Appearance
本章节主要讲述:Java中对象的使用,Object 基类的使用,以及 String 类的使用。
一、面向对象基础
1.1、面向对象和面向过程的区别
两者的主要区别在于解决问题的方式不同:
- 面向过程把解决问题的过程拆成一个个方法,通过一个个方法的执行解决问题。
- 面向对象会先抽象出对象,然后用对象执行方法的方式解决问题。
1.2、创建对象
new 运算符,new 创建对象实例(对象实例在堆内存中),对象引用指向对象实例(对象引用存放在栈内存中)。
- 一个对象引用可以指向 0 个或 1 个对象(一根绳子可以不系气球,也可以系一个气球);
- 一个对象可以有 n 个引用指向它(可以用 n 条绳子系住一个气球)。
对象的相等和引用相等的区别
- 对象的相等一般比较的是内存中存放的内容是否相等。
- 引用相等一般比较的是他们指向的内存地址是否相等。
对象是什么?
对象是类的一个实例,类定义了对象的状态(属性)和行为(方法)
创建对象的步骤:
- 定义类: 首先,需要定义一个类,作为对象的蓝图。类定义了对象的属性和方法。
- 声明对象: 接下来,声明一个类的变量。这个变量将引用新创建的对象。
- 实例化对象: 使用
new关键字创建类的一个实例。 - 初始化对象: 通过调用类的构造器来初始化新创建的对象
创建对象示例:
// 定义Person类
class Person {
String name;
int age;
Person(String name, int age) {
this.name = name;
this.age = age;
}
}
// 在另一个类中创建Person的对象
public class Main {
public static void main(String[] args) {
// 创建Person对象
Person person = new Person("Alice", 30);
}
}在这个例子中,new Person("Alice", 30); 创建了一个 Person 类的实例,并且用 Alice 和 30 初始化这个对象的 name 和 age 属性。
1.3、构造方法
构造方法的作用:构造方法是一种特殊的方法,主要作用是完成对象的初始化工作。
如果没有声明构造方法,类会有一个默认的不带参数的改造方法。
构造方法的特点:
- 名字与类名相同。
- 没有返回值,但不能用 void 声明构造函数。
- 生成类的对象时自动执行,无需调用。
构造方法不能被 override(重写),但是可以 overload(重载),所以你可以看到一个类中有多个构造函数的情况
1.4、面向对象特征
面向对象的三大特征:
- 封装
- 继承
- 多态
面向对象编程(OOP)的三大特征是封装、继承和多态。这些特征共同为创建模块化、可重用和易于维护的代码提供了基础。
| 特征 | 描述 | 优点 |
|---|---|---|
| 封装 | 封装是把数据(属性)和行为(方法)组合成一个单元(类),并对数据的访问进行限制和保护。在Java中,可以通过使用访问修饰符(如private, public)来实现。 | - 提高了数据安全性 - 减少了代码间的耦合 - 增强了代码的可读性和可维护性 |
| 继承 | 继承是一种使得一个类(子类)能够继承另一个类(父类)的属性和方法的机制。子类可以扩展或修改继承自父类的行为。 | - 促进了代码的重用 - 建立了类之间的层次关系 - 提高了代码的可维护性 |
| 多态 | 多态是指允许不同类的对象对同一消息作出响应的能力,即同一操作作用于不同的对象时可以有不同的解释和行为。 | - 增强了程序的灵活性和扩展性 - 允许不同类的对象被统一处理 |
类比
- 封装: 就像一个咖啡机,它隐藏了内部的复杂机械过程,只暴露出简单的接口(按钮)给用户使用。
- 继承: 类似于父母与孩子的关系。孩子会继承父母的一些特征(如眼睛的颜色),同时也可以发展自己独特的特性(如不同的职业技能)。
- 多态: 可以比作一个通用的电源插座。不同的电器(即使是不同类型的电器)都可以插入同一个插座,但插入后的行为(如充电、运转)依赖于接入的具体电器。
1.5、接口与抽象类
接口和抽象类的区别
- 首先是类和接口的区别,接口可以实现多个接口,类只能继承单个;
- 然后更多的是用法上面的区别:接口是一个协议,强调功能的相似性(相同的行为);抽闲类强调的是类之间的共性(公共类结构)。
接口(Interfaces)和抽象类(Abstract Classes)是用于实现抽象层次的两种主要方式。
它们都不能被实例化,但在用法和目的上存在一些关键区别。
对比
| 特征 | 接口(Interfaces) | 抽象类(Abstract Classes) |
|---|---|---|
| 实例化 | 不能直接实例化。 | 也不能直接实例化。 |
| 方法定义 | 可以有默认方法和静态方法。所有方法默认为public。不需要使用abstract关键字。 | 可以包含抽象方法(没有实现体的方法)和非抽象方法。抽象方法使用abstract关键字。 |
