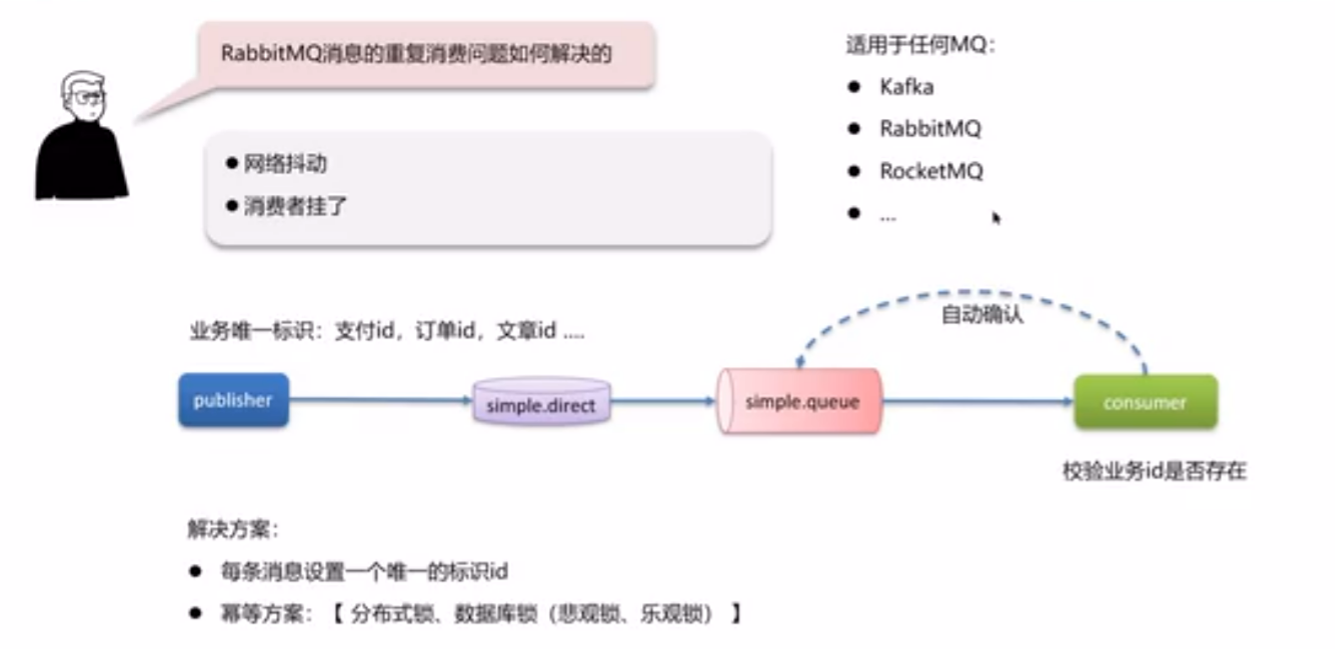
消息重复消费问题怎么解决
出现消息重复消费的问题一般是在网络抖动或者消息者挂掉,由于开启了消费者确认机制,导致消息重发
一般解决方式有两种:
- 一种是每条消息设置一个唯一的标识 ID 从而避免重发消费
- 也可以考虑幂等性设计问题,考虑使用分布式锁、数据库锁(悲观锁、乐观锁)等,但锁会对性能有影响,使用的时候需要考虑使用
一般回答可以倾向回答第一种回答。
参考模拟问答:
面试官,RabbitMQ 消息的重复消费问题你们是如何解决的
候选人:这个我还真遇到过。是这样的,我们当时消费者是设置了自诗确认机制,当业务还没来得及给 MQ 确认的时候。服务岩机了。导数服务重启之后,又进行了一次消费消息。这样就重复消贵了。
因为我们当时处理的支付(订单|业务唯一标识),它有一个业务的唯一标识。我们再处理消息时,先到数据库查询一下,这个数据是否在,如是不存在,说明设有处理过,这个时候就可以正常处理这个消息了,如果己经存在这个数据了,则说明消息重复消费了,我们就不需要再消费了。
面试官:你还知道其他的解决方案吗
候选人:我想一下,其实这个其是典型的幂等的问题,比知,redis 分布式锁、数据库的锁都是可以的。
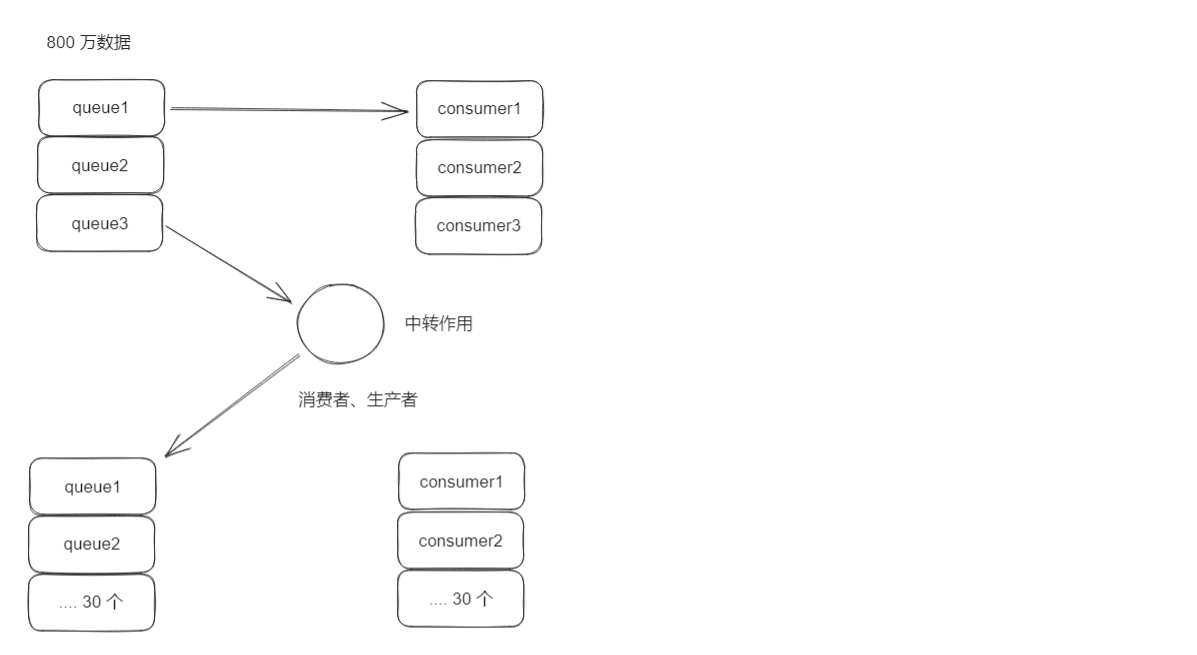
消息堆积问题怎么解决
RabbitMQ 如果有100万消息堆积在MQ,如何解决?
