Appearance
从 0 认识 DDD 分层架构:原则、边界与实践
写在前面:本文面向已有 Spring Boot 开发经验的中高级后端工程师,不介绍 DDD 的基础词汇表,而是聚焦「为什么这么分层」「依赖倒置在哪里体现」「上下文边界怎么守住」这三个最容易被忽视的核心问题。
一、痛点先行:传统三层架构坏在哪里
说 DDD 分层架构好之前,先想想「传统三层」什么时候让你最抓狂:
OrderService里直接写了 JPQL/SQL:想换数据库,得从业务逻辑里一行行扒 SQL。Controller里做业务判断:前端换了 REST → gRPC,结果一大坨 if-else 要迁移。- 所有模块共用同一个
User实体:订单、支付、仓储字段全塞进去,改个字段全家跟着抖。
这三个痛点背后是同一个根因:业务逻辑与技术实现、业务逻辑与入口协议、业务概念与模块边界——都没有做到真正分离。
DDD 分层架构的目标,就是通过清晰的层次职责和依赖规则,从根本上解决这三个问题。
二、DDD 分层全景:五个模块一张图
以一个实际 ChatGPT 应用后端项目为例(也是 DDD 落地中较典型的模块划分),整个工程被拆为五个模块:
chatgpt-data-app ← 启动层(组装器)
chatgpt-data-trigger ← 触发器层(HTTP/MQ/定时任务)
chatgpt-data-domain ← 领域核心层(业务心脏)
chatgpt-data-infrastructure← 基础设施层(技术实现)
chatgpt-data-types ← 公共类型层(枚举/常量/VO)
注意:这五层并非"调用顺序",而是职责边界划分。调用顺序和编译依赖方向在
domain ↔ infrastructure之间是反的,这正是最精髓的地方(见第三节)。
各层职责一句话总结:
| 层 | 一句话定位 | 典型内容 |
|---|---|---|
| domain | 业务核心,不知道数据库的存在 | 实体、聚合根、领域服务、Repository 接口 |
| infrastructure | 技术实现,不定义业务规则 | MyBatis Mapper、RedisTemplate、第三方 API Client |
| trigger | 外部入口,只负责接收和分发 | REST Controller、MQ Consumer、Job |
| app | 启动组装,没有业务代码 | Spring Boot 启动类、数据源配置、Bean 装配 |
| types | 全局共享类型,尽量只放无逻辑的定义 | 枚举、通用返回体 Response<T>、公共异常 |
三、架构灵魂:依赖方向与依赖倒置
这是 DDD 分层最容易被忽视、也最值得细品的地方。
3.1 依赖方向规则
编译依赖方向(谁 import 谁):
infrastructure → domain → types,trigger → domain → types
换句话说:只允许外层依赖内层,禁止内层依赖外层。 domain 层绝对不能 import 任何 MyBatis / JPA 相关类。
3.2 运行时调用方向
请求进来
↓
trigger(接收请求)
↓
domain(执行业务逻辑)
↓
infrastructure(读写数据库)等等,domain 调用了 infrastructure,但编译时 domain 不依赖 infrastructure——这不矛盾吗?
答案就是依赖倒置原则(DIP):
// domain 层只定义接口,不知道实现是谁
package com.example.domain.repository;
public interface OrderRepository {
Order findById(String orderId);
void save(Order order);
}
// infrastructure 层实现这个接口(infrastructure 依赖 domain,不是反过来)
package com.example.infrastructure.repository;
@Repository
public class OrderRepositoryImpl implements OrderRepository {
@Autowired
private OrderMapper orderMapper; // MyBatis
// ...