| 属性定义 | 只能定义常量(默认为public static final)。 | 可以包含非常量字段,且这些字段可以有各种访问控制。 |
| 实现/扩展 | 一个类可以实现多个接口。 | 一个类只能继承一个抽象类。 |
| 构造器 | 不能有构造器。 | 可以有构造器。 |
| 多重继承的支持 | 支持(一个类可以实现多个接口)。 | 不支持(一个类只能继承一个类,但可以实现多个接口)。 |
| 默认方法 | Java 8之后,接口可以有默认方法(有方法体)。 | 抽象类可以有具有实现的方法。 |
| 访问修饰符限制 | 接口中的方法默认是public的,属性默认是public static final的。 | 抽象类中的方法和属性可以有多种访问修饰符。 |
| 使用场景 | 当各个实现之间没有共享的代码,但需要共同遵守某些规则(方法)时使用。 | 当各个实现之间有大量共享的代码或属性时使用。 |
类比
- 接口: 就像一个标准或协议,它定义了规范,但不提供完整的实现。就像电器的插头和插座的标准,制造商需要按照这个标准制造产品。
- 抽象类: 可以看作是半成品,它定义了一些基本功能和结构,但留下了一些空白(抽象方法)供继承它的子类完成。
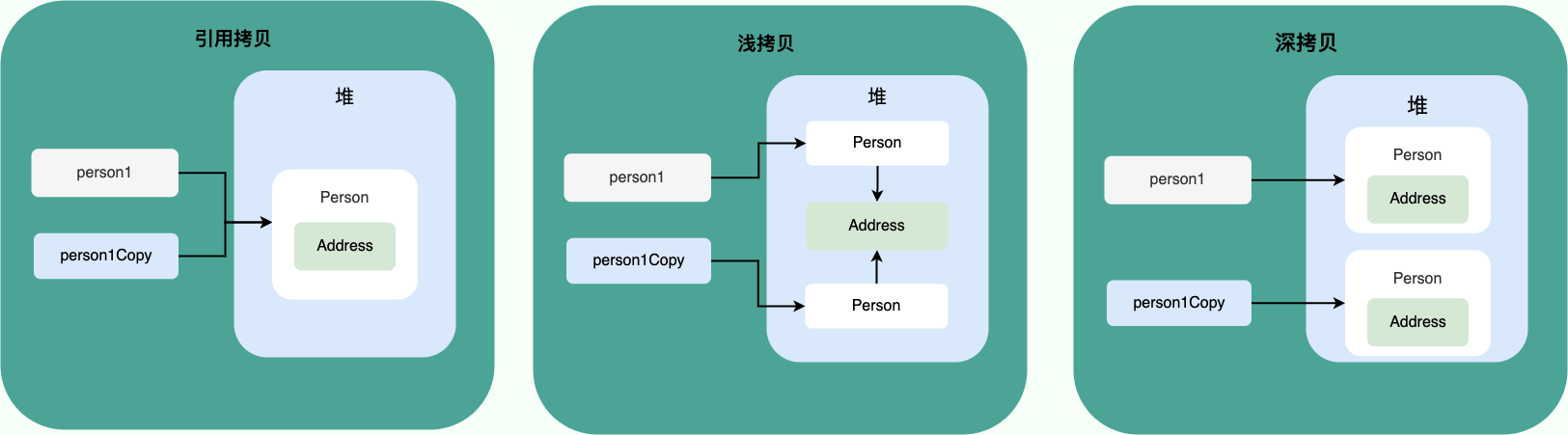
1.6、深拷贝与浅拷贝,引用拷贝
区别:
- 浅拷贝:浅拷贝会在堆上创建一个新的对象(区别于引用拷贝的一点),不过,如果原对象内部的属性是引用类型的话,浅拷贝会直接复制内部对象的引用地址,也就是说拷贝对象和原对象共用同一个内部对象。
- 深拷贝:深拷贝会完全复制整个对象,包括这个对象所包含的内部对象
对比
| 类型 | 描述 | 结果 |
|---|---|---|
| 浅拷贝 | 只复制对象的基本类型字段和引用类型字段的引用,不复制引用对象本身。 | 两个对象共享引用类型的成员。 |
| 深拷贝 | 复制对象的所有字段,包括基本类型和引用类型字段,引用类型的对象也会被复制。 | 两个对象完全独立,不共享任何成员。 |
| 引用拷贝 | 只复制对象的引用,不复制对象本身。 | 两个引用指向同一个对象,任何一个对象的改变都会影响到另一个。 |
类比
- 浅拷贝: 就像拍摄一张画作的照片,你得到的是画作的表面复制品,但它仍然连接着原来的画。
- 深拷贝: 就像复制一个画作的每一笔细节来创建一个全新的画作,完全独立于原作。
- 引用拷贝: 就像给别人画作的一个指向地址,两人看的是同一幅画。
图描述:
1.7、内部类
什么是内部类
内部类是定义在另一个类内部的类。在Java中,内部类主要用于将一些逻辑密切相关的类组织在一起,从而提供更好的封装和维护性。
内部类提供了一种强大的方式来组织和封装复杂的逻辑,但同时也增加了代码的复杂性。因此,在使用内部类时应该权衡其带来的好处和复杂性。
基本概念:
- 内部类可以访问其外部类的成员,包括私有成员。
- 内部类的对象与其外部类的对象之间存在联系。
内部类的类型
- 成员内部类(非静态内部类):定义在外部类的成员位置,需要外部类的实例来创建。
- 静态内部类:用
static修饰的内部类,不需要外部类的实例就可以创建。 - 局部内部类:定义在方法内的类,只在该方法的作用域内可见和可用。
- 匿名内部类:没有名字的局部内部类,通常用于创建那些只需要一次使用的类实例。
详细一些的解释:
成员内部类:
- 定义在外部类的成员位置。
- 可以访问外部类的所有成员,包括私有成员。
- 需要外部类的实例来创建。
- 语法:
OuterClass.InnerClass innerObject = outerObject.new InnerClass();
静态内部类:
- 用
static修饰,是外部类的静态成员。 - 可以不依赖于外部类实例被创建。
- 只能访问外部类的静态成员。
- 语法:
OuterClass.StaticInnerClass innerObject = new OuterClass.StaticInnerClass();
局部内部类:
- 定义在方法内部。
- 只能在定义它的方法中被使用。
- 可以访问外部类的所有成员和方法内的final局部变量。
匿名内部类:
- 没有名称的局部内部类。
- 通常用于实现接口或继承抽象类的临时需求。
- 语法:
new InterfaceName() { /* 实现 */ }或new ClassName() { /* 扩展 */ }。
使用示例
// 示例:成员内部类、静态内部类、局部内部类和匿名内部类的使用
class OuterClass {
private String outerField = "Outer";
// 成员内部类
class MemberInnerClass {
void display() {
System.out.println("Member Inner Class: " + outerField);
}
}
// 静态内部类
static class StaticInnerClass {
void display() {
System.out.println("Static Inner Class");
}
}
void test() {
// 局部内部类