当生产者发送消息的速度超过了消费者处理消息的速度,就会导致队列中的消息堆积,直到队列存储消息达到上限。之后发送的消息就会成为死信,可能会被丢弃,这就是消息堆积问题。
解决消息堆积有三种种思路:
- 增加更多消费者,提高消费速度
- 在消费者内开启线程池加快消息处理速度
- 扩大队列容积,提高堆积上限,采用惰性队列
- 在声明队列的时候可以设置属性x-queue-mode为lazy,即为惰性队列
- 基于磁盘存储,消息上限高
- 性能比较稳定,但基于磁盘存储,受限于磁盘 IO,时效性会降低
惰性队列:惰性队列通过改变消息存储的策略,将消息尽可能地存储在磁盘上,而不是保留在内存中,从而减轻对内存的压力。
参考模拟问答:
面试官:如果有100万消息堆积在MQ,如何解决?
候选人:
- 我在实际的开发中,没遇到过这种情况,不过,如果发生了堆积的问题,解决方案也所有很多的
- 第一:提高消费者的消费能力,可以使用多线程消费任务
- 第二:增加更多消费者,提高消费速度;使用工作队列模式设置多个消费者消费消费同一个队列中的消息
- 第三:扩大队列容积,提高堆积上限
- 可以使用RabbitMO惰性队列,情性队列的好处主要是
- ①接收到消息后直接存入磁盘而非内存
- ②消费者要消费消息时才会从磁盘中读取并加载到内存
- ③支持数百万条的消息存储
- 可以使用RabbitMO惰性队列,情性队列的好处主要是
RocketMQ
RocketMQ 的过一下这个: https://www.bilibili.com/video/BV1d5411y7UW
- 1、讲一下 RocketMQ 的消息模型?
- 2、讲一下 RocketMQ 的基本架构。
- 3、消息的消费模式了解吗?
- 4、如何保证消息的可用性/可靠性/不丢失呢
- 5、消息重复问题如何处理。
- 6、消息堆压问题如何解决
- 7、顺序消息如何实现
- 8、如何实现消息过滤
- 9、RocketMQ 是如何实现延时消息的
- 10、怎么实现消息的分布式事务的,半消息?
- 11、死信队列了解吗
- 12、如何保证RocketMQ的高可用?
- 13、说一下RocketMQ的整体工作流程?
- 14、消息刷盘怎么实现的呢?
Rocketmq中Broker的部署方式
- 单机 Broker
