Appearance
视频学习: https://www.bilibili.com/video/BV1sp4y1Y7ap
文档学习:略
什么是可回收垃圾对象
gc过程
gc 判断对象是否需要回收有两种判定方法
引用计数算法
引用计数算法,被引用时计数+1,释放引用时-1,计数为0就回收(简单不推荐,解决不了循环引用)
可达性分析算法
将“GCRoots”对象作为起点,从这些节点开始向下搜索引用的对象,找到的对象都标记为非垃圾对象,其余未标记的对象都是垃圾对象
GCRoots 根节点:线程栈的本地变量、静态变量、本地方法栈的变量等等
- 可达性分析算法,就是从gc roots开始往下搜索,走过的对象就是引用链,没有任何引用链时,就是不可达对象,就会被回收(gc roots包含虚拟机栈中引用对象,方法区中静态属性/常量引用对象,本地方法栈中引用对象)
- 如果对象重写了finalize(),并将自身赋予某个引用,那么这个对象不会被回收
- 可以自己调用system.gc或Runtime.getRuntime().gc,都是像系统提交申请进行gc操作,但不会立即gc
比较
- System.gc()调用起来更方便,但是会给应用带来不必要的性能问题。还可以通过参数 -XX:+DisableExplicitGC.禁止显示调用gc。
- Runtime.getRuntime() 用来与Java运行时进行交互,调用该方法会建议JVM 花费精力回收不再使用的对象。
GC Root 对象
哪些对象可以作为 GC Root 对象
GCRoots 根节点:线程栈的本地变量、静态变量、本地方法栈的变量等等
垃圾回收算法
- 1、标记-清除算法,给回收对象标记,然后清除对象,缺点效率不高清除后空间不连续
- 位置不连续,容易产生内存碎片
- 2、标记-整理算法,存活对象整理到一块,清除存活对象以外的数据,缺点整理过程执行较多复制操作,算法效率降低
- 没有碎片,效率较低
- 3、复制算法,就是把回收对象复制到半块地方,原来的地方直接清空,缺点内存缩小一半
- 没有碎片,浪费空间
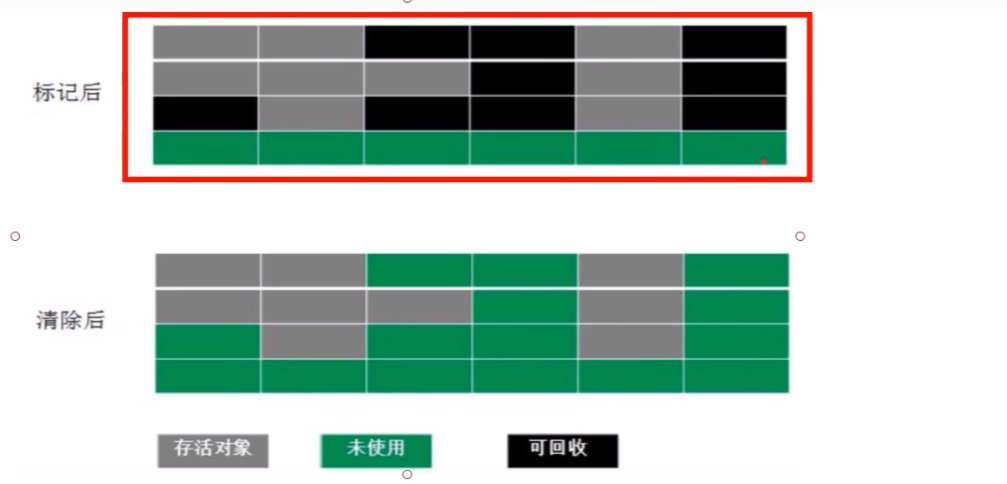
标记-清除算法
给回收对象标记,然后清除对象,缺点效率不高清除后空间不连续
- 位置不连续,容易产生内存碎片
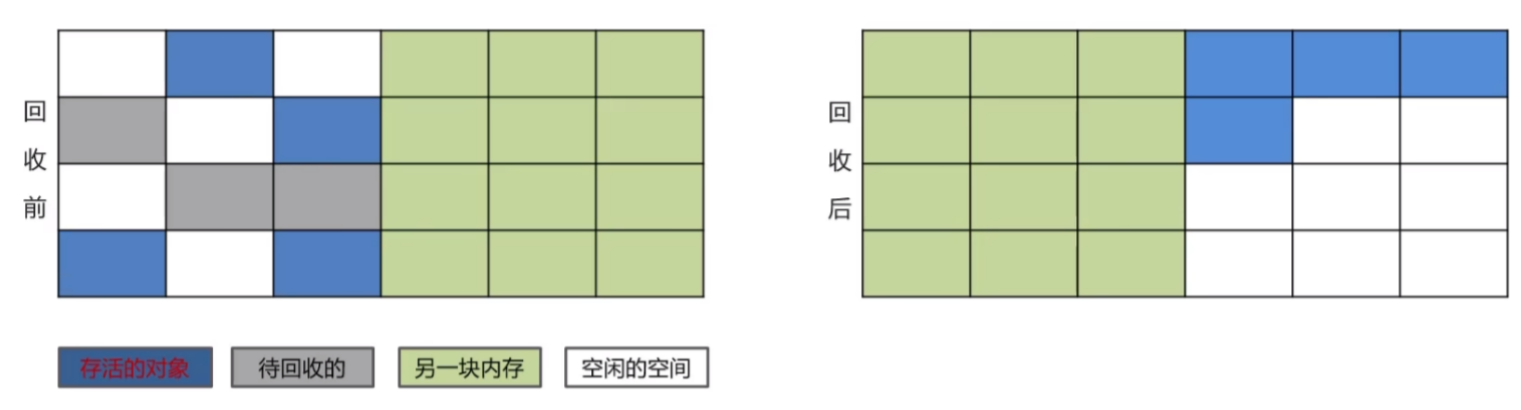
复制算法
把回收对象复制到半块地方,原来的地方直接清空,缺点内存缩小一半
- 没有碎片,浪费空间
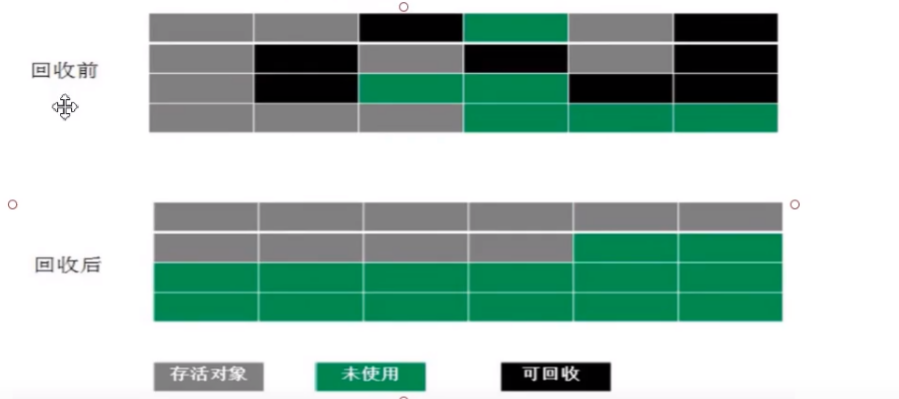
标记-整理算法
存活对象整理到一块,清除存活对象以外的数据,缺点整理过程执行较多复制操作,算法效率降低
- 没有碎片,效率较低
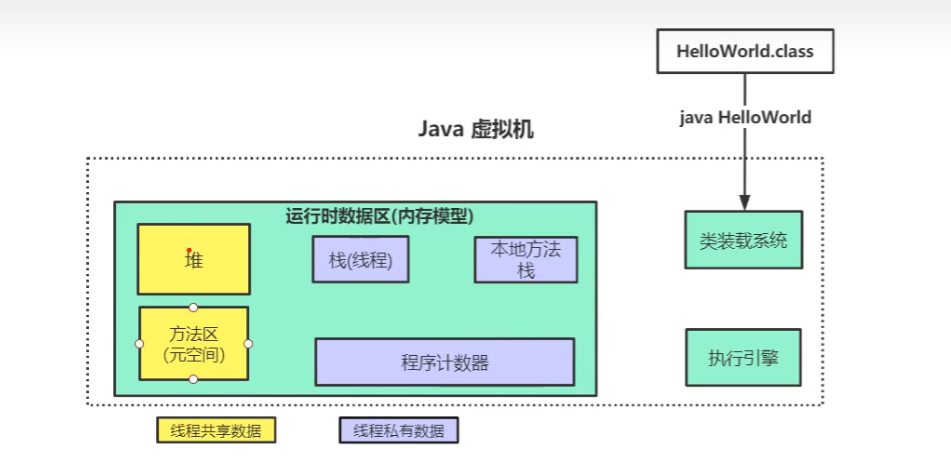
JVM 内存模型