}domain 定义接口,infrastructure 实现接口。Spring 在运行时通过 IoC 容器把实现注入进来,而 domain 在编译时压根不知道 MyBatis 的存在。
下图直观展示了这两个方向的"交叉"关系:
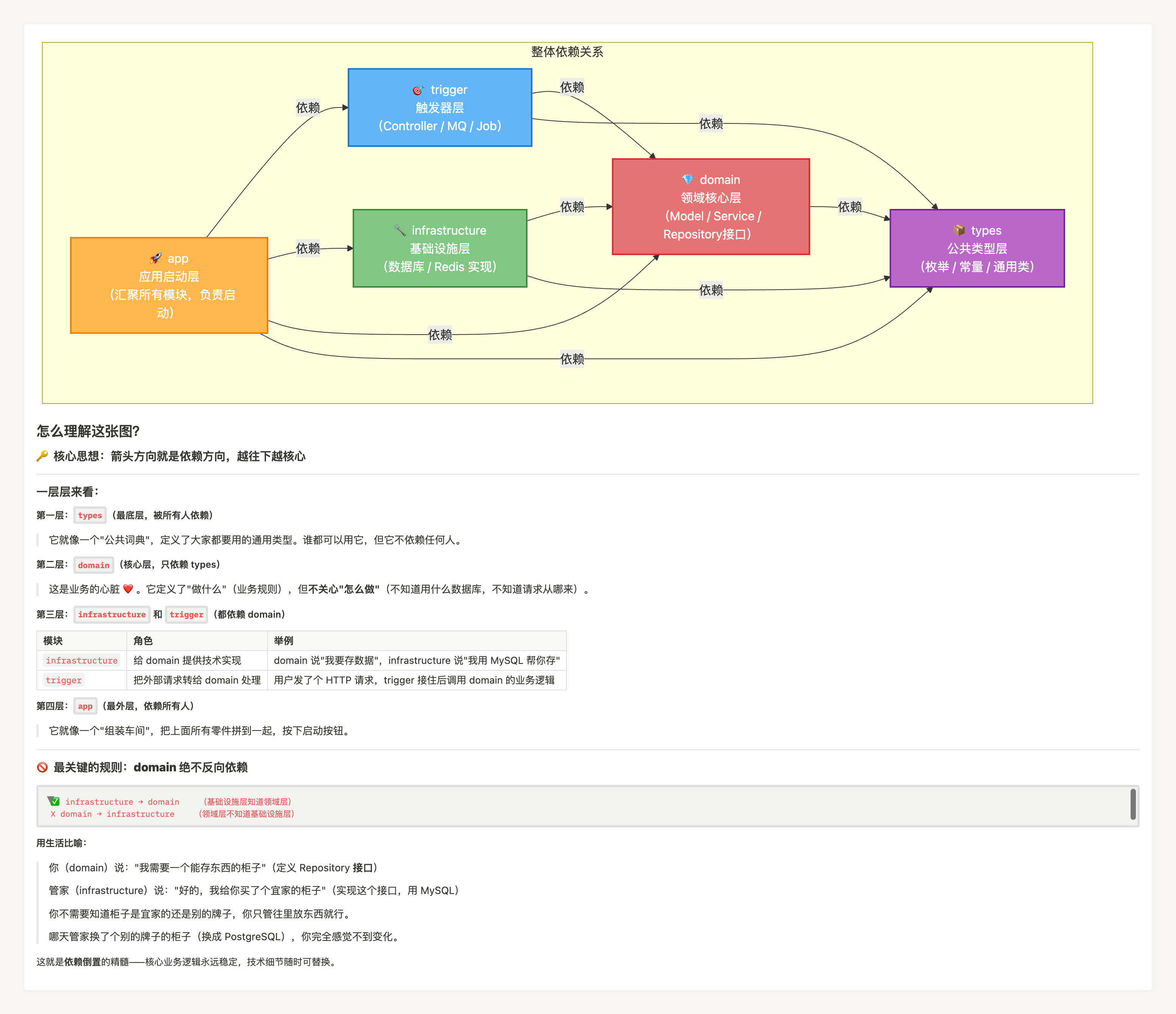
代码依赖方向: infrastructure → domain → types
↑
运行时调用方向: trigger → domain → infrastructure两个方向在 domain 和 infrastructure 之间是反的,这正是依赖倒置的精髓。 换数据库时,只需修改 infrastructure 层,domain 层零改动。
四、限界上下文:业务边界的守卫者
分层架构解决了「一个上下文内的代码分层问题」,但更大的挑战是:多个业务模块(上下文)之间如何隔离?