class LocalInnerClass {
void display() {
System.out.println("Local Inner Class: " + outerField);
}
}
LocalInnerClass localInner = new LocalInnerClass();
localInner.display();
}
// 匿名内部类
Runnable getRunnable() {
return new Runnable() {
@Override
public void run() {
System.out.println("Anonymous Inner Class");
}
};
}
}
public class Main {
public static void main(String[] args) {
OuterClass outer = new OuterClass();
// 使用成员内部类
OuterClass.MemberInnerClass memberInner = outer.new MemberInnerClass();
memberInner.display();
// 使用静态内部类
OuterClass.StaticInnerClass staticInner = new OuterClass.StaticInnerClass();
staticInner.display();
// 使用局部内部类
outer.test();
// 使用匿名内部类
Runnable runnable = outer.getRunnable();
runnable.run();
}
}匿名内部类
参考: https://www.cnblogs.com/nerxious/archive/2013/01/25/2876489.html
一般使用匿名内部类是用来简化代码编写,匿名内部类一般只使用一次
如何使用:使用匿名内部类需要继承一个父类或实现一个接口
//当不使用匿名内部类的情况
abstract class Person {
public abstract void eat();
}
class Child extends Person {
public void eat() {
System.out.println("eat something");
}
}
public class Demo {
public static void main(String[] args) {
Person p = new Child();
p.eat();
}
}
//当使用匿名内部类的情况
//匿名内部类的基本实现
abstract class Person {
public abstract void eat();
}
public class Demo {
public static void main(String[] args) {
Person p = new Person() {
public void eat() {
System.out.println("eat something");
}
};
p.eat();
}
}
//在接口上使用匿名内部类
interface Person {
public void eat();
}
public class Demo {
public static void main(String[] args) {
Person p = new Person() {
public void eat() {
System.out.println("eat something");
}
};
p.eat();
}
}
//Thread类的匿名内部类实现
public class Demo {
public static void main(String[] args) {
Thread t = new Thread() {
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.print(i + " ");
}
}
};
t.start();
}
}
//Runnable接口的匿名内部类实现
public class Demo {
public static void main(String[] args) {
Runnable r = new Runnable() {
public void run() {
for (int i = 1; i <= 5; i++) {
System.out.print(i + " ");
}
}
};
Thread t = new Thread(r);
t.start();
}
}二、Object
2.1 Object 类的常用方法
Object 类是一个特殊的类,是所有类的父类。它主要提供了以下 11 个方法:
/**
* native 方法,用于返回当前运行时对象的 Class 对象,使用了 final 关键字修饰,故不允许子类重写。
*/
public final native Class<?> getClass()
/**