一般会有分代模型和分区模型,在 JDK 1.8 的时候使用的是 分代模型
运行时数据区
线程私有
- 线程共享
堆内存
JDK 1.8 堆内存使用内存模型是分代模型
- 堆
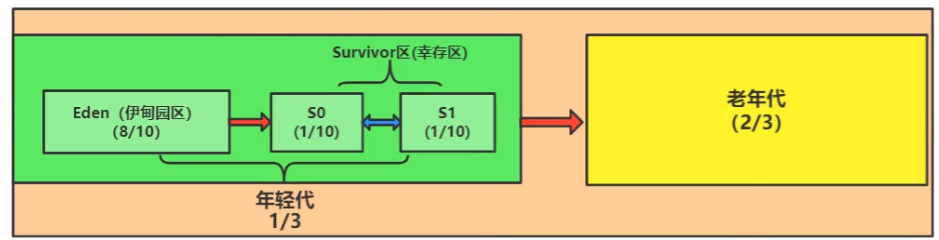
- 年轻代 1/3
- Eden 8
- 一般是朝思夕死的对象,MInor GC 的时候大部分存活的对象不多
- Survivor
- From 1
- To 1
- Eden 8
- 老年代 2/3
- 当对象经历过 15 次 GC,会将该对象从幸存区放入到老年代
- 年轻代 1/3
垃圾回收过程
新创建的对象,放入到 Eden 区,根据可达性分析,判断对象是否可以被回收,如果不可被回收,会通过 复制算法 复制到 to 区域
当对象经历过 15 次 GC,会将该对象从幸存区放入到老年代
- Minor GC/Young GC
- Full GC
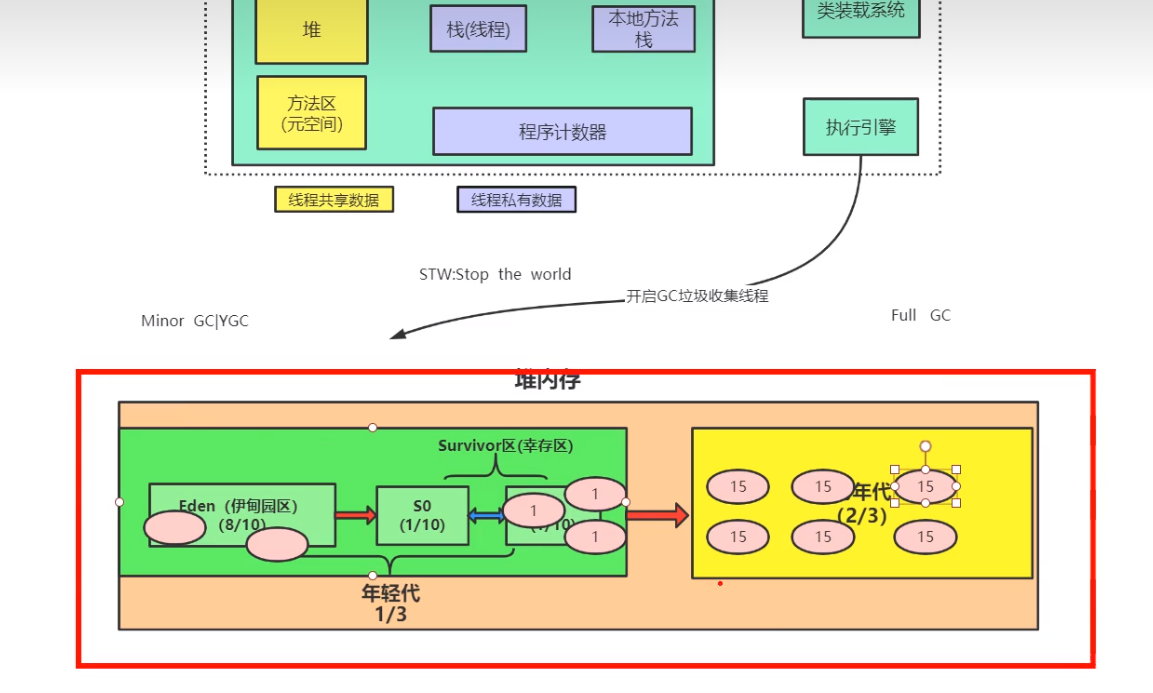
在堆中的对象,首先执行引擎会开启
一、堆的区域划分
- 1.堆被分为了两份:新生代和老年代【1:2】
- 2.对于新生代,内部又被分为了三个区域。Eden区,幸存者区survivor(分成from和to)【8:1:1】
二、对象回收分代回收策略
- 1.新创建的对象,都会先分配到 eden 区
- 2.当伊甸园内存不足,标记伊甸园与from(现阶段没有)的存活对象
- 3.将存活对象采用复制算法复制到to中,复制完毕后,伊甸园和from内存都得到释放
- 4.经过一段时间后伊甸园的内存又出现不足,标记eden区域to区存活的对象,将其复制到from区
- 5.当幸存区对象熬过几次回收(最多15次),晋升到老年代(幸存区内存不足或大对象会提前晋升)
MinorGC、Mixed GC、FullGC的区别是什么
- MinorGC【young GC】发生在新生代的垃圾回收,暂停时间短(STW)
- Mixed GC新生代+老年代部分区域的垃圾回收,G1收集器特有
- FuGC:新生代+老年代完整垃圾回收,暂停时间长(STW),应尽力避免
stw(stop the world)停止用户线程(停止事件)
Full GC 触发:
Full GC(Full Garbage Collection)是指对整个堆内存(包括新生代和老年代)进行垃圾回收的过程。
Full GC通常比单独的新生代GC或老年代GC要慢,因为它需要检查整个堆。(stw 停顿时间会久一些)
触发Full GC的情况可能包括但不限于以下几种:(常见的几种情况)【了解,后面整理一下】
- 老年代空间不足: 当老年代的内存占用接近其最大值时,JVM可能会执行Full GC来释放内存。
- 永久代(PermGen)空间不足(Java 8之前): 永久代用于存储类元数据,当永久代空间不足时,会触发Full GC。
