Appearance
首先明确一点的是: Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式的全文搜索引擎,基于restful web接口。
服务下载与安装
一般下载:
- elasticsearch
- 中文分词器 analysis-ik
- 安装中文分词器IKAnalyzer,注意下载与Elasticsearch对应的版本,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
- Kibana 访问Elasticsearch的客户端
Linux 下载
- 下载Elasticsearch
7.17.3的docker镜像:
docker pull elasticsearch:7.17.3- 修改虚拟内存区域大小,否则会因为过小而无法启动:
sysctl -w vm.max_map_count=262144- 使用如下命令启动Elasticsearch服务,内存小的服务器可以通过
ES_JAVA_OPTS来设置占用内存大小:
docker run -p 9200:9200 -p 9300:9300 --name elasticsearch \
-e "discovery.type=single-node" \
-e "cluster.name=elasticsearch" \
-e "ES_JAVA_OPTS=-Xms512m -Xmx1024m" \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-d elasticsearch:7.17.3- 启动时会发现
/usr/share/elasticsearch/data目录没有访问权限,只需要修改/mydata/elasticsearch/data目录的权限,再重新启动即可;
chmod 777 /mydata/elasticsearch/data/- 安装中文分词器IKAnalyzer,注意下载与Elasticsearch对应的版本,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
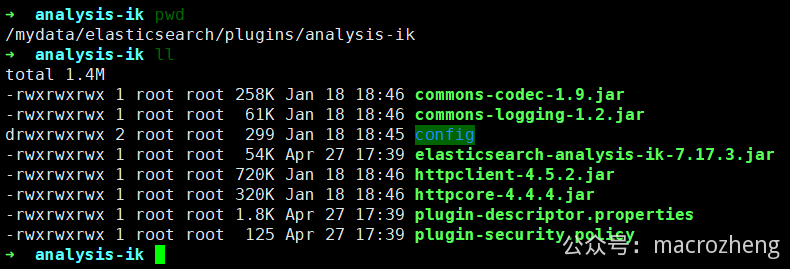
- 下载完成后解压到Elasticsearch的
/mydata/elasticsearch/plugins目录下;
- 重新启动服务:
docker restart elasticsearch- 开启防火墙:
firewall-cmd --zone=public --add-port=9200/tcp --permanent
firewall-cmd --reload- 访问会返回版本信息:http://192.168.3.101:9200
{
"name": "708f1d885c16",
"cluster_name": "elasticsearch",
"cluster_uuid": "mza51wT-QvaZ5R0NmE183g",
"version": {
"number": "7.17.3",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "5ad023604c8d7416c9eb6c0eadb62b14e766caff",
"build_date": "2022-04-19T08:11:19.070913226Z",
"build_snapshot": false,
"lucene_version": "8.11.1",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}Kibana 的下载
- 下载Kibana
7.17.3的docker镜像:
docker pull kibana:7.17.3- 使用如下命令启动Kibana服务:
docker run --name kibana -p 5601:5601 \
--link elasticsearch:es \
-e "elasticsearch.hosts=http://es:9200" \
-d kibana:7.17.3- 开启防火墙:
firewall-cmd --zone=public --add-port=5601/tcp --permanent
firewall-cmd --reload- 访问地址进行测试:http://192.168.3.101:5601
相关概念
- Near Realtime(近实时):Elasticsearch是一个近乎实时的搜索平台,这意味着从索引文档到可搜索文档之间只有一个轻微的延迟(通常是一秒钟)。
- Cluster(集群):群集是一个或多个节点的集合,它们一起保存整个数据,并提供跨所有节点的联合索引和搜索功能。每个集群都有自己的唯一集群名称,节点通过名称加入集群。
- Node(节点):节点是指属于集群的单个Elasticsearch实例,存储数据并参与集群的索引和搜索功能。可以将节点配置为按集群名称加入特定集群,默认情况下,每个节点都设置为加入一个名为
elasticsearch的群集。 - Index(索引):索引是一些具有相似特征的文档集合,类似于MySql中数据库的概念。
- Type(类型):类型是索引的逻辑类别分区,通常,为具有一组公共字段的文档类型,类似MySql中表的概念。
注意:在Elasticsearch 6.0.0及更高的版本中,一个索引只能包含一个类型。 - Document(文档):文档是可被索引的基本信息单位,以JSON形式表示,类似于MySql中行记录的概念。
- Shards(分片):当索引存储大量数据时,可能会超出单个节点的硬件限制,为了解决这个问题,Elasticsearch提供了将索引细分为分片的概念。分片机制赋予了索引水平扩容的能力、并允许跨分片分发和并行化操作,从而提高性能和吞吐量。
- Replicas(副本):在可能出现故障的网络环境中,需要有一个故障切换机制,Elasticsearch提供了将索引的分片复制为一个或多个副本的功能,副本在某些节点失效的情况下提供高可用性。