* native 方法,用于返回对象的哈希码,主要使用在哈希表中,比如 JDK 中的HashMap。
*/
public native int hashCode()
/**
* 用于比较 2 个对象的内存地址是否相等,String 类对该方法进行了重写以用于比较字符串的值是否相等。
*/
public boolean equals(Object obj)
/**
* native 方法,用于创建并返回当前对象的一份拷贝。
*/
protected native Object clone() throws CloneNotSupportedException
/**
* 返回类的名字实例的哈希码的 16 进制的字符串。建议 Object 所有的子类都重写这个方法。
*/
public String toString()
/**
* native 方法,并且不能重写。唤醒一个在此对象监视器上等待的线程(监视器相当于就是锁的概念)。如果有多个线程在等待只会任意唤醒一个。
*/
public final native void notify()
/**
* native 方法,并且不能重写。跟 notify 一样,唯一的区别就是会唤醒在此对象监视器上等待的所有线程,而不是一个线程。
*/
public final native void notifyAll()
/**
* native方法,并且不能重写。暂停线程的执行。注意:sleep 方法没有释放锁,而 wait 方法释放了锁 ,timeout 是等待时间。
*/
public final native void wait(long timeout) throws InterruptedException
/**
* 多了 nanos 参数,这个参数表示额外时间(以纳秒为单位,范围是 0-999999)。 所以超时的时间还需要加上 nanos 纳秒。。
*/
public final void wait(long timeout, int nanos) throws InterruptedException
/**
* 跟之前的2个wait方法一样,只不过该方法一直等待,没有超时时间这个概念
*/
public final void wait() throws InterruptedException
/**
* 实例被垃圾回收器回收的时候触发的操作
*/
protected void finalize() throws Throwable { }以下是Java中 Object 类的常用方法的总结,包括每个方法的功能和特性:
| 方法签名 | 返回类型 | 描述 | 特性 |
|---|---|---|---|
public final native Class<?> getClass() | Class<?> | 返回当前运行时对象的Class对象。 | 使用 final 和 native 关键字,不能被子类重写 |
public native int hashCode() | int | 返回对象的哈希码,主要用于哈希表。 | native 方法,通常与 equals() 方法一起使用。 |
public boolean equals(Object obj) | boolean | 比较两个对象的内存地址是否相等。String类重写了此方法来比较字符串值。 | 可被子类重写以提供相等性逻辑。 |
protected native Object clone() | Object | 创建并返回当前对象的一份拷贝。 | native 方法,类必须实现 Cloneable 接口才能使用此方法。 |
public String toString() | String | 返回对象的字符串表示,通常包括类名和哈希码的16进制字符串。 | 建议所有子类重写此方法。 |
public final native void notify() | void | 唤醒在此对象监视器上等待的单个线程。 | 使用 final 和 native 关键字,不能被子类重写。 |
public final native void notifyAll() | void | 唤醒在此对象监视器上等待的所有线程。 | 使用 final 和 native 关键字,不能被子类重写。 |
public final native void wait(long timeout) | void | 使当前线程等待直到另一个线程调用 notify() 或 notifyAll(),或超时。 | 使用 final 和 native 关键字,不能被子类重写。释放对象的锁。 |
public final void wait(long timeout, int nanos) | void | 使当前线程等待直到另一个线程调用 notify() 或 notifyAll(),或超时加额外纳秒。 | 使用 final 关键字,不能被子类重写。释放对象的锁。 |
public final void wait() | void | 使当前线程无限期等待,直到另一个线程调用 notify() 或 notifyAll()。 | 使用 final 关键字,不能被子类重写。释放对象的锁。 |
