Appearance
链接地址: https://www.bilibili.com/video/BV1SD42157HR
在演示之前,添加部分的数据
新建表
CREATE TABLE employees (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100),
age INT,
department_id INT,
hire_date DATE
);索引基础操作
#添加索引
CREATE INDEX idx_department_id ON employees(department_id);
# 删除索引
DROP INDEX idx_department_id ON employees;
# 新增索引
ALTER TABLE employees ADD INDEX idx_department_id (department_id);
#查看索引
SHOW INDEXES FROM employees;
#组合索引
CREATE INDEX idx_name_age ON employees(name, age);批量添加示例数据,这里是通过 gpt4.0,通过说生成 excel 类似格式的随机内容,然后生成一万条数据,再通过 navicat 工具进行导入操作。
索引优化
最左前缀原则
最左前缀法则:带头大哥不能死,中间兄弟不能断
当面试的时候,建议不要从直接的表象去回答这些问题,建议结合一下相关的底层实现去讲;
比如说谈到啊最左前缀原则失效的时候,你可以讲一下,我们MySQL 的使用的存储引擎 innodb 中,采用 B+ 树的索引结构(这里可能会问一下为什么Mysql 会使用 B+ 树的数据结构,有一个 钩子点埋下)
然后这里可以围绕说,当我们沿着 B+ 树的叶子节点往下走的时候,如果说前缀未匹配(带头大哥不能死,中间兄弟不能断),这个树节点就走不下去(不走索引)
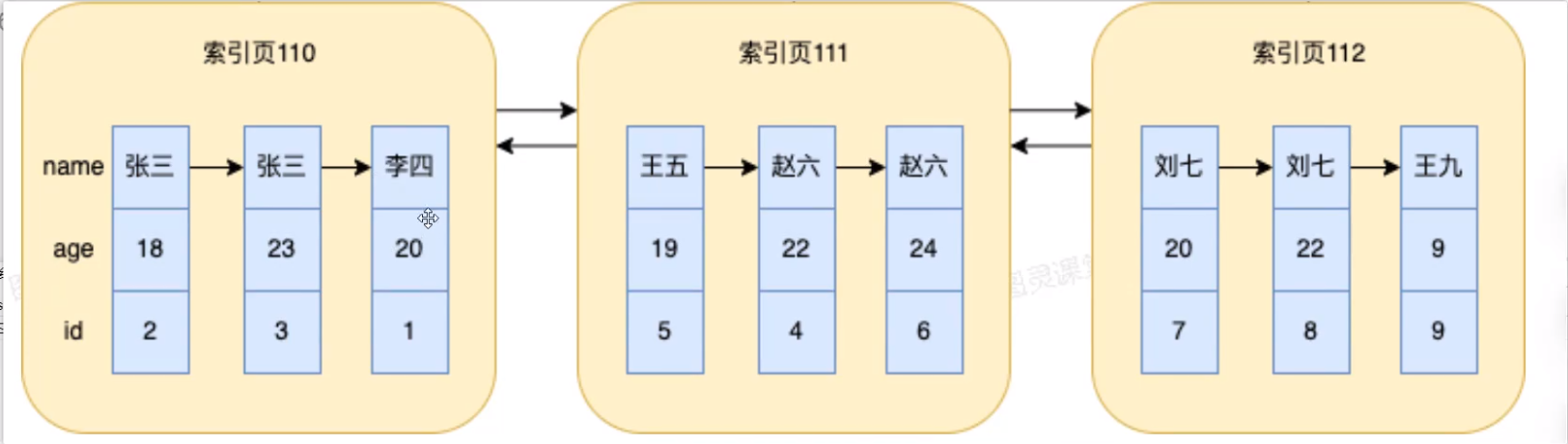
核心思想是围绕索引 ”有序“ 这个点出发去讲。
索引类上少计算数
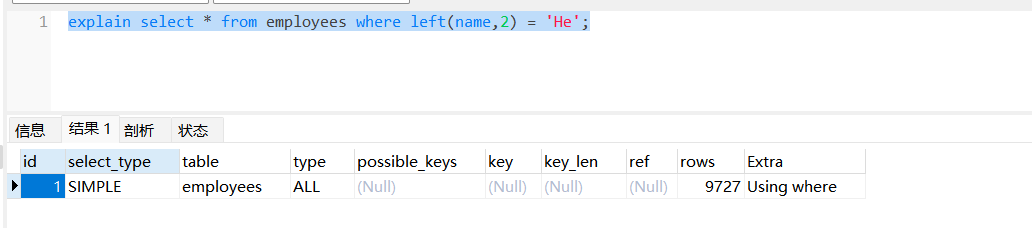
explain select * from employees where left(name,2) = 'He';这种情况下,会进行的是全表扫描操作,当他实际上在索引列上使用到了函数,他实际会对于当前索引数下,当前列每一个节点进行运算,从而会进行全表扫描。
优化:
explain select * from employees where name like 'He%';通过 like 运算,进行后缀查询操作,这种情况下会走索引(有序操作),从而这里会实际走了范围索引查询。

总结:不在索引类上做任何操作(计算、函数、(自动 or 手动)类型转换),会导致索引失效而转向全表扫描。
核心就围绕一个:有序,尽可能走叶子节点下有序的操作。
范围后面全失效
select 使用明确字段(尽可能使用覆盖索引)
不等空值或者 or
如果出现 != 或者 or 的时候,可以考虑使用强制使用索引的操作;

explain select name,age from employees where name != 'Colleen Perry' or name = 'Marcus Wilson';
explain select name,age from employees FORCE INDEX(idx_name_age_part) where name != 'Colleen Perry' or name = 'Marcus Wilson'当使用强制索引 idx_name_age_part,第二步他这里走的是范围查询索引,扫描的行数变少了一些(数据量大的话更明显)

VAR 引号不能丢

explain select name,age from employees where name = 30;
explain select name,age from employees where name = '30';当 var 类型使用的查询条件这里使用数字的话,他隐含的操作是类型转换操作,会将字段内容转换为数值类型,再进行查询操作,因此这里会进行全表扫描操作;
因此建议 var 引号不能丢。