- CMS垃圾回收后的清理: 使用CMS(Concurrent Mark-Sweep)垃圾回收器时,如果并发清理后老年代空间仍然不足,可能会触发Full GC。
- 系统属性设置: 通过JVM参数(如
-XX:+HeapDumpOnOutOfMemoryError)可以设置在 OOM(Out of Memory)异常时进行Full GC。 - 显式调用System.gc(): 虽然调用
System.gc()并不保证一定会执行Full GC,但这会是一个提示给JVM,可能会触发一次Full GC。 - JVM监控到大量的对象死亡和内存回收: 如果新生代GC后,大量的对象从新生代晋升到老年代,JVM可能会认为需要进行Full GC。
- 堆外内存的回收: 如果使用了直接内存(如NIO缓冲区),JVM可能会在清理堆外内存时触发Full GC。
- GC策略和垃圾回收器的选择: 不同的垃圾回收器和GC策略可能在特定条件下触发Full GC。
- 空间分配担保(Space Allocation Guarantee)失败: 在GC后,如果新生代的内存分配失败,JVM可能会尝试进行Full GC。
- 元空间(Metaspace)达到阈值(Java 8及之后): 元空间用于存储类元数据,当达到一定阈值时,可能会触发Full GC。
- 堆内存分配策略: 根据JVM的堆内存分配策略,某些情况下可能会执行Full GC。
- 应用程序特定的行为: 某些应用程序在特定条件下可能会请求执行Full GC
GC 垃圾回收
而系统自己会自动进行gc,在堆区划分俩个空间
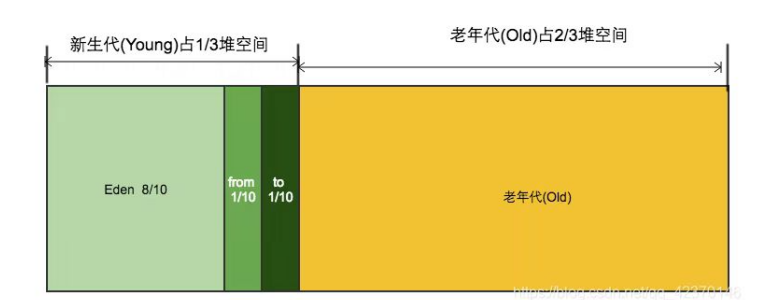
新生对象在新生代的伊甸区创建,如果伊甸区满了,会进行minor gc操作,仅除新生代 未被回收会进入幸存区(from),(大对象直接进入老年区)
在幸存区的对象,每次伊甸区满了进行minor gc操作,存活的计数加1,且从from区复制到to区,from和to交换位置够岁数(15)的对象就直接进入老年代,直到老年代满了,会先执行一次minor gc操作,空间还是不足,就执行full gc,清除整个堆
其中每次gc都会触发stw(stop the world)耗时minor<majoi<full,所以要尽量避免full gc
ps
如果是CMS GC会有老年代后的单独执行major gc操作(非整堆,执行前也会执行一次minor gc比minor gc慢10倍)
如果是G1 GC会进行mixed gc,混合gc,回收整个新生代和部分老年代
垃圾回收调优工具
visualvm
visualvm 插件下载
这里展示一下相关的使用
工具下载地址: https://visualvm.github.io/index.html