protected void finalize() | void | 在对象被垃圾回收器回收时触发的操作。 | 在Java 9中被弃用,但子类可以重写以进行清理操作。 |
这些方法提供了对象行为的基本框架,从对象的生命周期管理到线程间的通信。
2.2 == 和 equals() 的区别
== 对于基本类型和引用类型的作用效果是不同的:
- 对于基本数据类型来说,== 比较的是值。
- 对于引用数据类型来说,== 比较的是对象的内存地址。
在Java中,== 运算符和equals()方法用于比较两个对象,但它们在比较方式上有本质的不同。
== 运算符
用途: 主要用于比较基本数据类型的值和引用类型的地址。
对基本类型: 比较两个基本类型的值是否相同(例如,
int,char,double等)。对引用类型: 比较两个对象引用是否指向内存中的同一位置。
equals()方法
用途: 主要用于比较两个对象的内容或状态是否相等。
默认行为: 在
Object类中定义的equals()方法默认行为与 == 相同,即比较对象的内存地址。重写: 多数类,如
String,Date等,都重写了equals()方法来进行逻辑比较,即比较对象的内容而不是内存地址。
表格比较
| 特性 | == 运算符 | equals() 方法 |
|---|---|---|
| 比较类型 | 基本数据类型的值 / 引用类型的内存地址 | 对象内容(可重写) |
| 默认行为 | 比较内存地址(对于引用类型) | 在 Object 类中也是比较内存地址 |
| 可重写性 | 不可重写 | 可以重写以提供自定义比较逻辑 |
| 使用场景 | 当需要检查两个变量是否指向相同的对象时使用 | 当需要检查两个对象是否在逻辑上相等时使用 |
| 例子 | a == b(对于基本类型或检查两个引用是否指向同一对象) | a.equals(b)(对于检查两个对象的内容是否相等) |
类比
== 运算符: 就像检查两张名片上的地址是否一样,即使两张名片属于同一人,但如果地址不同,结果就是不相等。
equals()方法: 就像比较两个人的面貌,即使他们住在不同的地方(不同的内存地址),只要面貌相同(内容相同),就认为他们相等。
扩展的一些问题:
to be conteind...
2.3 hashCode 有什么用
hashCode() 的作用是获取哈希码(int 整数),也称为散列码。这个哈希码的作用是确定该对象在哈希表中的索引位置。
hashCode() 定义在 JDK 的 Object 类中,这就意味着 Java 中的任何类都包含有 hashCode() 函数。另外需要注意的是:Object 的 hashCode() 方法是本地方法,也就是用 C 语言或 C++ 实现的。
public native int hashCode();散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
hashCode() 和 equals() 方法
- 如果两个对象的
hashCode值相等,那这两个对象不一定相等(哈希碰撞)。 - 如果两个对象的
hashCode值相等并且equals()方法也返回true,我们才认为这两个对象相等。 - 如果两个对象的
hashCode值不相等,我们就可以直接认为这两个对象不相等。
为什么重写 equals() 时必须重写 hashCode() 方法?
因为两个相等的对象的 hashCode 值必须是相等。也就是说如果 equals 方法判断两个对象是相等的,那这两个对象的 hashCode 值也要相等。
如果重写 equals() 时没有重写 hashCode() 方法的话就可能会导致 equals 方法判断是相等的两个对象,hashCode 值却不相等。
思考:重写 equals() 时没有重写 hashCode() 方法的话,使用 HashMap 可能会出现什么问题。
如果没有重写哈希函数的话,两个键获取哈希表位置索引可能会不对,造成一些现象,比如:在集合中查找对象时可能会失败,即使该对象已经存在;即使使用一个逻辑上相等的键去查找,也可能无法找到对应的值,导致数据访问上的问题等。
散列表
散列表(Hash table,也叫哈希表),是根据键(Key)而直接访问在存储器存储位置的数据结构。也就是说,它通过计算出一个键值的函数,将所需查询的数据映射到表中一个位置来让人访问,这加快了查找速度。
这个映射函数称做散列函数,存放记录的数组称做散列表。
一个通俗的例子是,
为了查找电话簿中某人的号码,可以创建一个按照人名首字母顺序排列的表(即建立人名 x 到首字母 F(x) 的一个函数关系),在首字母为W的表中查找“王”姓的电话号码,显然比直接查找就要快得多。这里使用人名作为关键字,“取首字母”是这个例子中散列函数的函数法则 F( ),存放首字母的表对应散列表。关键字和函数法则理论上可以任意确定。
哈希表
哈希表(Hash Table)其实也叫散列表,是一个数据结构。
哈希表本质上就是一个数组,只不过数组存放的是单一的数据,而哈希表中存放的是键值对(key - value pair)