- 多 Master
- 多 Master 多 Slave (生产常见模式)【多主多从】
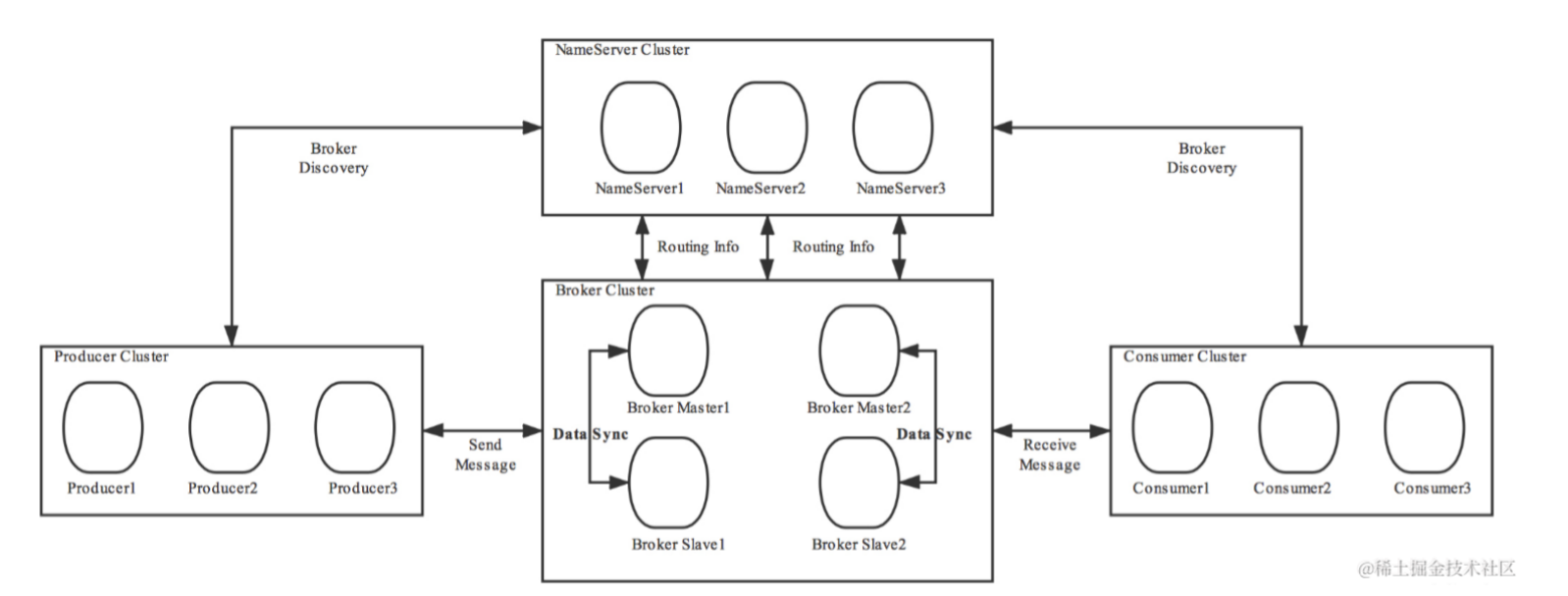
RocketMQ 的 主要组件
基础组件有:NameServer 注册中心、Broker 消息队列服务器、Producer、Consumer
- NameServer
- 主要是⽤于服务注册以及Broker路由
- Broker
- 实际处理消息存储、转发的服务
- Producer
- 发送消息到Broker端
- Consumer
- 接收Broker端推送的消息或主动从Broker端拉取消息
- Topic
- RocketMQ根据主题进⾏消息分类,⽣产端发送消息时需要指 定主题
- MessageQueue
- 相当于Topic的分区,⼀个Topic默认4个MessageQueue
RocketMQ 的工作流程
RocketMQ由NameServer集群、Producer集群、Consumer集群、Broker集群组成,消息生产和消费的大致原理如下:
- 1、Broker在启动的时候向所有的NameServeri注册,并保持长连接,每30s发送一次心跳
- 2、Producer在发送消息的时候从NameServer获取Broker服务器地址,根据负载均衡算法选择一台服务器来发送消息
- 3、Conusmeri消费消息的时候同样从NameServer获取Broker地址,然后主动拉取消息来消费
路由注册
- NameServer每隔1Os扫描brokerLiveTable,检查上次心跳时间与当前时间的时差,如果超过120s,认为broker不可以用,移除路由表中broker相关所有信息
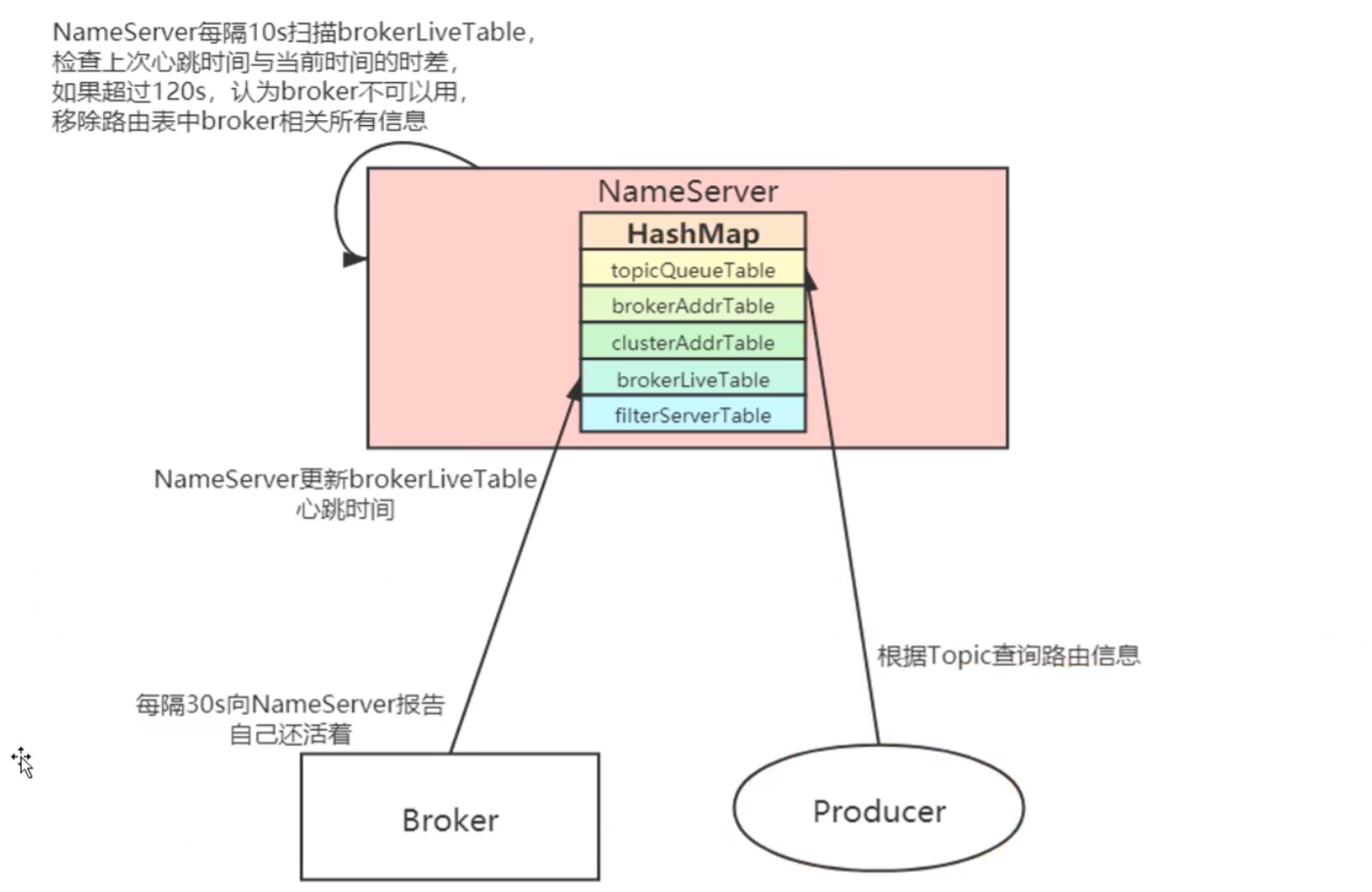
路由剔除
- 定时扫描判断该路由节点是否可用
RocketMQ为什么要放弃Zookeeper
RocketMQ主要是保障最终⼀致性,它只需要⼀个轻量级的元数据服 务就⾏了,⽽Zookeeper是强⼀致性的解决⽅案,并且少使⽤⼀个中 间件可以减少维护成本
还有一方面RocketMQ 是设计是让注册中心尽量轻量化,使得消息发送弱依赖注册中心。
讲一下 RocketMQ 的消息模型?