插件 下载界面: https://visualvm.github.io/pluginscenters.html
下载地址: https://visualvm.github.io/archive/uc/8u20/updates.html
选择 工具 → 插件 → 已下载 → 选择安装 → 重启
测试类
public class MemoryTest {
byte[] arr = new byte[1024 * 25];
public static void main(String[] args) throws InterruptedException {
List<MemoryTest> ms = new ArrayList<>();
while (true){
ms.add(new MemoryTest());
Thread.sleep(20);
}
}
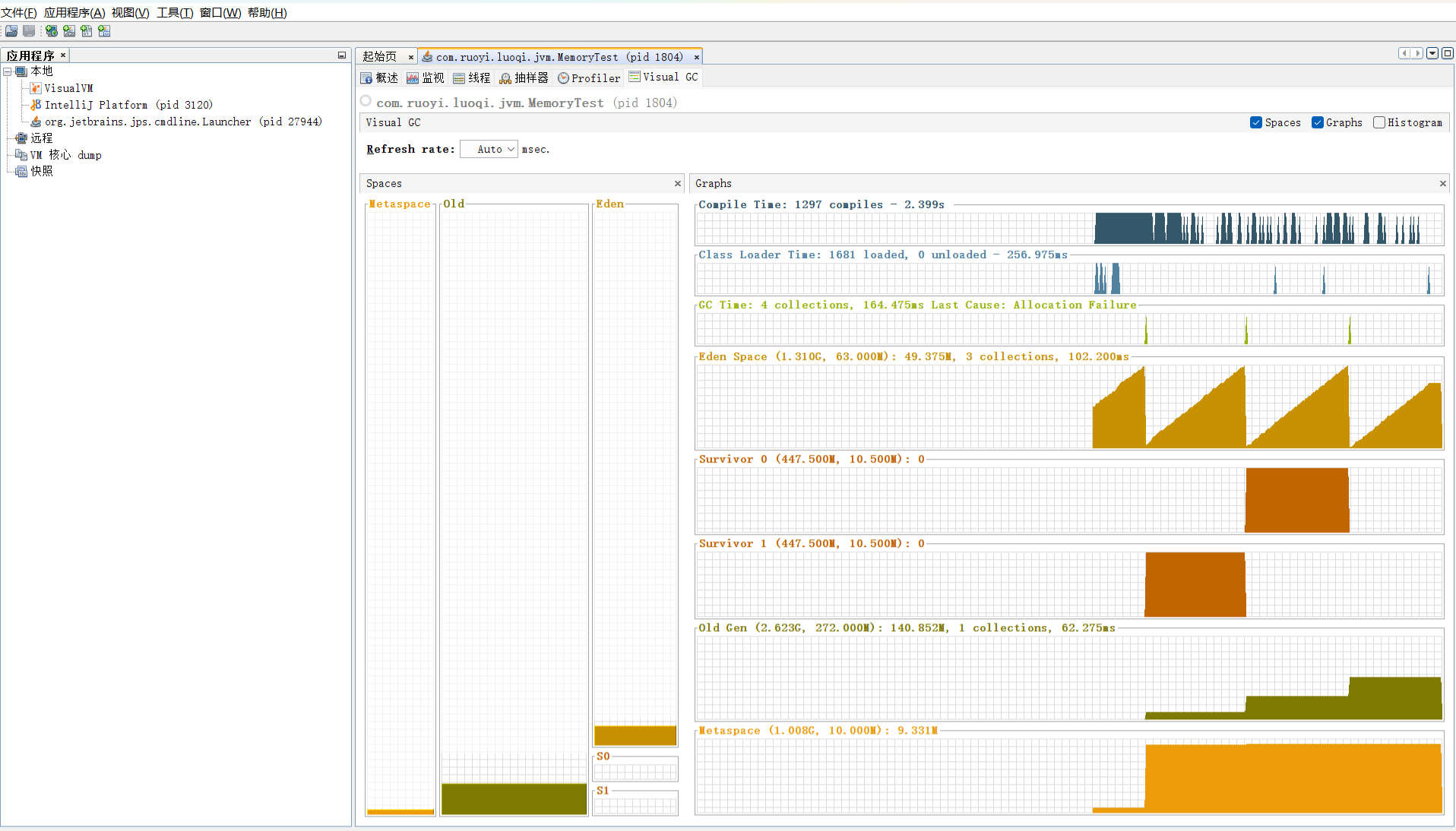
}然后看一下 GC 堆内存图
垃圾收集器
参考: https://www.bilibili.com/video/BV1sp4y1Y7ap
常用垃圾收集器
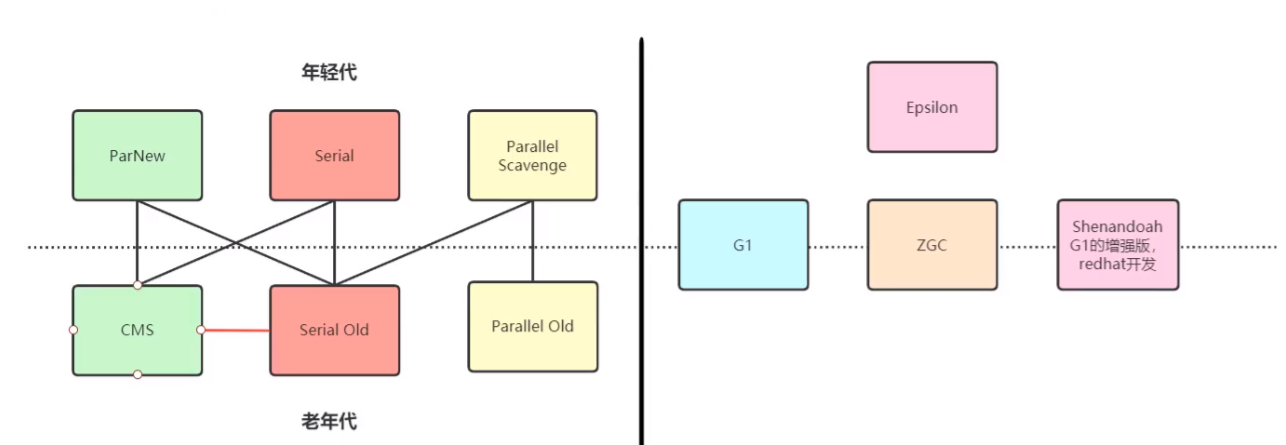
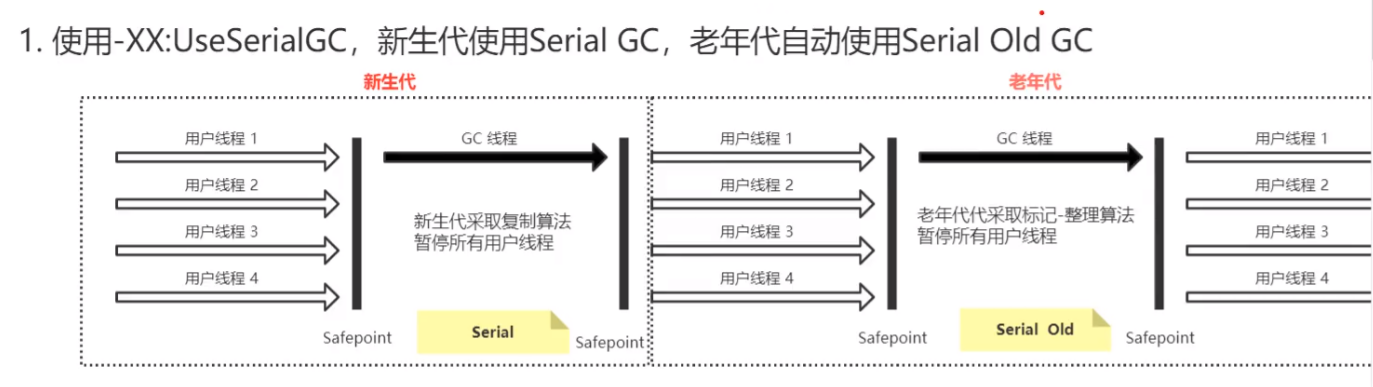
Serial 、Serial Old
在 JDK 1.0,1.2 早期的时候,当时使用的垃圾收集器主要使用的是 Serial + Serial Old 这一对
- Serial 、Serial Old
- Serial 和 Serial Old 是 单线程垃圾收集器,在GC时,只允许⼀个 线程进⾏
- Serial ⽤在年轻代采⽤的是 复制算法、Serial Old ⽤在⽼年代采⽤ 的是 标记整理算法
- 在单核处理器的情况下,简单⾼效,但是多核处理器下⽆法发挥 多核的性能不推荐使⽤,适合 100M以内 内存
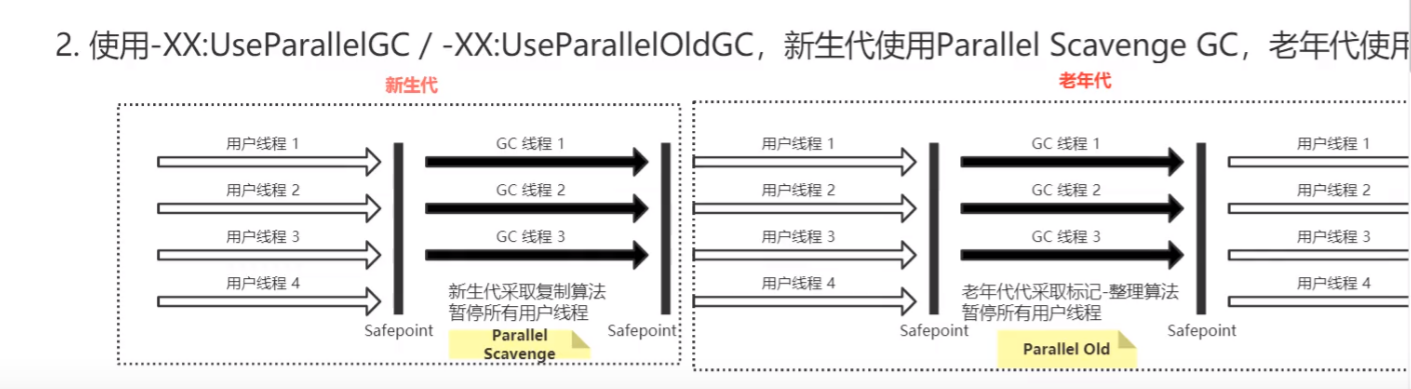
Parallel、Parallel Old
Parallel Scavenge + Parallel Old 是 JDK8 默认使用的垃圾收集器
- Parallel、Parallel Old
- Parallel 和 Parallel Old 是 多线程垃圾收集器,是serial系列的多线 程版本
- Parallel ⽤在年轻代采⽤的是 复制算法,Parallel Old采⽤的是 标 记整理算法
- 关注点在于吞吐量,⽐较适合CPU密集型场景,⼀般 4G以下 内存 推荐使⽤
ParNew 、CMS
ParNew 与 Parallel类似,只是为了配合 CMS 才出现的
ParNew ⽤在年轻代采⽤的是 复制算法, CMS ⽤在⽼年代采⽤的 是 标记清除算法
CMS关注点是最⼤停顿时间,也就是**⽤户的体验度,⽐较适合 4~8G 内存的情况使⽤**