4.1 同一个词,不同部门含义不同
想象一家公司的不同部门对「商品」的理解:
- 仓储部:库存数量、货架位置、保质期
- 销售部:价格、促销活动、销量排名
- 物流部:重量、体积、收货地址
如果写一个全局 Product 类把所有字段都塞进去,每次有一个部门改字段,所有部门都要小心翼翼。限界上下文(Bounded Context)的核心,就是给每个业务域划一条明确的边界,边界内的概念自治,边界外的概念不能直接共享。
4.2 代码层面:每个上下文定义自己的模型
同一个「用户」在不同上下文中的字段截然不同:
java
// 订单上下文的 User(只关心收货)
class OrderUser {
String userId;
String receiverName;
String address;
String phone;
}
// 支付上下文的 User(只关心支付能力)
class PaymentUser {
String userId;
String paymentAccount;
List<String> bindedCards;
}绝对不应该存在一个被所有上下文共用的 User 大类。
4.3 上下文之间如何通信
上下文不能直接互访数据库,通信有三种主要方式:
| 场景 | 方式 | 特点 |
|---|---|---|
| 同步调用 | DTO(Data Transfer Object) | 扁平、无业务逻辑,只含对方需要的字段 |
| 异步解耦 | 领域事件(Domain Event) | 含事件时间戳和快照数据,通过 MQ 投递 |
| 极少量共享概念 | 共享内核(Shared Kernel) | 放 types 层,如 Money 值对象、通用枚举 |
| 对接外部系统 | 防腐层(ACL)+ DTO | 隔离外部变更,让外部变化不污染内部模型 |
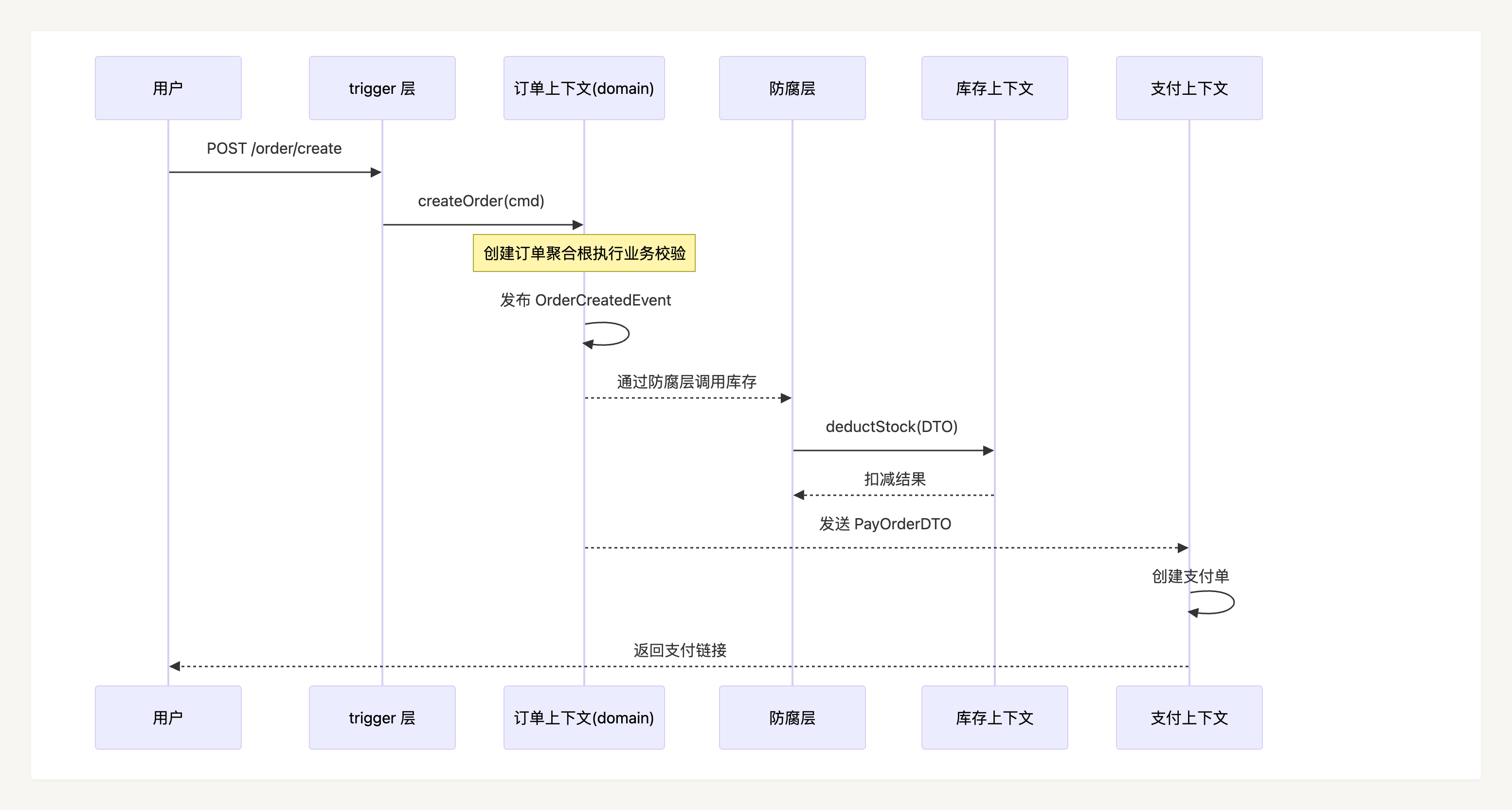
一个完整的下单→扣库存→发起支付链路示例:
用户请求 → trigger(OrderController)
→ domain(OrderService) 创建 Order 聚合根,执行业务校验
→ 发布 OrderCreatedEvent(异步)→ 库存上下文扣减库存
→ 防腐层 → 支付上下文 API(传 PayOrderDTO)→ 返回支付链接五、代码放哪层?一个判断清单
新人落地 DDD 最高频的问题就是「这段代码该放哪儿」,给出一个快速判断标准:
写的是业务规则? → domain
写的是 SQL / 缓存 / HTTP 调用? → infrastructure
写的是接收外部请求? → trigger
写的是通用类型(枚举/常量)?→ types
写的是启动配置? → app几个容易踩的陷阱:
- 领域服务 vs 应用服务:领域服务(