消息队列有两种模型:队列模型和发布/订阅模型。RocketMQ 是后者。
讲一下 RocketMQ 消息的常用类型
- 顺序消息
- 顺序消息只能保证局部消息有序,不能保证全局有序,
- 实现全局 有序 可以 ⽣产端将⼀批消息有序发往MessageQueue,消费端通 过锁队列的⽅式,每次只拿⼀个MessageQueue⾥的消息
- 顺序消息只能保证局部消息有序,不能保证全局有序,
- 广播消息
- ⼴播消息并没有特定的消费者,因为这涉及到消费者的集群消费 模式,默认是集群模式
- 集群模式
- ⼀个消息只会被⼀个消费组中的⼀个消费者处理⼀次
- Broker端会给每个消费者组维护⼀个统⼀的offset来保 证同⼀个消费组内只会被消费⼀次
- ⼀个消息只会被⼀个消费组中的⼀个消费者处理⼀次
- 广播模式
- ⼀个消息会被推送给所有消费者消费,不再关⼼消费组
- Broker端只管推消息,消费端⾃⼰维护offset
- ⼀个消息会被推送给所有消费者消费,不再关⼼消费组
- 集群模式
- ⼴播消息并没有特定的消费者,因为这涉及到消费者的集群消费 模式,默认是集群模式
- 延迟消息
- 默认提供了18个延迟级别,延迟消息的难点其实是性能,需要不 断进⾏定时轮询,全部扫描所有消息是不可能的
- 批量消息
- 只能对同⼀topic下的消息进⾏批量发送,不⽀持延迟消息,以及 批量消息的⼤⼩不超过1MB,超过了需要⾃⾏拆分
- 过滤消息
- 消费端可以通过⼀定规则匹配topic下需要的消息,⽀持简单过滤 以及SQL过滤
- 消息过滤在消费者端和Broker端都可以做,消费者端进⾏过滤可 以保障消息过滤的可控性,⽽Broker端过滤可以减少不必要数据 的⽹络IO(只把消费者端需要的消息发送出去就⾏)
- 事务消息
- 通过事务消息可以确保上下游的数据⼀致性
- 实现思路
- ⽣产者端将消息发往MQ服务,MQ服务将消息持久化后,向⽣ 产端反馈已收到,此时消息为半消息(半事务消息状态)
- ⽣产端执⾏完本地事务后,会将执⾏结果向MQ服务进⾏⼆次 确认,判断是否提交或回滚
- 如果提交,MQ服务将半消息标记为可投递,然后转发给消 费端
- 如果回滚,MQ服务会将半消息删除
- 如果MQ服务没有收到⼆次确认,会对⽣产端进⾏消息回查, 查看事务执⾏结果继续进⾏⼆次确认
顺序消息
- 全局顺序:全部事件的顺序处理
- 分区顺序:单个事件的逻辑链顺序