CMS的运作步骤
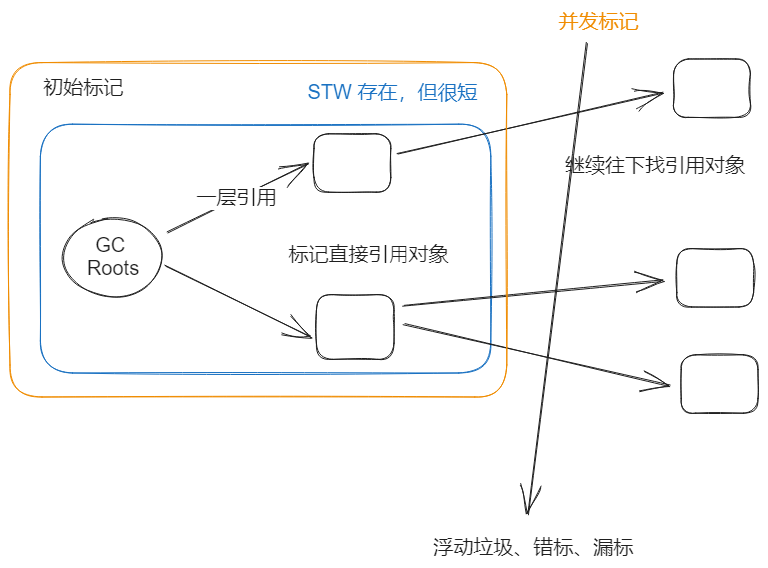
- 初始标记
- STW,从GC Root出发,只标记直接引⽤对象(不包含内部 成员变量相关的间接引⽤对象)
- 并发标记
- 从GC Root的直接引⽤对象出发,遍历整个对象图进⾏标 记,耗时较⻓,由于⽤户线程和GC线程都在运⾏着,所以 会有多标、漏标的问题
- 多标
- 多标 就是本应该是垃圾对象,但是由于⽤户线程还 在运⾏,所以没来及去清除标记
- 漏标
- 漏标 就是 新来的对象引⽤了GC Root链上的对象, 但是由于⽤户线程还在运⾏,没来得及标记为⾮垃 圾,被GC误清除
- 漏标 的处理⽅案主要是 三⾊标记算法,主要分为 增量更新 和 原始快照
- 三⾊标记主要是分为三种颜⾊,分别是⿊⾊、⽩ ⾊、灰⾊
- ⿊⾊对象 表示 当前对象的引⽤对象图都扫描 完了
- 灰⾊对象 表示 当前对象的引⽤对象图只扫描 了⼀部分
- ⽩⾊对象 表示 当前对象的引⽤对象图没扫描
- 增量更新 是通过 记录下⿊⾊对象新增的⽩⾊对 象引⽤关系,将⿊⾊对象回退到灰⾊对象,重新 深度扫描⼀次
- 原始快照 是通过 记录下灰⾊对象删除的⽩⾊对 象的引⽤关系,以灰⾊对象为根简单扫描⼀下, 将⽩⾊对象标记为⿊⾊对象,当作浮动垃圾处 理,等待下⼀轮GC
- 浮动垃圾
- 浮动垃圾 就是在 并发标记 和 并发清理 阶 段产⽣的垃圾,对GC最终效果影响不 ⼤,只要等待下⼀轮GC处理就⾏
- 浮动垃圾
- 三⾊标记主要是分为三种颜⾊,分别是⿊⾊、⽩ ⾊、灰⾊
- 重新标记
- STW,对 并发标记 过程中产⽣状态改变的对象进⾏修正, 这⾥对于 漏标 的问题采⽤的是 三⾊标记算法 中的 增量更 新 来做的重新标记
- 并发清理
- 对未标记的对象进⾏清理,这⾥因为没有进⾏STW,所以 对于新增对象会被标记为⿊⾊对象
- 并发重置
- 将对象的标记位进⾏重置,进⾏下⼀轮GC
- 初始标记
CMS:ConcurrentMarkSweep 并发标记清除
CMS 的出现通过有效减少 STW 的间隔时间(大概百ms左右)
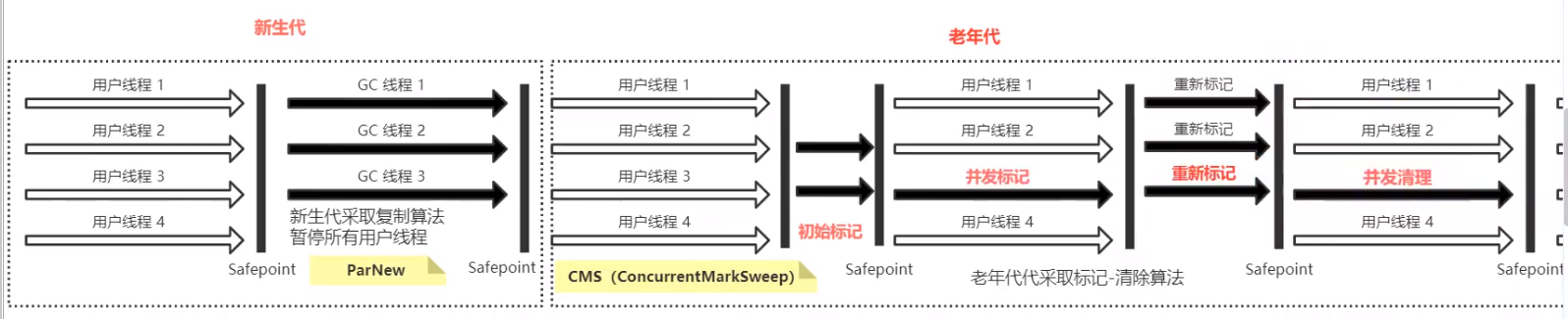
CMS 的执行:初始标记 → 并发标记(中间由于是并行的,会存在多标、漏标的问题) → 重新标记 → 并发清理
G1
JDK1.8 之后的内存模型采用了分区模型的方式
从JDK 9开始,CMS GC已经被标记为废弃,并在JDK 14中被完全移除。因此,对于使用JDK 9及以后版本的应用,推荐使用G1 GC或ZGC等其他低延迟垃圾回收器
分区的话会进行回收部分区域(不一定是回收全部区域)