key 通过哈希函数(hash function)得到数组的索引,进而存取索引位置的值。
不同的 key 通过哈希函数可能得到相同的索引值,此时,产生了哈希碰撞。
通过在数组中插入链表或者二叉树,可以解决哈希碰撞问题。
三、String
3.1 String、StringBuffer、StringBuilder 的区别?
| 特性 | String | StringBuffer | StringBuilder |
|---|---|---|---|
| 可变性 | 不可变 | 可变 | 可变 |
| 线程安全 | 是 | 是 | 否 |
| 性能 | 较低(对于频繁修改) | 高(线程安全) | 高(非线程安全) |
| 用途 | 文本不频繁改变时 | 多线程中文本频繁改变 | 单线程中文本频繁改变 |
String 是通过 final 进行修饰的,我们每次对String对象的修改实际都会生成一个新的String对象。
StringBuffer和StringBuilder的默认容量大小都是16个字符。
3.2 String 为什么是不可变的
String 真正不可变有下面几点原因:
- 保存字符串的数组被
final修饰且为私有的,并且String类没有提供/暴露修改这个字符串的方法。 String类被final修饰导致其不能被继承,进而避免了子类破坏String不可变
3.3 字符串拼接用“+” 还是 StringBuilder?
Java 语言本身并不支持运算符重载,“+”和“+=”是专门为 String 类重载过的运算符,也是 Java 中仅有的两个重载过的运算符。
在JDK8中,字符串对象通过“+”的字符串拼接方式,实际上是通过 StringBuilder 调用 append() 方法实现的,拼接完成之后调用 toString() 得到一个 String 对象 。
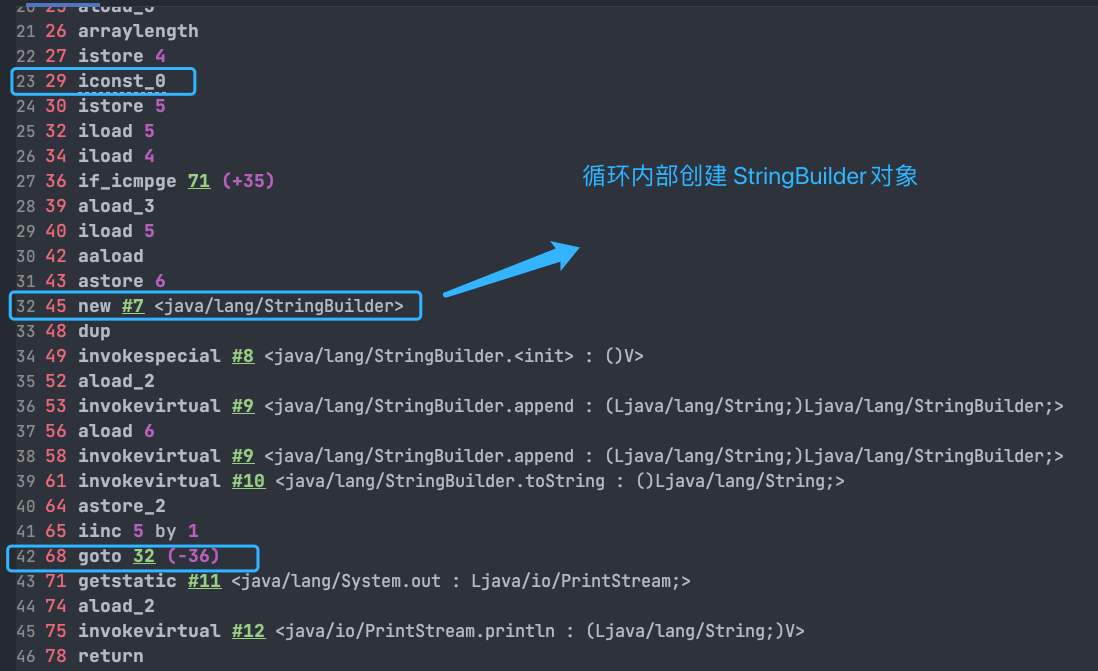
不过,在循环内使用“+”进行字符串的拼接的话,存在比较明显的缺陷:编译器不会创建单个 StringBuilder 以复用,会导致创建过多的 StringBuilder 对象。
String str1 = "he";
String str2 = "llo";
String str3 = "world";
String str4 = str1 + str2 + str3;对应字节码

String[] arr = {"he", "llo", "world"};
String s = "";
for (int i = 0; i < arr.length; i++) {
s += arr[i];
}
System.out.println(s);StringBuilder 对象是在循环内部被创建的,这意味着每循环一次就会创建一个 StringBuilder 对象
如果直接使用 StringBuilder 对象进行字符串拼接的话,就不会存在这个问题。
String[] arr = {"he", "llo", "world"};
StringBuilder s = new StringBuilder();
for (String value : arr) {
s.append(value);
}
System.out.println(s);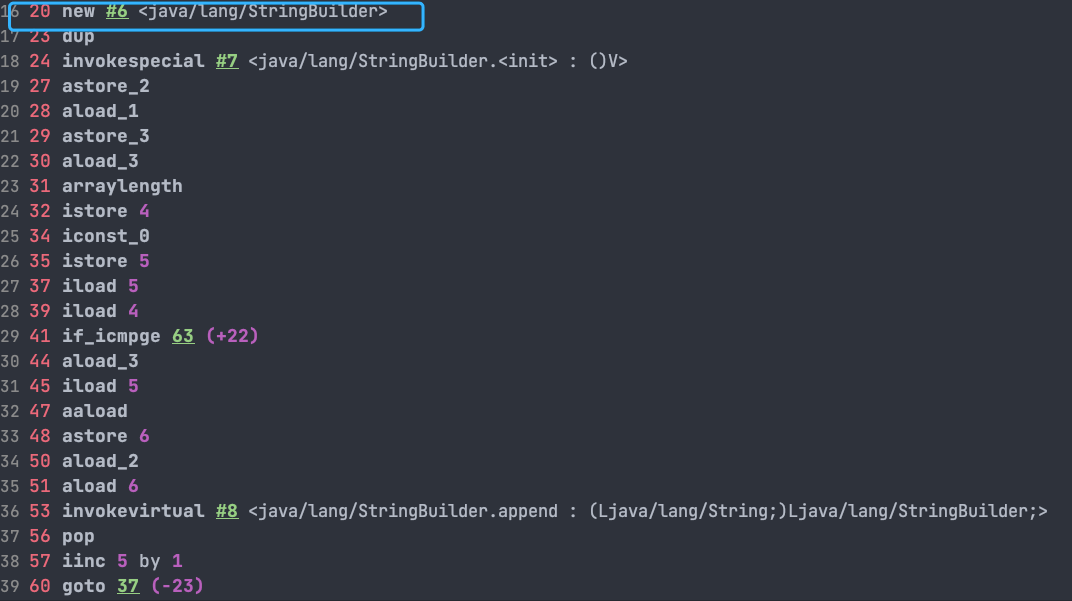
而在 JDK9中,字符串相加 “+” 改为了用动态方法 makeConcatWithConstants() 来实现,而不是大量的 StringBuilder;这也意味着 JDK 9 之后,我们可以放心使用“+” 进行字符串拼接。