延迟消息(延时队列)
RocketMQ 提供了能够延时发送的这种机制,会给定一个范围的时间,然后先暂存到 SCHEDULE_TOPIC_xxxx 的 Topic 中,时间到了再发送到需要发送的队列中。
讲一下使用 RocketMQ 如何实现分布式事务
实现步骤
问这道题目一般是要回答一下RocketMQ 实现分布式事务的实现机制:事务消息加上事务反查机制。
- 1、系统 A 会发送一条消息到 MQ 确认通信没问题
- 2、事务正常执行后会发送一条 commit 消息给 MQ,如果没发确认的话,RocketMQ 会通过事务回查机制确认事务是否正常执行
- 3、判断正常执行完毕后,会发送确认消息给系统B。
建议复习分布式事务的时候也一起和其他实现方式一起复习下。
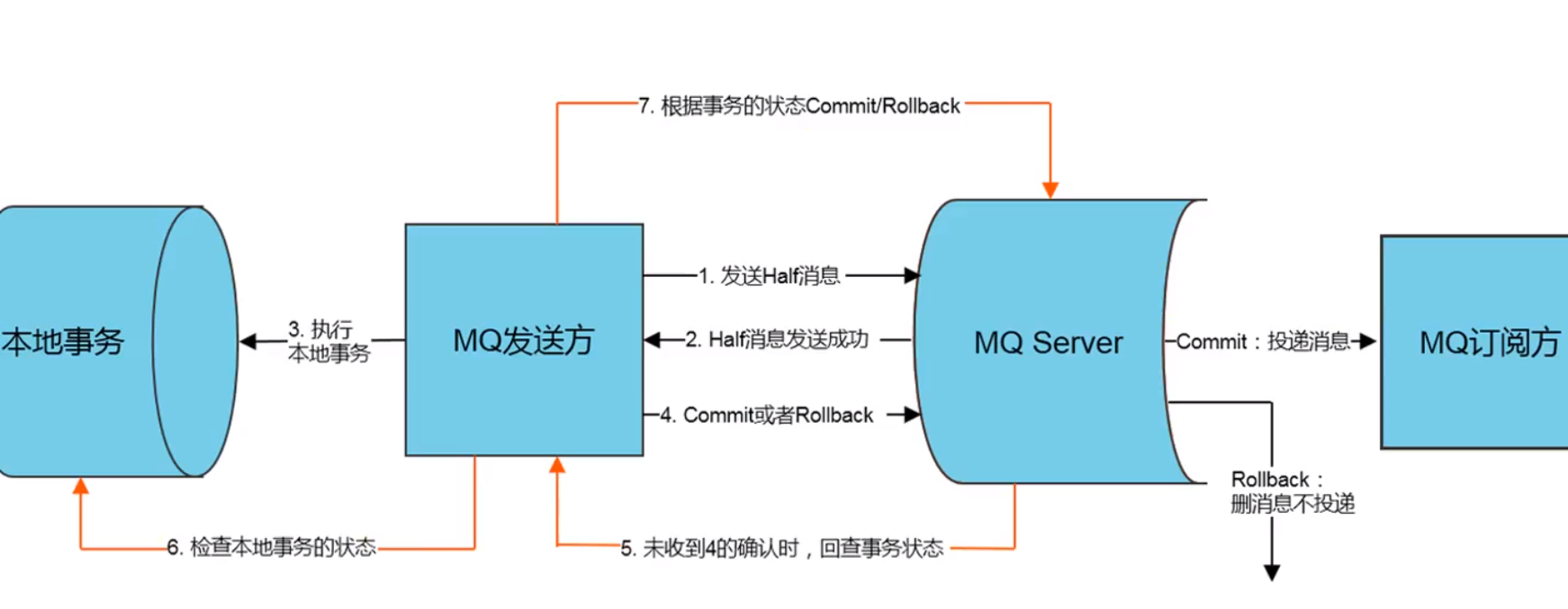
事务回查机制
一般会有一个定时机制,然后如果长时间没有收到二次确认,会进行事务回查
- 这个是生产者反而是消费者,收到这条消息后,通过本地实现的 checker 接口的 checkLocalTransaction 方法进行检查本地事务是否执行完成,并将结果告知 MQ 服务器。

RocketMQ⽣产端的发送模式
- RocketMQ生产端有3种发送模式
- 同步发送
- 必须等到Broker反馈之后才能继续发,安全性最高但发消息最慢
- 单向发送
- 不管消息是否发成功都能继续发,所以吞吐量最高,但是安全性低,容易丢消息
- 异步发送
- 发送消息的同时回注册一个回调去处理响应,安全性低,容易丢消息
- 同步发送
RocketMQ消费端的消费模式
- RocketMQ消费模式⽀持 推模式 和 拉模式
- 推模式模式简单易⽤,有较好的实时性,但Broker压⼒较⼤
- 拉模式对于消费端可以更好的把控,Broker压⼒较⼩,需要⼿动 指定offset
高可用
怎么保证高可用 🍎
- 1、主从,同步复制,异步刷盘,集群
我们可以通过集群机构,其中 Broker 是主从,采用同步复制方式,同时采用异步刷盘。
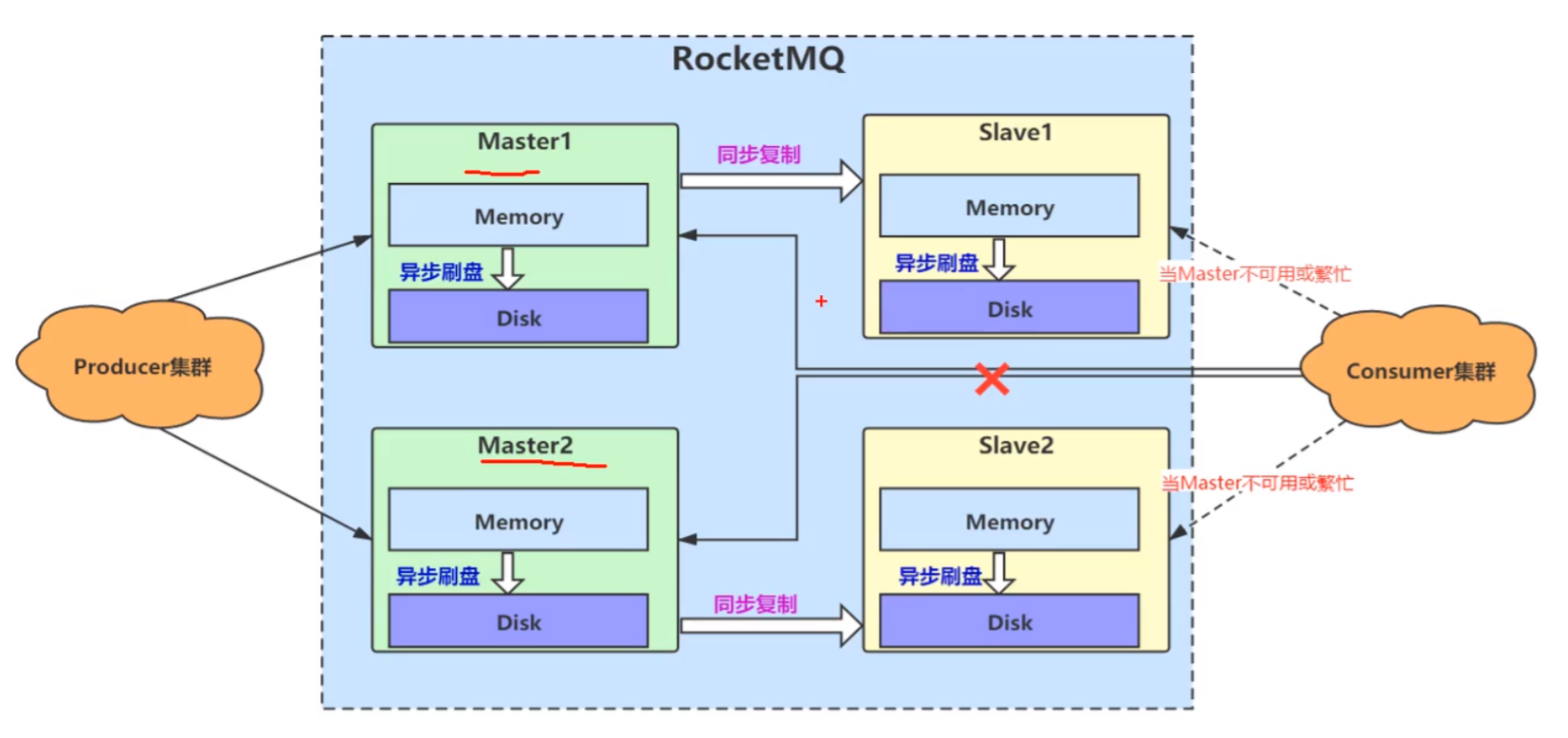
RocketMQ的主从复制原理
- 同步复制
- master和slave的数据都写⼊成功之后才进⾏反馈,如果master故 障,slave仍有数据备份,⽅便数据恢复,但是可能因为数据写⼊ 延迟降低了吞吐量