- G1 跟以往的垃圾收集器有点不同,它对于分代的概念不是物理分 代⽽是逻辑分代了,它将堆默认分成了2048个region,每个region 在每次GC结束后都会有不同的⻆⾊,并且相对于以往的⼤对象, 它也有专⻔的⼀个 Humogous区 来存放,倘若⼀个 Humogous区 放不下⼤对象会⽤连续的⼏个region来存放,对于G1从region来 看采⽤的是复制算法,但是从整体上来看是标记整理算法,G1 和 CMS 的出发点⼀样,但是 G1 ⽐ CMS 更加先进,可控的最⼤停顿 时间,⼀般建议需要500ms以内停顿或者内存超过8G的可以去使 ⽤
- G1的运作步骤
- 初始标记 和 CMS的初始标记 ⼀样
- 并发标记 和 CMS的并发标记 ⼀样
- 最终标记 和 CMS的重新标记 ⼀样,但是这⾥对于 漏标 的对 象采⽤ 原始快照 的⽅式进⾏处理
- 筛选回收
- STW对未标记的 region 进⾏清理,此时会将每个 region 区域 回收价值和成本进⾏排序,根据⽤户的预期停顿时间进⾏ ⽐较来选择合适的回收⽅式,此时并不会把所有垃圾对象 进⾏回收,因为考虑到预期停顿时间,所以只会回收接近 于这个时间的region,剩余的region等待下⼀轮GC进⾏回 收
常用参数
一些常用的JVM参数,用于调整垃圾收集器的行为:
选择垃圾收集器:
-XX:+UseSerialGC:选择串行收集器,适用于单核处理器或小型应用。
-XX:+UseParallelGC:选择Parallel GC,适用于多核处理器的新生代收集。
-XX:+UseConcMarkSweepGC:使用CMS GC进行老年代收集,与Parallel GC配合使用。
-XX:+UseG1GC:使用G1 GC,适用于大堆内存和需要低延迟的应用。
-XX:+UseZGC:使用Z Garbage Collector,适用于需要极低停顿时间的场景。其中,-XX:+UseConcMarkSweepGC 命令中,老年代使用 的是 CMS GC与Serial Old GC的收集器组合,Serial Old 会作为 CMS GC的后备收集器,当 CMS 挂了后顶上。
设置堆大小:
-Xms<size>:设置JVM启动时的初始堆内存大小。
-Xmx<size>:设置JVM最大堆内存大小。设置新生代大小:
-Xmn<size>:设置新生代的大小。设置Eden区与Survivor区的比例:
-XX:SurvivorRatio=<ratio>:设置Survivor区与Eden区的比例。设置老年代占堆内存的最大比例:
-XX:OldPLABSizePercent=<percent>:设置老年代并行垃圾回收时的PLAB(Promotion Local Allocation Buffer)区域占堆内存的百分比。设置GC日志参数:
-Xlog:gc:开启GC日志记录。
-Xlog:gc:记录所有GC的详细信息。设置CMS GC参数:
-XX:+UseCMSInitiatingOccupancyOnly:设置CMS启动的内存占用阈值。