DomainService)处理跨实体的复杂业务逻辑,不依赖任何框架;应用服务(如果有)做流程编排。两者都应在domain层内,不要把@Transactional打在领域服务上(事务是技术关注点,应在infrastructure或trigger层处理)。 infrastructure中禁止出现 if-else 业务判断:只要发现"某条件下走不同 SQL"这种模式,要么是业务条件本就该在domain决策,要么需要拆出两个 Repository 方法。- DTO 别直接当领域对象用:DTO 是传输结构,进入
domain之前必须转换为领域实体或值对象。
六、常见误区与对策
误区一:分层只是目录分包
只把代码文件移到不同 package,但 domain 里仍然 import com.baomidou.mybatisplus——这不叫 DDD 分层,叫"DDD 皮"。真正的分层由 Maven/Gradle 模块级别的依赖声明来保证,物理上 domain 模块的 pom.xml 就不包含 MyBatis 依赖。
误区二:Repository = DAO
传统 DAO 面向数据库表;Repository 面向聚合根。OrderRepository.save(order) 的职责是持久化整个 Order 聚合(可能涉及多张表),而不是操作某张表。DAO 是技术概念,Repository 是领域概念。
误区三:所有上下文共用一个数据库用户表
上下文之间的数据隔离不一定要物理隔库,但逻辑上每个上下文只读写属于自己的表。订单上下文的 order_user_address 表和用户上下文的 user_profile 表分开管理,互不直连。
误区四:DDD 一定比三层架构复杂
DDD 分层的额外成本在前期(需要定义接口、写转换代码),但随着项目规模增长,可测试性(domain 纯 POJO,单测无需 Spring)、可替换性(换数据库只改 infrastructure)和团队并行效率会产生指数级回报。小型 CRUD 项目不必硬套 DDD;一旦业务逻辑复杂度超过临界点,DDD 的分层收益就会超过成本。
七、一分钟自检清单
完成一个 DDD 分层改造后,用这份清单快速验证:
- [ ]
domain模块的pom.xml/build.gradle中没有 MyBatis、JPA、Spring Data 依赖 - [ ]
domain层只定义 Repository 接口,实现类全在infrastructure - [ ]
trigger层不直接写业务逻辑,只做参数转换 + 调用domain - [ ] 不同限界上下文之间通过 DTO 或领域事件通信,没有直接共用实体类
- [ ]
types层只有无业务逻辑的枚举/常量/通用返回体,没有@Service/@Repository - [ ] 单元测试可以只 mock
Repository接口来测试domain层,不需要启动 Spring 容器
八、小结
DDD 分层架构的核心可以浓缩成三句话:
- 依赖由外向内,内层不知道外层:
infrastructure依赖domain,而不是反过来。 - 领域层通过接口抽象技术实现:Repository 接口定义在
domain,实现在infrastructure,这是依赖倒置的落脚点。 - 上下文之间通过 DTO/事件通信,不共享内部模型:每个上下文的领域模型自治,这是限界上下文的核心约束。
理解这三句话之后,DDD 分层就不再是一种"目录规范",而是一套能够持续抵抗复杂度增长的工程护城河。
参考与延伸阅读
- 知识星球·码农会所 - DDD 架构模式讲解(需登录)
- 知识星球·码农会所 - DDD 讲解(需登录)
- 本地笔记:DDD 分层架构模式
- 本地笔记:什么是DDD领域驱动设计
- Eric Evans《领域驱动设计》(蓝皮书)
- Vaughn Vernon《实现领域驱动设计》(红皮书)
素材与出处
引用来源说明
| 原始引用 | 归属 | 状态 |
|---|---|---|
[DDD 架构模式]() | 同目录 Obsidian 笔记 | ✅ 双链可直接跳转 |
[什么是DDD领域驱动设计](/%E6%9E%B6%E6%9E%84%E7%AF%87/%E4%B8%9A%E5%8A%A1%E5%9C%BA%E6%99%AF%E5%92%8C%E6%8A%80%E6%9C%AF%E9%80%89%E5%9E%8B/%E7%B3%BB%E7%BB%9F%E6%9E%B6%E6%9E%84%E8%AE%BE%E8%AE%A1/DDD%20%E8%84%9A%E6%89%8B%E6%9E%B6/%E4%BB%80%E4%B9%88%E6%98%AF%20DDD%E9%A2%86%E5%9F%9F%E9%A9%B1%E5%8A%A8%E8%AE%BE%E8%AE%A1) | 1.5.10.3.1/ Obsidian 笔记 | ✅ 双链可直接跳转 |
https://wx.zsxq.com/.../topic/411244188545488 | 知识星球·码农会所 | ⚠️ 需登录访问 |
https://wx.zsxq.com/.../topic/814214221828412 | 知识星球·码农会所 | ⚠️ 需登录访问 |
图片来源说明
| 图片 | 远程 URL | 用途 |
|---|---|---|
| DDD 分层总览图 | oss.../20260308174112.png | 正文第二节 |
| 依赖方向示意图 | oss.../20260326013231.png | 正文第三节 |
| 上下文通信示意图 | oss.../20260326015025.png | 正文第四节 |
| 各层模块结构图 | oss.../20241002075533.png | 备用,未插入正文 |
抓取脚本说明
知识星球链接需要登录 Cookie 方可访问,已备存抓取脚本于: custom-scripts/cc-blogout/fetch_zsxq.py(pandoc 不可用,改用 Python urllib 方案)