- 异步复制
- 保证master写⼊成功就进⾏反馈,再通过异步同步数据到slave, 如果master出现故障会导致slave⽆法同步数据导致数据丢失
存储,读写
高性能
高性能主要的几个点:
- 1、Netty 高效的 NIO 框架
- 2、RocketMQ 大量使用多线程、异步
- 3、采用零拷贝技术优化(MMAP) 性能提高50%
- 4、采用文件存储,顺序读写
- 5、锁优化(CAS 机制,无锁化)
- 6、存储设计:读写分离
RocketMQ 的存储机制 💣
RocketMQ 会将所有的消息发送放到 CommitLog 的一个文件中,同时会有一个监听,将相关一个记录(包括主题,偏移量,大小等信息) 放到 ComsumerQueue 中(CommitLog 的逻辑索引)
这个理解有点问题
消息存储结构:
RocketMQ使用CommitLog文件来统一存储所有Broker上的消息。此外,为了支持快速的消息查询和消费,它还使用了ConsumeQueue和IndexFile。
- CommitLog:这是一个大型的文件,所有发送到Broker的消息都会被追加到这个文件中。它不区分Topic或Queue,所有消息按照到达的顺序依次存储。
- ConsumeQueue:为了提高消息消费的效率,RocketMQ为每个消息队列(Queue)创建了一个ConsumeQueue文件。ConsumeQueue是CommitLog的逻辑索引,包含了指向CommitLog中消息的指针,以及一些基本信息,如消息大小、消息位置等。
- IndexFile:RocketMQ提供了一种索引机制,通过IndexFile来支持根据消息的Key或时间来查询消息。这使得根据消息属性进行高效查询成为可能。
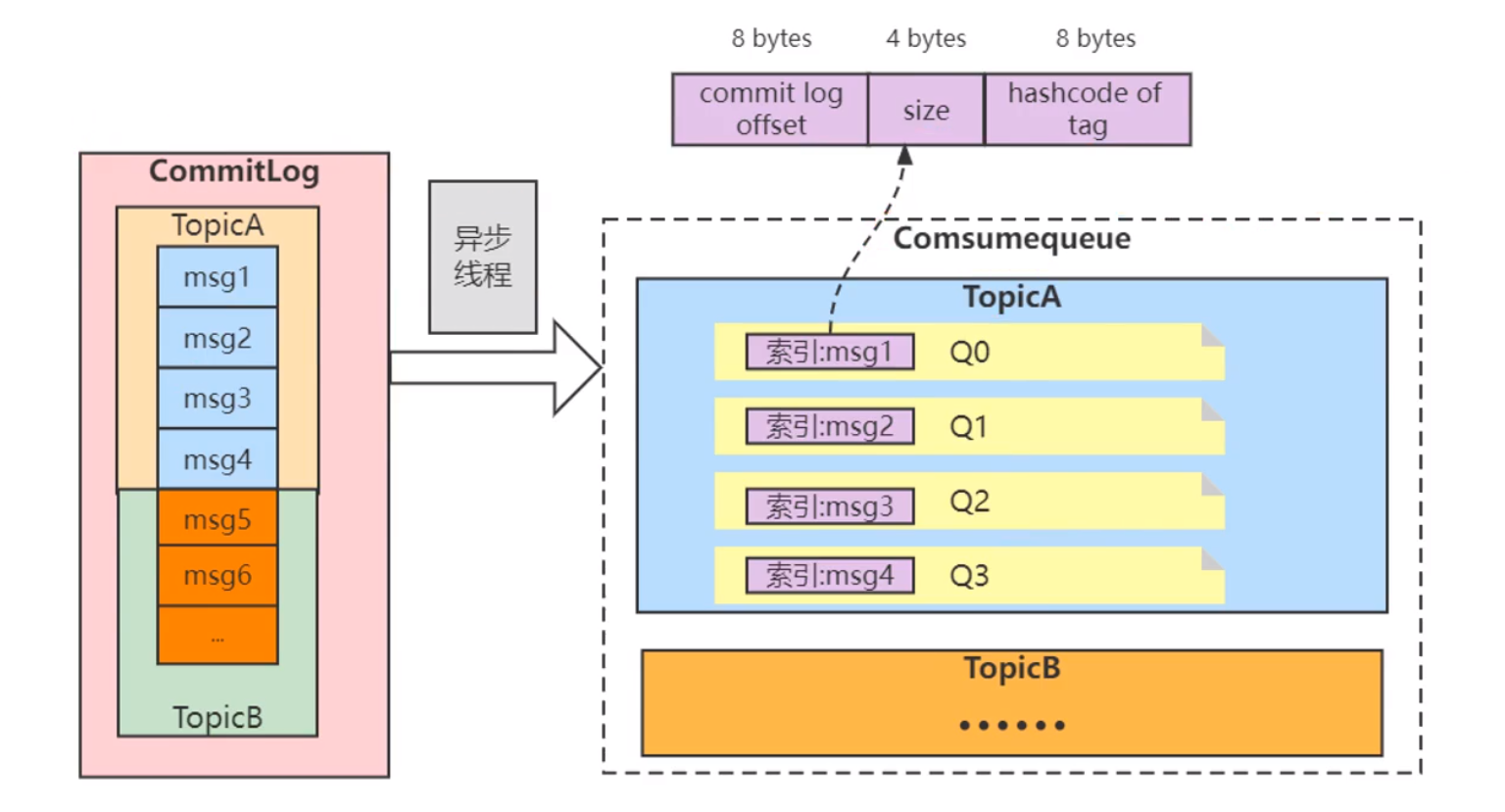
- 1、生产者发送消息
- 2、发送的消息会顺序记录到 Commit Log 中
- 3、RocketMQ 会 通过 ReputMessageService ThreadLoop 进行监听,并将主题等信息(commit log offset、size、hashcode of tag )通过哈希记录到 Comsume Queue 文件(默认是有 4 个文件)
- 4、通过这种方式可以很好处理多主题的情况(只有一个写入文件 Commit Log)