-XX:CMSInitiatingOccupancyFraction=<percent>:设置老年代使用到达一定比例时触发CMS。设置G1 GC参数:
-XX:G1HeapRegionSize=<region-size>:设置G1的Region大小。
-XX:MaxGCPauseMillis=<time>:设置G1最大GC停顿时间目标。设置ZGC参数:
-XX:ZSize=<size>:设置ZGC的Z-Heap大小。堆外内存设置:
-XX:MaxDirectMemorySize=<size>:设置直接内存(堆外内存)的最大值。垃圾收集器的并行线程数:
-XX:ParallelGCThreads=<number-of-threads>:设置Parallel GC使用的线程数。
-XX:ConcGCThreads=<number-of-threads>:设置CMS的并发标记线程数。软引用和弱引用的设置:
-XX:SoftRefLRUPolicyMSPerMB=<millis-per-mb>:设置软引用对象在每MB堆内存中存活的最长时间。
-XX:+DisableExplicitGC:禁用System.gc()调用。元空间(Metaspace)设置:
-XX:MetaspaceSize=<size>:设置类元数据区域的初始大小。
-XX:MaxMetaspaceSize=<size>:设置类元数据区域的最大大小。堆Dump和分析:
-XX:+HeapDumpOnOutOfMemoryError:当发生OOM时,生成堆转储。
-XX:HeapDumpPath=<directory>:设置堆转储文件的路径。这些参数可以根据应用程序的具体需求进行调整。在生产环境中,建议进行充分的测试,以确保所选设置不会对性能产生负面影响。此外,随着JDK版本的更新,某些参数可能会被弃用或替换,因此需要查阅对应版本的官方文档以获取最新的信息。
JVM 调优
参考:
一般面试的时候,会说一下背景
工具可以说是内部的监控的工具,然后看到这个现象。
参考说辞
现象
- 晚上8点是我们的业务高峰,一到高峰的时候,发现TP99耗时会变高,有明显的毛刺,通过排查发现内存使用率也会增大,然后再释放,其他各项指标正常,于是怀疑是GC导致的,观察服务器的GC情况,发现 youngGC 情况如下,大概每5分钟,GC55次,峰值最高可以达到 220 次。 FullGC 比较频繁,每5分钟大慨0.5次,峰值8次。
- 那么问题在于 Fullgc 频繁,而且 youngGC 峰值也很高。
原因分析
- FullGC频繁,那么会触发 stop the world。此时会导致我们的系统进行停顿,这个可能是导致我们的系统 tp99 耗时上升的主要原因。由于并发很高,我们的 YoungGc 频繁,那么可能会造成,我们有些本应该在YoungGC就回收的对象,没有回收成功,直接进入了老年代,由于对象的晋升,导致了我们的老年代继续触发 FullGC。于是峰值变高。