3.4 String#equals() 和 Object#equals() 有何区别
String 中的 equals 方法是被重写过的,比较的是 String 字符串的值是否相等。 Object 的 equals 方法是比较的对象的内存地址。
3.5 字符串常量池 🐎
字符串常量池 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建。
// 在堆中创建字符串对象”ab“
// 将字符串对象”ab“的引用保存在字符串常量池中
String aa = "ab";
// 直接返回字符串常量池中字符串对象”ab“的引用
String bb = "ab";
System.out.println(aa==bb);// true说一下字符串常量池在JVM中的位置
字符串常量池是被存放在方法区这个位置;方法区 1.7 之前是叫永久代;1.8 之后是叫元空间(存放在本地内存)
说一下 方法区和 堆的区别,主要说一下存放内容的差别:
- 方法区:
- 存储已被虚拟机加载的类信息、常量、静态变量、即时编译后的代码等数据。
- 方法区存储类结构(如运行时常量池、字段、方法数据)等。
- 堆:存储对象实例和数组,是垃圾收集器管理的主要区域,也是Java应用最大的内存消耗区域。
最近也看到了字符串常量池的相关概念,通过直接赋值的方式创建的Stirng 字符串是存放在了常量池的位置;
而通过 new 的方式是放到了 堆内存。
// 示例:String的创建方式
String s1 = "a"; // 字符串常量池
String s2 = new String("a"); // 堆内存当您在Java中使用String s = "a";和String s = new String("a");这两种方式创建字符串时,它们在内存中的存储方式不同。
String s = "a";:- 这种方式创建的字符串对象存储在字符串常量池中。
- 字符串常量池位于Java堆内存中,但它是一块特殊的存储区域,专门用于存放字符串常量。
- 如果字符串常量池已经包含了一个等于
"a"的字符串,那么s1将指向这个已存在的字符串,而不是创建一个新的。
String s = new String("a");:- 这种方式创建的字符串对象存储在堆内存中。
- 使用
new关键字会强制在堆内存中创建一个新的String对象,即使字符串常量池中已经存在一个相同内容的字符串。 - 这意味着即使内容相同,
s2也是一个全新的对象。
在大多数情况下,推荐使用字符串字面量的方式(如"a"),这样可以更有效地利用Java的字符串常量池,提高性能和减少内存开销。使用new String("a")的方式主要在某些特定场景下使用,例如,当你需要创建一个与常量池中字符串内容相同但是独立的对象时。
3.6 String s1 = new String("abc");这句话创建了几个字符串对象 🐕
会创建 1 或 2 个字符串对象。
to be contined...
3.7 intern 方法
String.intern() 是一个 native(本地)方法,其作用是将指定的字符串对象的引用保存在字符串常量池中
to be contined...
3.8 String 类型的变量和常量做“+”运算时发生了什么
to be contined...
3.9 编码转换
先直接看操作示例代码:
// 示例:String字符串的编码转换