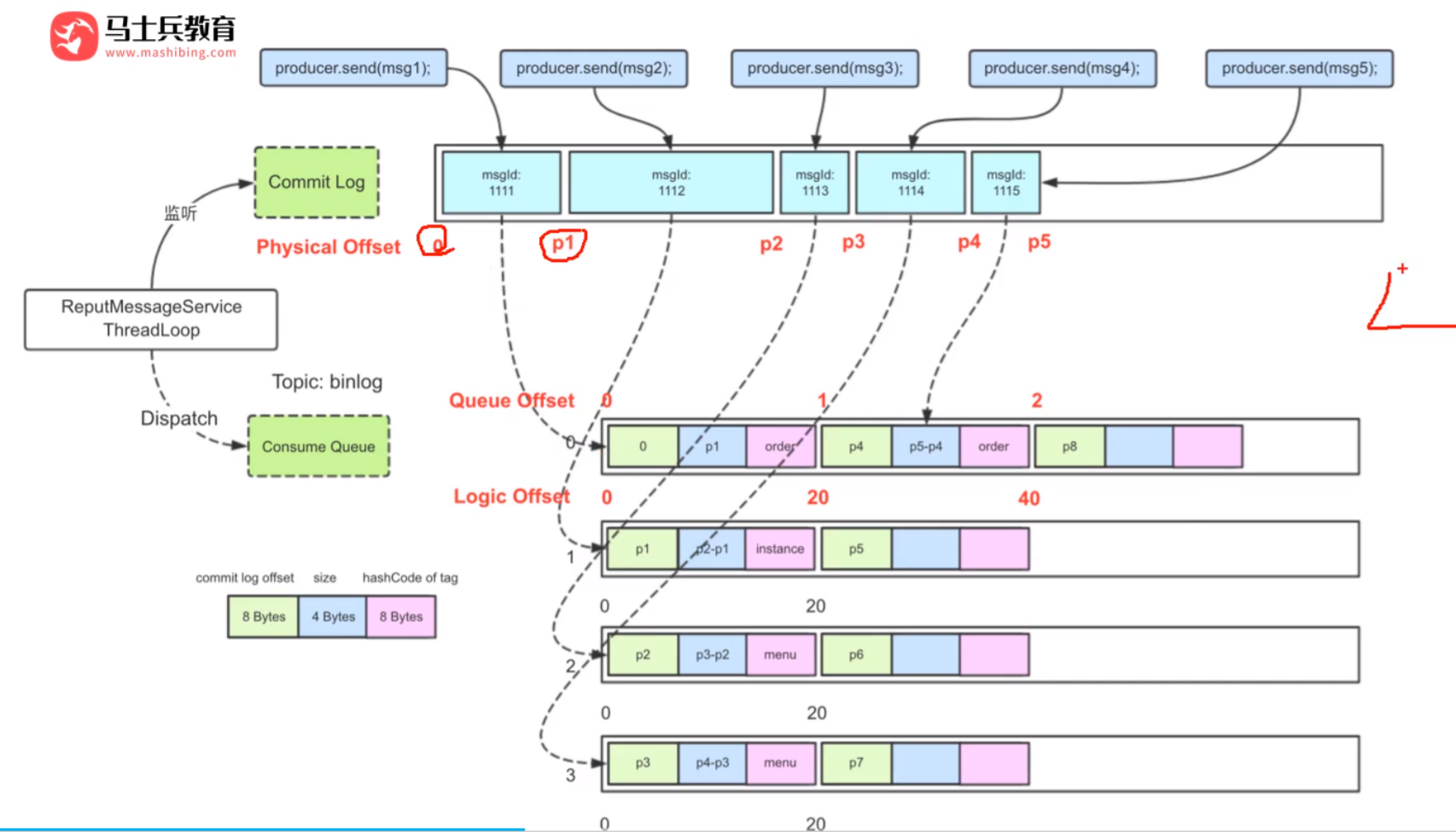
这个解释也可以参考一下

RocketMQ的过期⽂件删除机制
讲一下消息刷盘
- 同步刷盘
- 异步刷盘
- 一般会采用异步刷盘 + 同步复制的方式
- 刷盘是指从内存到磁盘,占用的IO是比较大的,而同步复制是内存到内存,因此耗时会比较少
零拷贝 🚩
通过了零拷贝技术提高了⽂件传输速度,实现方式是 mmap
- mmap 就是通过⽂件位置与进程地址空间建⽴映射关系,程序可 以直接访问⽂件内容
- 这种机制在Java中是通过MappedByteBuffer实现的
传统方式:
在操作系统中,使用传统的方式,数据需要经历几次拷贝,还要经历用户态/内核态切换
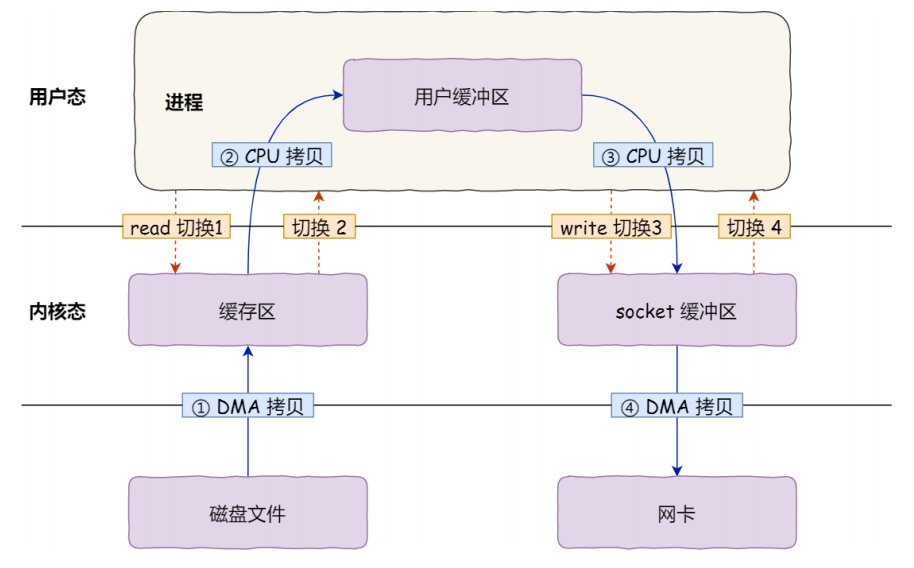
- 从磁盘复制数据到内核态内存;
- 从内核态内存复制到用户态内存;
- 然后从用户态内存复制到网络驱动的内核态内存;
- 最后是从网络驱动的内核态内存复制到网卡中进行传输
零拷贝方式:
可以通过零拷贝的方式,减少用户态与内核态的上下文切换和内存拷贝的次数,用来提升I/O的性能。零拷贝比较常见的实现方式是mmap,这种机制在Java中是通过MappedByteBuffer实现的。
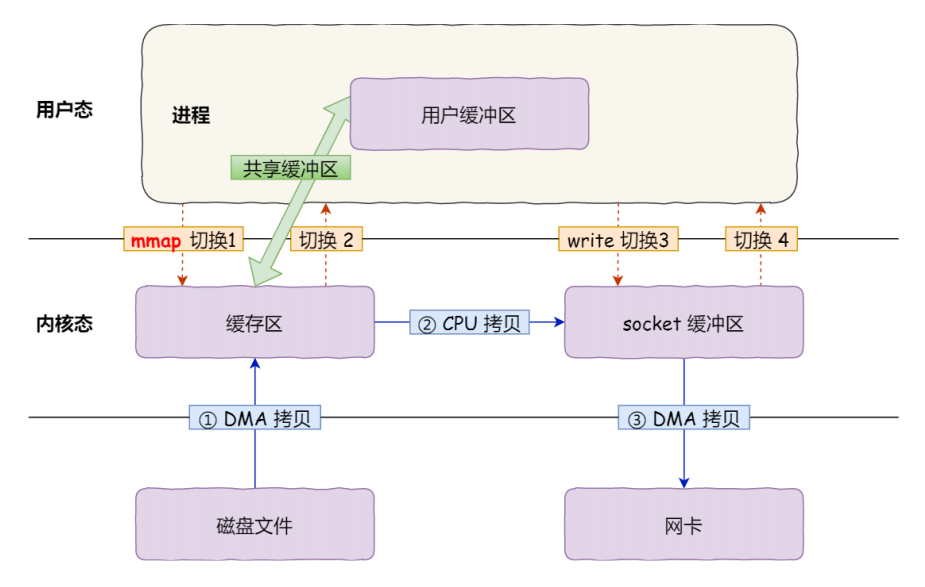
零拷贝的好处:

看一下这个对比:

扩展:
RocketMQ主要通过MappedByteBuffer对文件进行读写操作。
其中,利用了NIO中的FileChannel模型将磁盘上的物理文件直接映射到用户态的内存地址中(这种Mmap的方式减少了传统IO,将磁盘文件数据在操作系统内核地址空间的缓冲区,和用户应用程序地址空间的缓冲区之间来回进行拷贝的性能开销),将对文件的操作转化为直接对内存地址进行操作,从而极大地提高了文件的读写效率(正因为需要使用内存映射机制,故RocketMQ的文件存储都使用定长结构来存储,方便一次将整个文件映射至内存)
零拷贝Zero-Copy技术
参考: https://github.com/0voice/linux_kernel_wiki/blob/main/文章/进程管理/一文带你,彻底了解,零拷贝Zero-Copy技术.md