优化目标
- 1、Young GC 次数减少
- 2、Young GC 耗时减少
- 3、FullGC 不超过 6 次一天
- 4、FullGC 耗时减少
优化思路
- 1、先看垃圾收集器
- 我们的 jdk 版本为8,并且这个服务未指定特定的收集器,所以走的是我们默认的收集器组台,年轻代为 Parallel Scavenge,老年代为 Parallel Old。
- 这两种并行收集器的组台提高了系统的吞吐量,而不是低延迟配北
- 我们首先应该换一个低延迟的收集器。低延迟的组合,我们选择 ParNew 与 CMS 的组台,如果 Jdk 的版本高,其实也可以选择 GI 或者 ZGC 。
- 2、年轻代参数设置
- -Xms4096M -Xmx4096M -Xmn1024M,以上的配置只配堆的大小,
- 像我们年轻代的占比都是走的默认的,-XX:SurvivorRatio=8,,也就是4G * 0.2。总共 0.8 G。
- 这个就比较小了,观察了一下老年代的对象占用空间,大概是1.5g, 也就是说有一些堆空间其实是空闲的。那么当我们年轻代的空间小,而且并发大的时候,年轻代的对象会激增,并且晋升到老年代。然而收集器Parallel Old 又会导致stw,无法与用户线程并行,那么就会造成我们的服务停顿,TP99升高。
- 3、元数据区
- jdk 1.8 后,原来的永久代变为元数据区,如果我们没有指定元数据区的大小。其默认的初始值只有21 M,
- 那么我们如果是动态代理的对象比较多,就会导致我们的元数据区进行 GC 回收,元数据区的回收也会触发 Full GC,
- 再次导致我们的 stw。所以我们观看了一下元数据的常驻对象的大小,大概是 1 00M 左右,所以我们直接用参数指定元数据区的大小为 256 M。我们的元数据区的最大容量也同时指定为256M, 防止其进行动态调整。
- 4、并发预处理
- 在Full GC发生时,会产生我们的 GCroot 追踪。老年代与年轻代之间又会存在跨年龄引用,如果我们在CMS收集器进行收集之前,进行一次重新标记,其实会减少我们的对象扫描,减少我们的 Full GC 时间。所以我们就让进行FullGC之前,强制做一次MinorGC。我们配置如下参数XX:+CMSScavengeBeforeRemark,这样就减少了我们要扫描的对象,减少了Remart时间。
最终方案

相关引申
- TP99
- TP99是指一组数据
从小到大排列,处于99%位置的数据的值。 在工程性能指标中,TP99可以用来表示满足百分之九十九的网络请求所需的最低耗时。 - 比如我调用别人的一个方法函数,1小时内调用了1w次,监控中显示tp99是200ms,这个意思就是: 百分之99%的调用,都可以在200ms内返回结果。
- TP99是指一组数据