String originalStr = "Hello, 世界"; // 假设这是UTF-8编码的字符串
byte[] bytes;
try {
// 将字符串从UTF-8转换为ISO-8859-1
bytes = originalStr.getBytes("UTF-8");
String newStr = new String(bytes, "ISO-8859-1");
// 将字符串从ISO-8859-1转回UTF-8
bytes = newStr.getBytes("ISO-8859-1");
String finalStr = new String(bytes, "UTF-8");
} catch (UnsupportedEncodingException e) {
e.printStackTrace();
}字符串(String)的编码转换操作步骤:
- 将
String转换为字节数组- 使用
String的getBytes(String charsetName)方法,charsetName是目标编码格式,如"UTF-8"、"ISO-8859-1"等
- 使用
- 从字节数组重新创建
String- 使用
new String(byte[] bytes, String charsetName)构造函数
- 使用
需要注意的是,不是所有的字符都可以在不同的编码之间无损转换。例如,将包含中文字符的字符串从UTF-8转换为ISO-8859-1可能会丢失信息,因为ISO-8859-1编码不支持中文字符。因此,在进行编码转换时,应确保目标编码能够支持源字符串中的所有字符。
此外,处理编码转换时还需要注意UnsupportedEncodingException异常,这种异常会在指定了不支持的字符集时抛出。在实际应用中,应适当处理或抛出这种异常。
3.10 字符串工具类 StringUtils
字符串工具类 isEmpty 和 isBlank 的区别
// 示例:字符串工具类中的 isEmpty 和 isBlank 方法
public class StringUtils {
public static boolean isEmpty(String str) {
return str == null || str.length() == 0;
}
public static boolean isBlank(String str) {
return str == null || str.trim().length() == 0;
}
}- isEmpty 方法会检查字符串是否为 null 以及长度为 0 ;isEmpty(" ") → false
- isBlank 方法会检查字符串是否为 null 以及是否是空字符串; isBlank(" ") → true
四、常用API
Enum
枚举类是JDK1.5引入的一个类型
参考:
枚举类常量
枚举是一个特殊的class, 相当于被 final static修饰,是不能被继承的;同时所有的枚举都继承自java.lang.Enum类, 由于Java 不支持多继承,所以枚举对象不能再继承其他类的
最简单的使用方法是把相关的常量分组到一个枚举类型里,示例如下:
public enum Color {
RED, GREEN, BLANK, YELLOW
}同时 switch 是支持 枚举类型的参数的,也是一种常见的用法;
除此之外,可以看一下向枚举中添加新方法等用法,覆盖枚举方法等操作。
to be contined...
写法规范建议:

参考