如果应用程序不对数据做修改,从内核缓冲区到用户缓冲区,再从用户缓冲区到内核缓冲区。两次数据拷贝都需要CPU的参与,并且涉及用户态与内核态的多次切换,加重了CPU负担。 需要降低冗余数据拷贝、解放CPU,这也就是零拷贝Zero-Copy技术
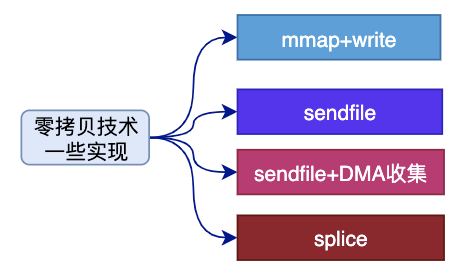
mmap 方式
mmap是Linux提供的一种内存映射文件的机制,它实现了将内核中读缓冲区地址与用户空间缓冲区地址进行映射,从而实现内核缓冲区与用户缓冲区的共享。
这样就减少了一次用户态和内核态的CPU拷贝,但是在内核空间内仍然有一次CPU拷贝。
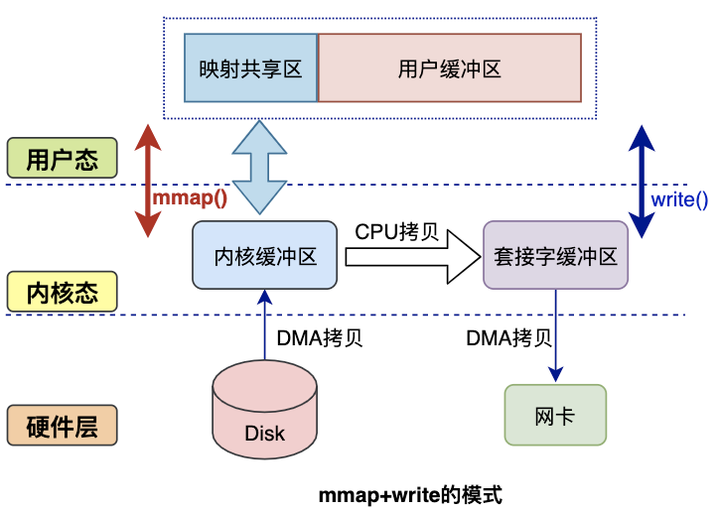
mmap对大文件传输有一定优势,但是小文件可能出现碎片,并且在多个进程同时操作文件时可能产生引发coredump的signal。
生产问题
消息重复消费问题怎么解决
怎么保证消息的可靠性传输
消息队列如何保证消息可靠传输
- 消息可靠传输代表了两层意思,既不能多也不能少。
- 1,为了保证消息不多,也就是消息不能重复,也就是生产者不能重复生产消息,或者消费者不能重复消费消息
- 2,首先要确保消息不多发,这个不常出现,也比较难控制,因为如果出现了多发,很大的原因是生产者自己的原因,如果要避免出现问题,就需要在消费端做控制
- 3.,要避免不重复消费,最保险的机制就是消费者实现幂等性,保证就算重复消费,也不会有问题,通过幂等性,也能解决生产者重复发送消息的问题
- 4,消息不能少,意思就是消息不能丢失,生产者发送的消息,消费者一定要能消费到,对于这个问题,就要考虑两个方面
- 5,生产者发送消息时,要确认brokert确实收到并持久化了这条消息,比如RabbitMQ的confirmi机制,Kafka的ack机制都可以保证生产者能正确的将消息发送给broker
- 6.broke 要等待消费者真正确认消费到了消息时才删除掉消息,这里通常就是消费端ack机制,消费者接收到一条消息后,如果确认没问题了,就可以给broker发送一个ack,broker接收到ack后才会删除消息
消息堆积问题怎么解决
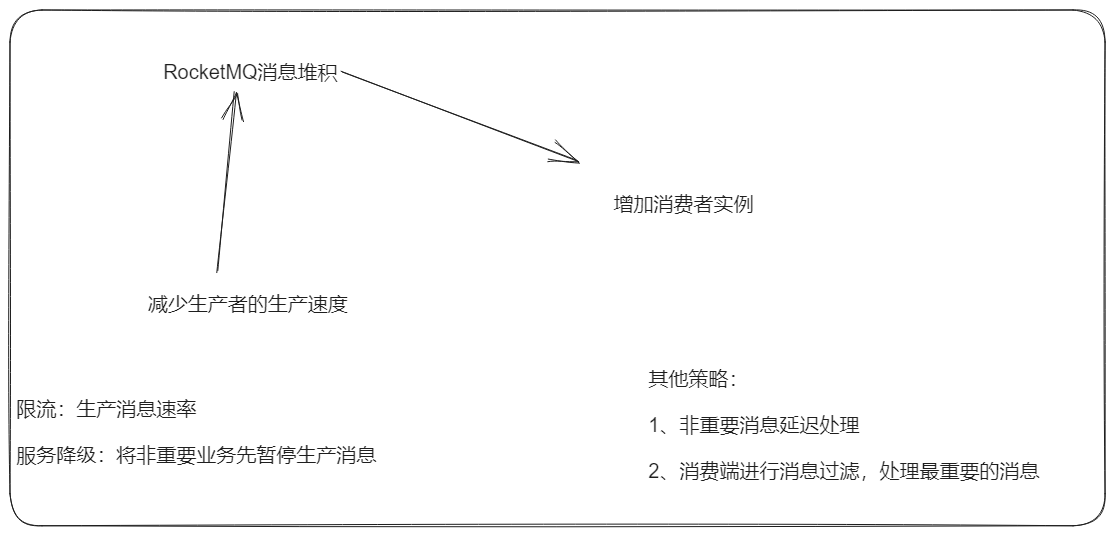
一般是采用增加消费者实例的方式
个人理解:如果是应对生产快的,一方面是需要需要这个队列数量和消费者数量,然后应对堆积的情况,就要加一个中转的,把这个堆积的消息分散到多个Queu,然后多个Comsumer消费